 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
Feb 04, 2026Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text--motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps.We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change.Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.
SWiT-4D: Sliding-Window Transformer for Lossless and Parameter-Free Temporal 4D Generation
Dec 11, 2025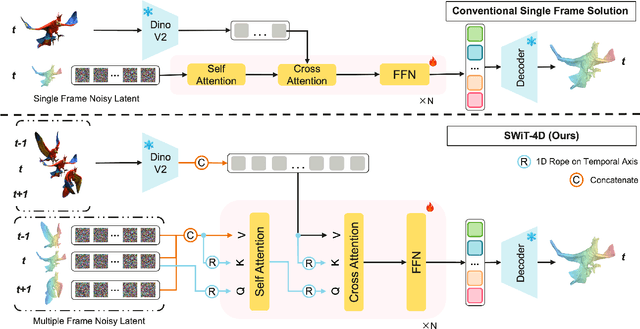
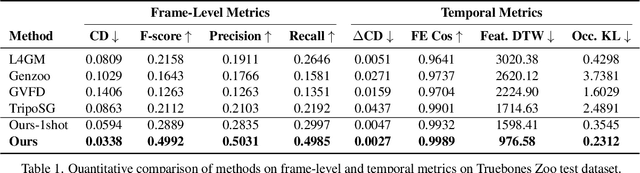
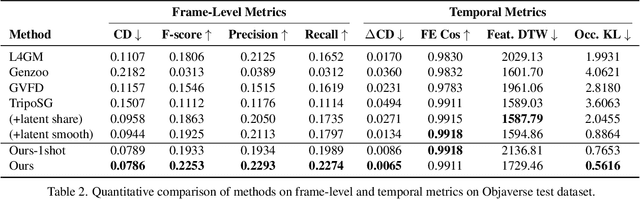

Despite significant progress in 4D content generation, the conversion of monocular videos into high-quality animated 3D assets with explicit 4D meshes remains considerably challenging. The scarcity of large-scale, naturally captured 4D mesh datasets further limits the ability to train generalizable video-to-4D models from scratch in a purely data-driven manner. Meanwhile, advances in image-to-3D generation, supported by extensive datasets, offer powerful prior models that can be leveraged. To better utilize these priors while minimizing reliance on 4D supervision, we introduce SWiT-4D, a Sliding-Window Transformer for lossless, parameter-free temporal 4D mesh generation. SWiT-4D integrates seamlessly with any Diffusion Transformer (DiT)-based image-to-3D generator, adding spatial-temporal modeling across video frames while preserving the original single-image forward process, enabling 4D mesh reconstruction from videos of arbitrary length. To recover global translation, we further introduce an optimization-based trajectory module tailored for static-camera monocular videos. SWiT-4D demonstrates strong data efficiency: with only a single short (<10s) video for fine-tuning, it achieves high-fidelity geometry and stable temporal consistency, indicating practical deployability under extremely limited 4D supervision. Comprehensive experiments on both in-domain zoo-test sets and challenging out-of-domain benchmarks (C4D, Objaverse, and in-the-wild videos) show that SWiT-4D consistently outperforms existing baselines in temporal smoothness. Project page: https://animotionlab.github.io/SWIT4D/
MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Dec 11, 2025Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/
DA-CIL: Towards Domain Adaptive Class-Incremental 3D Object Detection
Dec 05, 2022



Deep learning has achieved notable success in 3D object detection with the advent of large-scale point cloud datasets. However, severe performance degradation in the past trained classes, i.e., catastrophic forgetting, still remains a critical issue for real-world deployment when the number of classes is unknown or may vary. Moreover, existing 3D class-incremental detection methods are developed for the single-domain scenario, which fail when encountering domain shift caused by different datasets, varying environments, etc. In this paper, we identify the unexplored yet valuable scenario, i.e., class-incremental learning under domain shift, and propose a novel 3D domain adaptive class-incremental object detection framework, DA-CIL, in which we design a novel dual-domain copy-paste augmentation method to construct multiple augmented domains for diversifying training distributions, thereby facilitating gradual domain adaptation. Then, multi-level consistency is explored to facilitate dual-teacher knowledge distillation from different domains for domain adaptive class-incremental learning. Extensive experiments on various datasets demonstrate the effectiveness of the proposed method over baselines in the domain adaptive class-incremental learning scenario.
* Accepted by the 33rd British Machine Vision Conference (BMVC 2022)