 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICXML: An In-Context Learning Framework for Zero-Shot Extreme Multi-Label Classification
Nov 16, 2023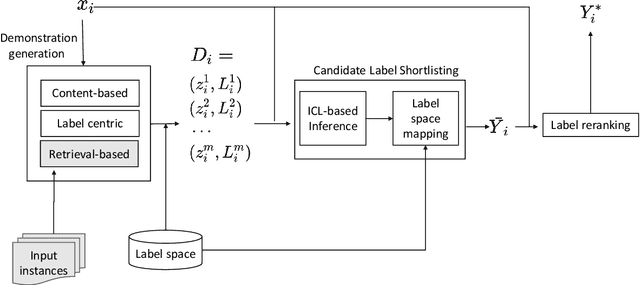
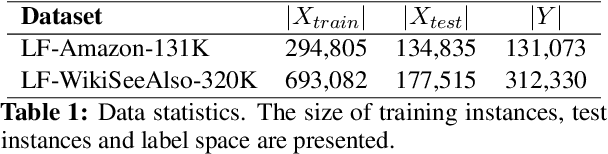
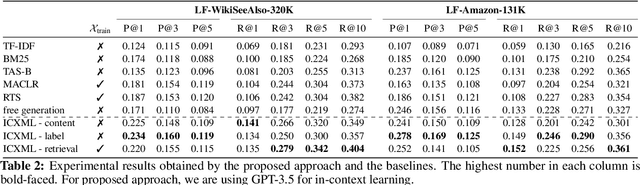
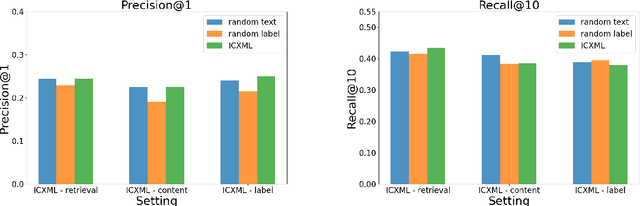
This paper focuses on the task of Extreme Multi-Label Classification (XMC) whose goal is to predict multiple labels for each instance from an extremely large label space. While existing research has primarily focused on fully supervised XMC, real-world scenarios often lack complete supervision signals, highlighting the importance of zero-shot settings. Given the large label space, utilizing in-context learning approaches is not trivial. We address this issue by introducing In-Context Extreme Multilabel Learning (ICXML), a two-stage framework that cuts down the search space by generating a set of candidate labels through incontext learning and then reranks them. Extensive experiments suggest that ICXML advances the state of the art on two diverse public benchmarks.
Deep Feature Fusion via Graph Convolutional Network for Intracranial Artery Labeling
May 22, 2022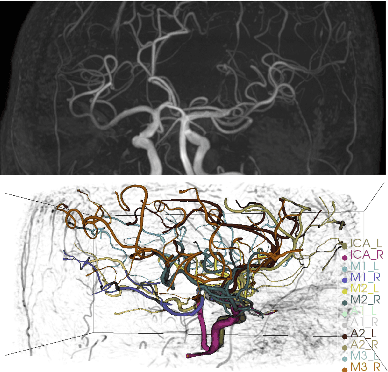
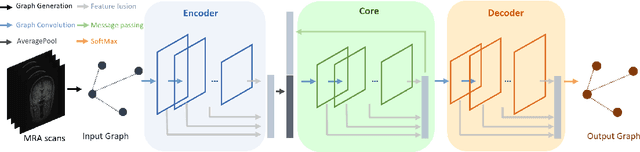


Intracranial arteries are critical blood vessels that supply the brain with oxygenated blood. Intracranial artery labels provide valuable guidance and navigation to numerous clinical applications and disease diagnoses. Various machine learning algorithms have been carried out for automation in the anatomical labeling of cerebral arteries. However, the task remains challenging because of the high complexity and variations of intracranial arteries. This study investigates a novel graph convolutional neural network with deep feature fusion for cerebral artery labeling. We introduce stacked graph convolutions in an encoder-core-decoder architecture, extracting high-level representations from graph nodes and their neighbors. Furthermore, we efficiently aggregate intermediate features from different hierarchies to enhance the proposed model's representation capability and labeling performance. We perform extensive experiments on public datasets, in which the results prove the superiority of our approach over baselines by a clear margin.
Faithfully Explainable Recommendation via Neural Logic Reasoning
Apr 16, 2021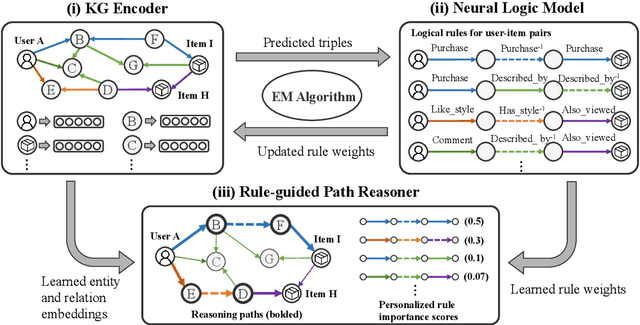
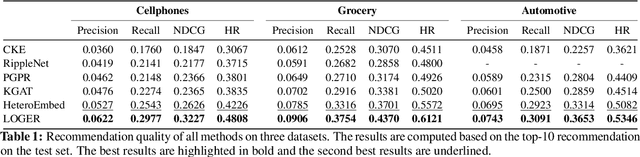
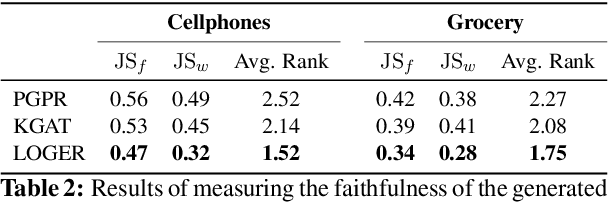
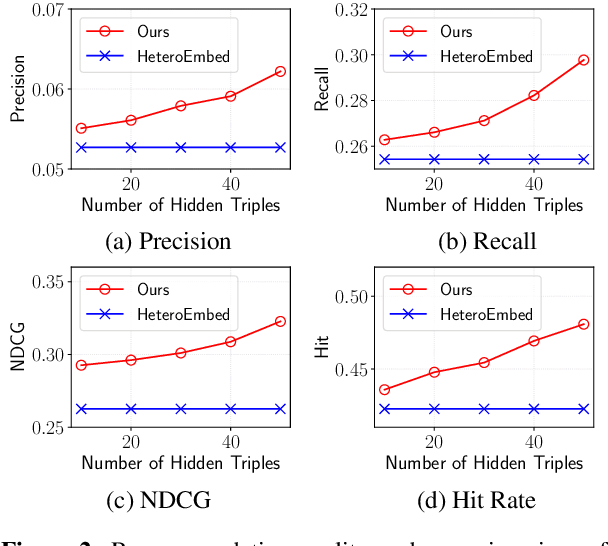
Knowledge graphs (KG) have become increasingly important to endow modern recommender systems with the ability to generate traceable reasoning paths to explain the recommendation process. However, prior research rarely considers the faithfulness of the derived explanations to justify the decision making process. To the best of our knowledge, this is the first work that models and evaluates faithfully explainable recommendation under the framework of KG reasoning. Specifically, we propose neural logic reasoning for explainable recommendation (LOGER) by drawing on interpretable logical rules to guide the path reasoning process for explanation generation. We experiment on three large-scale datasets in the e-commerce domain, demonstrating the effectiveness of our method in delivering high-quality recommendations as well as ascertaining the faithfulness of the derived explanation.
COOKIE: A Dataset for Conversational Recommendation over Knowledge Graphs in E-commerce
Aug 21, 2020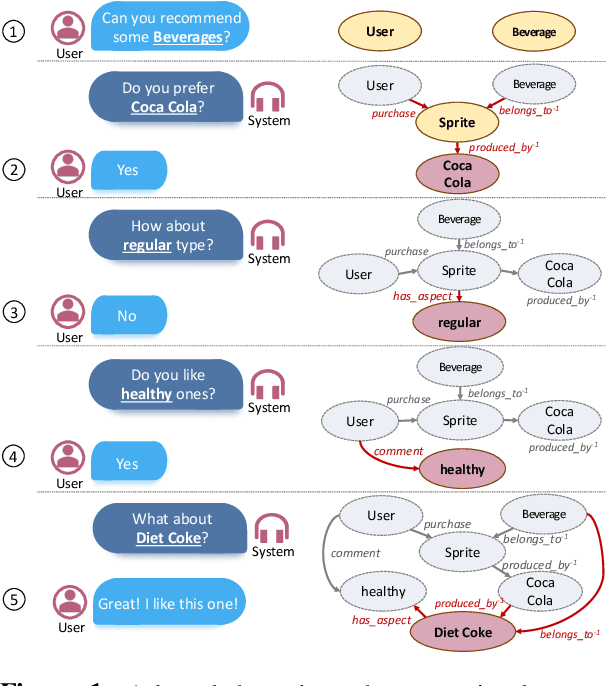
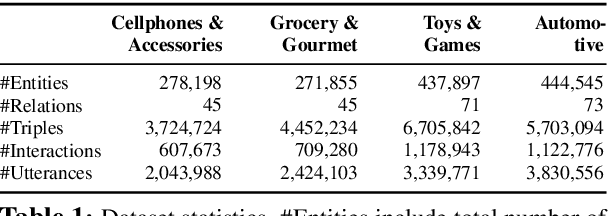
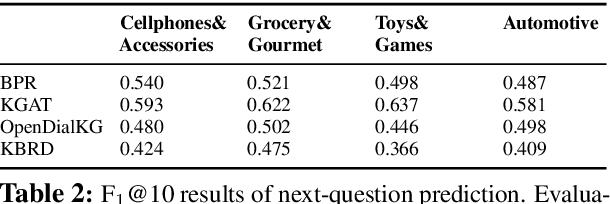
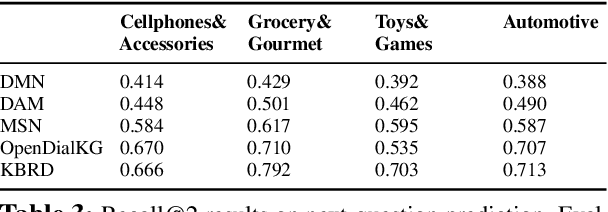
In this work, we present a new dataset for conversational recommendation over knowledge graphs in e-commerce platforms called COOKIE. The dataset is constructed from an Amazon review corpus by integrating both user-agent dialogue and custom knowledge graphs for recommendation. Specifically, we first construct a unified knowledge graph and extract key entities between user--product pairs, which serve as the skeleton of a conversation. Then we simulate conversations mirroring the human coarse-to-fine process of choosing preferred items. The proposed baselines and experiments demonstrate that our dataset is able to provide innovative opportunities for conversational recommendation.
Leveraging Adversarial Training in Self-Learning for Cross-Lingual Text Classification
Jul 29, 2020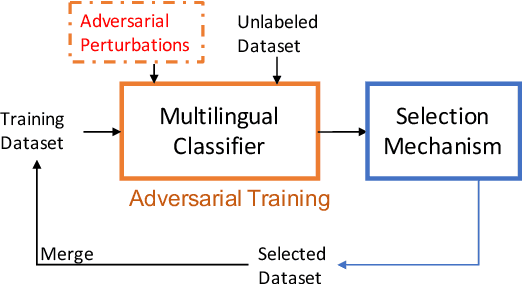
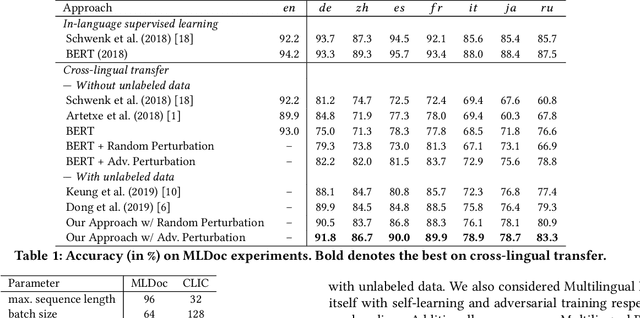
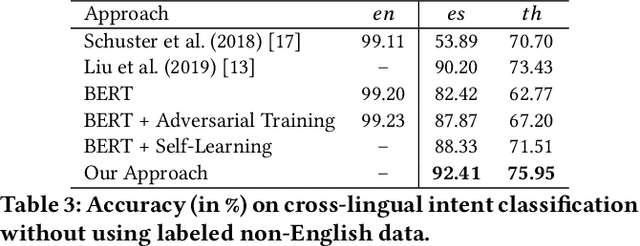
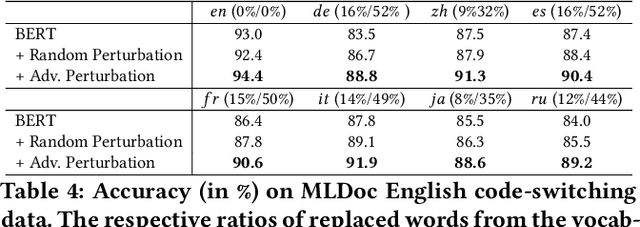
In cross-lingual text classification, one seeks to exploit labeled data from one language to train a text classification model that can then be applied to a completely different language. Recent multilingual representation models have made it much easier to achieve this. Still, there may still be subtle differences between languages that are neglected when doing so. To address this, we present a semi-supervised adversarial training process that minimizes the maximal loss for label-preserving input perturbations. The resulting model then serves as a teacher to induce labels for unlabeled target language samples that can be used during further adversarial training, allowing us to gradually adapt our model to the target language. Compared with a number of strong baselines, we observe significant gains in effectiveness on document and intent classification for a diverse set of languages.