 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Protein-Protein Interactions -- A Short Survey
Apr 16, 2024Protein-protein interactions (PPIs) play key roles in a broad range of biological processes. Numerous strategies have been proposed for predicting PPIs, and among them, graph-based methods have demonstrated promising outcomes owing to the inherent graph structure of PPI networks. This paper reviews various graph-based methodologies, and discusses their applications in PPI prediction. We classify these approaches into two primary groups based on their model structures. The first category employs Graph Neural Networks (GNN) or Graph Convolutional Networks (GCN), while the second category utilizes Graph Attention Networks (GAT), Graph Auto-Encoders and Graph-BERT. We highlight the distinctive methodologies of each approach in managing the graph-structured data inherent in PPI networks and anticipate future research directions in this domain.
SemiGNN-PPI: Self-Ensembling Multi-Graph Neural Network for Efficient and Generalizable Protein-Protein Interaction Prediction
May 15, 2023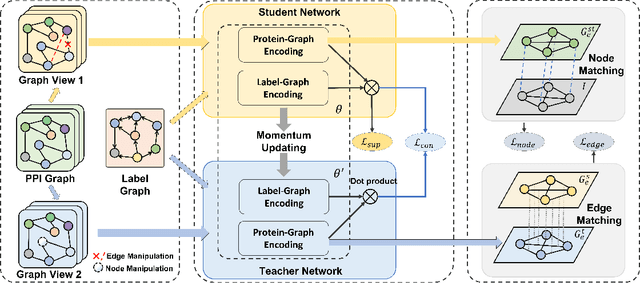
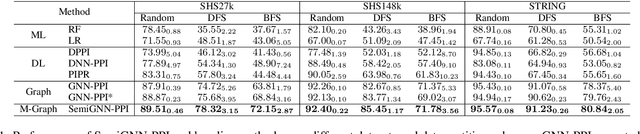
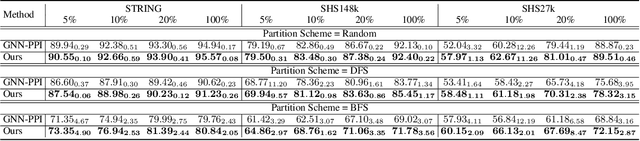
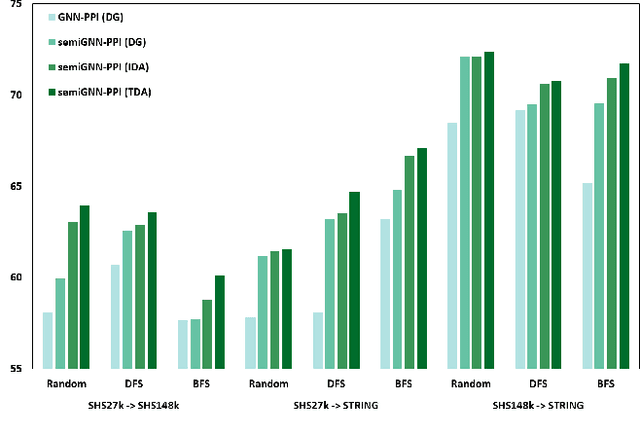
Protein-protein interactions (PPIs) are crucial in various biological processes and their study has significant implications for drug development and disease diagnosis. Existing deep learning methods suffer from significant performance degradation under complex real-world scenarios due to various factors, e.g., label scarcity and domain shift. In this paper, we propose a self-ensembling multigraph neural network (SemiGNN-PPI) that can effectively predict PPIs while being both efficient and generalizable. In SemiGNN-PPI, we not only model the protein correlations but explore the label dependencies by constructing and processing multiple graphs from the perspectives of both features and labels in the graph learning process. We further marry GNN with Mean Teacher to effectively leverage unlabeled graph-structured PPI data for self-ensemble graph learning. We also design multiple graph consistency constraints to align the student and teacher graphs in the feature embedding space, enabling the student model to better learn from the teacher model by incorporating more relationships. Extensive experiments on PPI datasets of different scales with different evaluation settings demonstrate that SemiGNN-PPI outperforms state-of-the-art PPI prediction methods, particularly in challenging scenarios such as training with limited annotations and testing on unseen data.
DA-CIL: Towards Domain Adaptive Class-Incremental 3D Object Detection
Dec 05, 2022



Deep learning has achieved notable success in 3D object detection with the advent of large-scale point cloud datasets. However, severe performance degradation in the past trained classes, i.e., catastrophic forgetting, still remains a critical issue for real-world deployment when the number of classes is unknown or may vary. Moreover, existing 3D class-incremental detection methods are developed for the single-domain scenario, which fail when encountering domain shift caused by different datasets, varying environments, etc. In this paper, we identify the unexplored yet valuable scenario, i.e., class-incremental learning under domain shift, and propose a novel 3D domain adaptive class-incremental object detection framework, DA-CIL, in which we design a novel dual-domain copy-paste augmentation method to construct multiple augmented domains for diversifying training distributions, thereby facilitating gradual domain adaptation. Then, multi-level consistency is explored to facilitate dual-teacher knowledge distillation from different domains for domain adaptive class-incremental learning. Extensive experiments on various datasets demonstrate the effectiveness of the proposed method over baselines in the domain adaptive class-incremental learning scenario.
* Accepted by the 33rd British Machine Vision Conference (BMVC 2022)
MMGL: Multi-Scale Multi-View Global-Local Contrastive learning for Semi-supervised Cardiac Image Segmentation
Jul 05, 2022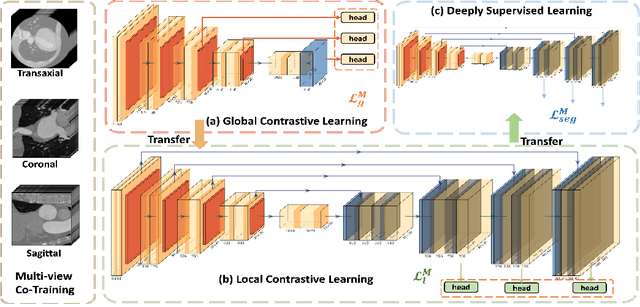

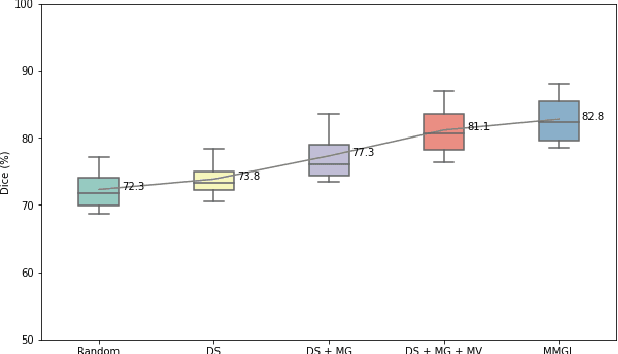
With large-scale well-labeled datasets, deep learning has shown significant success in medical image segmentation. However, it is challenging to acquire abundant annotations in clinical practice due to extensive expertise requirements and costly labeling efforts. Recently, contrastive learning has shown a strong capacity for visual representation learning on unlabeled data, achieving impressive performance rivaling supervised learning in many domains. In this work, we propose a novel multi-scale multi-view global-local contrastive learning (MMGL) framework to thoroughly explore global and local features from different scales and views for robust contrastive learning performance, thereby improving segmentation performance with limited annotations. Extensive experiments on the MM-WHS dataset demonstrate the effectiveness of MMGL framework on semi-supervised cardiac image segmentation, outperforming the state-of-the-art contrastive learning methods by a large margin.
Residual Channel Attention Network for Brain Glioma Segmentation
May 22, 2022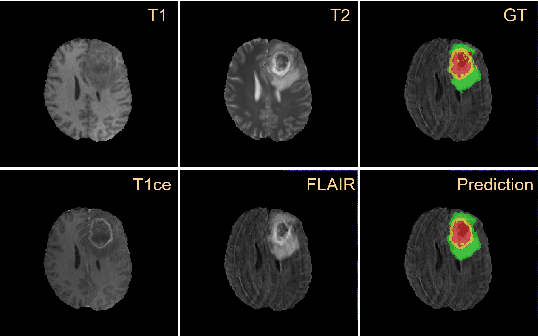
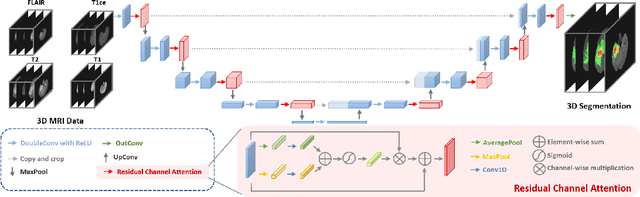
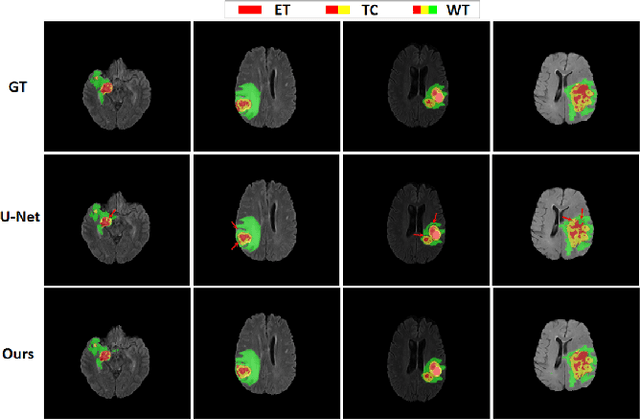

A glioma is a malignant brain tumor that seriously affects cognitive functions and lowers patients' life quality. Segmentation of brain glioma is challenging because of interclass ambiguities in tumor regions. Recently, deep learning approaches have achieved outstanding performance in the automatic segmentation of brain glioma. However, existing algorithms fail to exploit channel-wise feature interdependence to select semantic attributes for glioma segmentation. In this study, we implement a novel deep neural network that integrates residual channel attention modules to calibrate intermediate features for glioma segmentation. The proposed channel attention mechanism adaptively weights feature channel-wise to optimize the latent representation of gliomas. We evaluate our method on the established dataset BraTS2017. Experimental results indicate the superiority of our method.
Deep Feature Fusion via Graph Convolutional Network for Intracranial Artery Labeling
May 22, 2022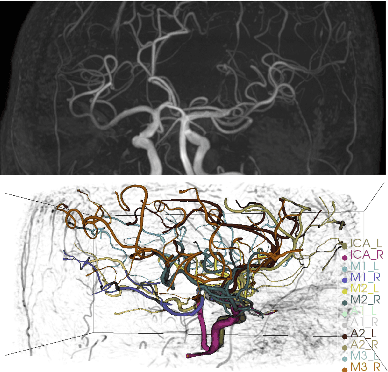
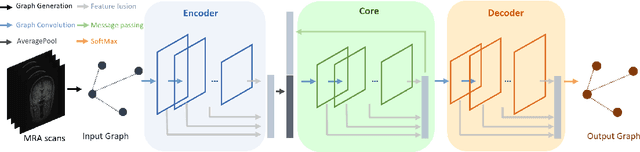


Intracranial arteries are critical blood vessels that supply the brain with oxygenated blood. Intracranial artery labels provide valuable guidance and navigation to numerous clinical applications and disease diagnoses. Various machine learning algorithms have been carried out for automation in the anatomical labeling of cerebral arteries. However, the task remains challenging because of the high complexity and variations of intracranial arteries. This study investigates a novel graph convolutional neural network with deep feature fusion for cerebral artery labeling. We introduce stacked graph convolutions in an encoder-core-decoder architecture, extracting high-level representations from graph nodes and their neighbors. Furthermore, we efficiently aggregate intermediate features from different hierarchies to enhance the proposed model's representation capability and labeling performance. We perform extensive experiments on public datasets, in which the results prove the superiority of our approach over baselines by a clear margin.
Adaptive Mean-Residue Loss for Robust Facial Age Estimation
Mar 31, 2022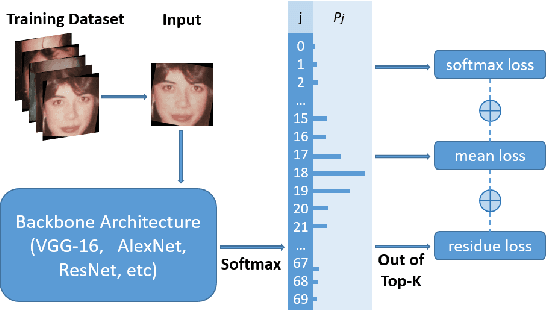
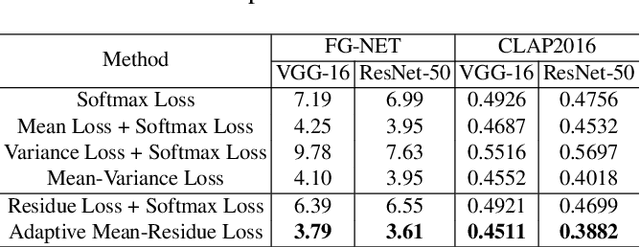
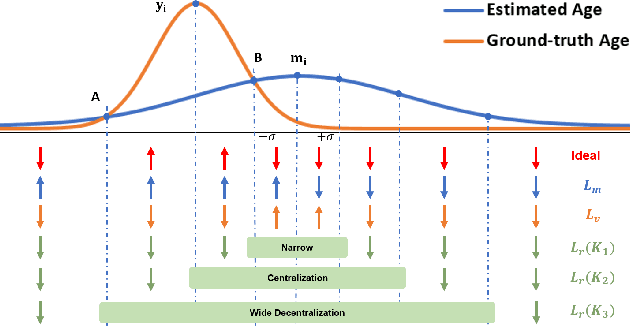
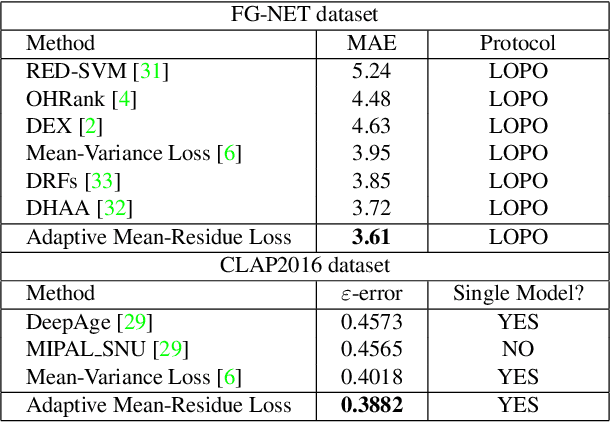
Automated facial age estimation has diverse real-world applications in multimedia analysis, e.g., video surveillance, and human-computer interaction. However, due to the randomness and ambiguity of the aging process, age assessment is challenging. Most research work over the topic regards the task as one of age regression, classification, and ranking problems, and cannot well leverage age distribution in representing labels with age ambiguity. In this work, we propose a simple yet effective loss function for robust facial age estimation via distribution learning, i.e., adaptive mean-residue loss, in which, the mean loss penalizes the difference between the estimated age distribution's mean and the ground-truth age, whereas the residue loss penalizes the entropy of age probability out of dynamic top-K in the distribution. Experimental results in the datasets FG-NET and CLAP2016 have validated the effectiveness of the proposed loss. Our code is available at https://github.com/jacobzhaoziyuan/AMR-Loss.
Two Eyes Are Better Than One: Exploiting Binocular Correlation for Diabetic Retinopathy Severity Grading
Aug 15, 2021
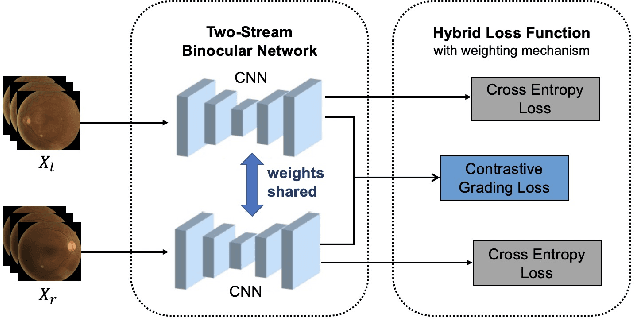
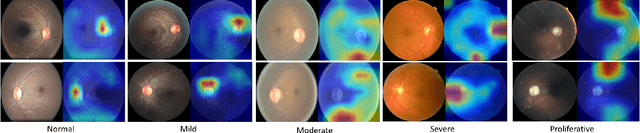
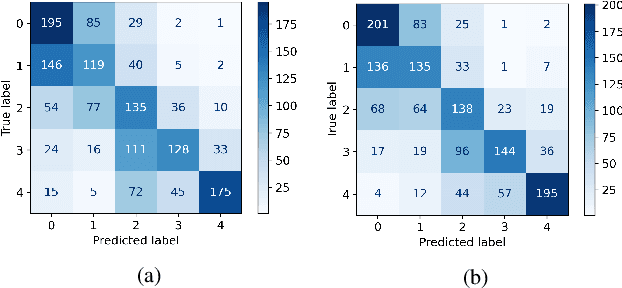
Diabetic retinopathy (DR) is one of the most common eye conditions among diabetic patients. However, vision loss occurs primarily in the late stages of DR, and the symptoms of visual impairment, ranging from mild to severe, can vary greatly, adding to the burden of diagnosis and treatment in clinical practice. Deep learning methods based on retinal images have achieved remarkable success in automatic DR grading, but most of them neglect that the presence of diabetes usually affects both eyes, and ophthalmologists usually compare both eyes concurrently for DR diagnosis, leaving correlations between left and right eyes unexploited. In this study, simulating the diagnostic process, we propose a two-stream binocular network to capture the subtle correlations between left and right eyes, in which, paired images of eyes are fed into two identical subnetworks separately during training. We design a contrastive grading loss to learn binocular correlation for five-class DR detection, which maximizes inter-class dissimilarity while minimizing the intra-class difference. Experimental results on the EyePACS dataset show the superiority of the proposed binocular model, outperforming monocular methods by a large margin.
Multi-Target Deep Learning for Algal Detection and Classification
May 07, 2020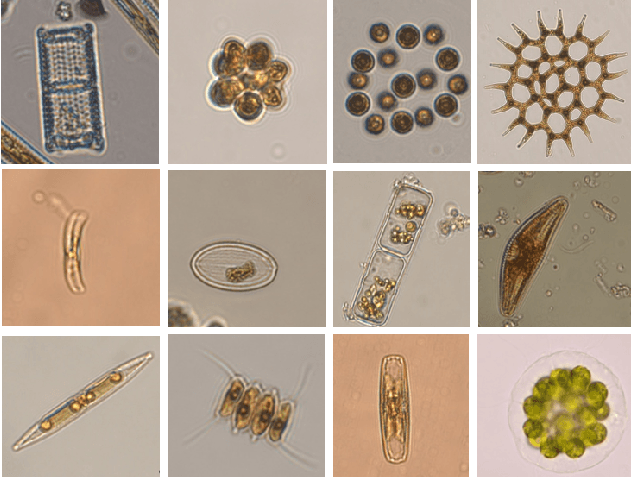
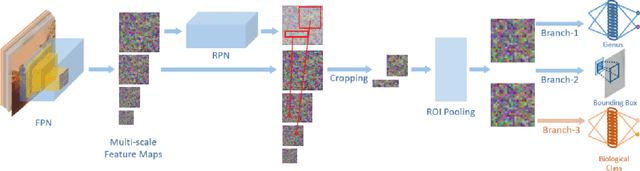
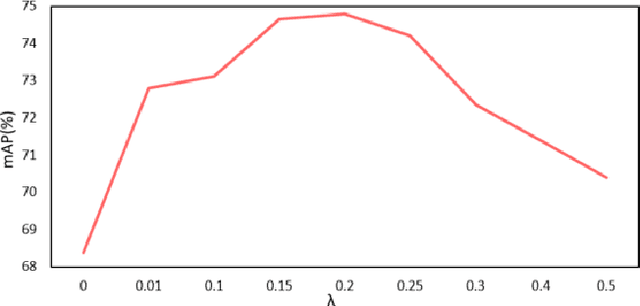
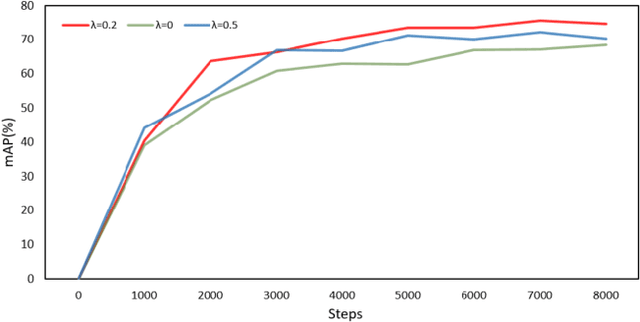
Water quality has a direct impact on industry, agriculture, and public health. Algae species are common indicators of water quality. It is because algal communities are sensitive to changes in their habitats, giving valuable knowledge on variations in water quality. However, water quality analysis requires professional inspection of algal detection and classification under microscopes, which is very time-consuming and tedious. In this paper, we propose a novel multi-target deep learning framework for algal detection and classification. Extensive experiments were carried out on a large-scale colored microscopic algal dataset. Experimental results demonstrate that the proposed method leads to the promising performance on algal detection, class identification and genus identification.