 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom NeRFLiX to NeRFLiX++: A General NeRF-Agnostic Restorer Paradigm
Jun 10, 2023Neural radiance fields (NeRF) have shown great success in novel view synthesis. However, recovering high-quality details from real-world scenes is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise and blur. To address this, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm that learns a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that fuses highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views. Based on this paradigm, we further present NeRFLiX++ with a stronger two-stage NeRF degradation simulator and a faster inter-viewpoint mixer, achieving superior performance with significantly improved computational efficiency. Notably, NeRFLiX++ is capable of restoring photo-realistic ultra-high-resolution outputs from noisy low-resolution NeRF-rendered views. Extensive experiments demonstrate the excellent restoration ability of NeRFLiX++ on various novel view synthesis benchmarks.
NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
Mar 22, 2023Neural radiance fields (NeRF) show great success in novel view synthesis. However, in real-world scenes, recovering high-quality details from the source images is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise, blur, etc. Towards to improve the synthesis quality of NeRF-based approaches, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm by learning a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for existing deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that is able to fuse highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views.
CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference Frame
Mar 06, 2023Various recent methods attempt to implement rotation-invariant 3D deep learning by replacing the input coordinates of points with relative distances and angles. Due to the incompleteness of these low-level features, they have to undertake the expense of losing global information. In this paper, we propose the CRIN, namely Centrifugal Rotation-Invariant Network. CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames. Aided by centrifugal reference frames, each point corresponds to a discrete rotation so that the information of rotations can be implicitly stored in point features. Unfortunately, discrete points are far from describing the whole rotation space. We further introduce a continuous distribution for 3D rotations based on points. Furthermore, we propose an attention-based down-sampling strategy to sample points invariant to rotations. A relation module is adopted at last for reinforcing the long-range dependencies between sampled points and predicts the anchor point for unsupervised rotation estimation. Extensive experiments show that our method achieves rotation invariance, accurately estimates the object rotation, and obtains state-of-the-art results on rotation-augmented classification and part segmentation. Ablation studies validate the effectiveness of the network design.
PVDD: A Practical Video Denoising Dataset with Real-World Dynamic Scenes
Jul 04, 2022


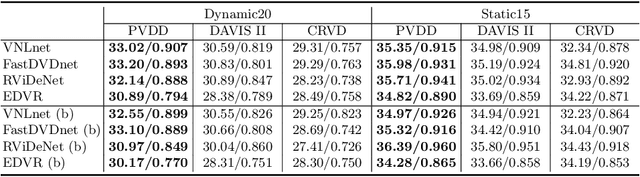
To facilitate video denoising research, we construct a compelling dataset, namely, "Practical Video Denoising Dataset" (PVDD), containing 200 noisy-clean dynamic video pairs in both sRGB and RAW format. Compared with existing datasets consisting of limited motion information, PVDD covers dynamic scenes with varying and natural motion. Different from datasets using primary Gaussian or Poisson distributions to synthesize noise in the sRGB domain, PVDD synthesizes realistic noise from the RAW domain with a physically meaningful sensor noise model followed by ISP processing. Moreover, based on this dataset, we propose a shuffle-based practical degradation model to enhance the performance of video denoising networks on real-world sRGB videos. Extensive experiments demonstrate that models trained on PVDD achieve superior denoising performance on many challenging real-world videos than on models trained on other existing datasets.
LAPAR: Linearly-Assembled Pixel-Adaptive Regression Network for Single Image Super-Resolution and Beyond
May 21, 2021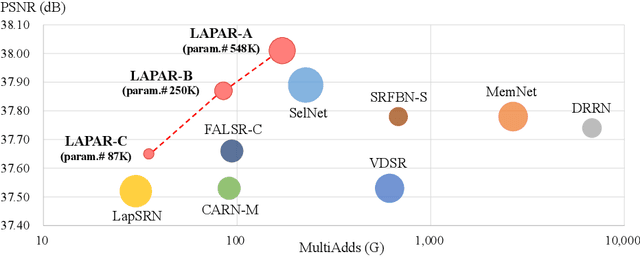
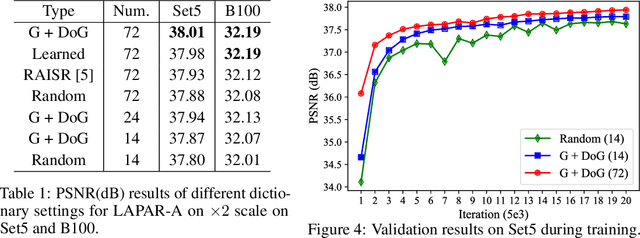
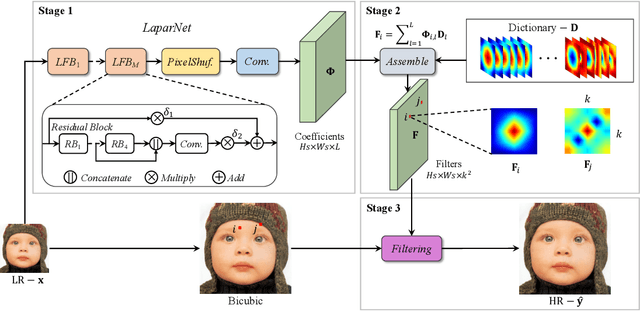
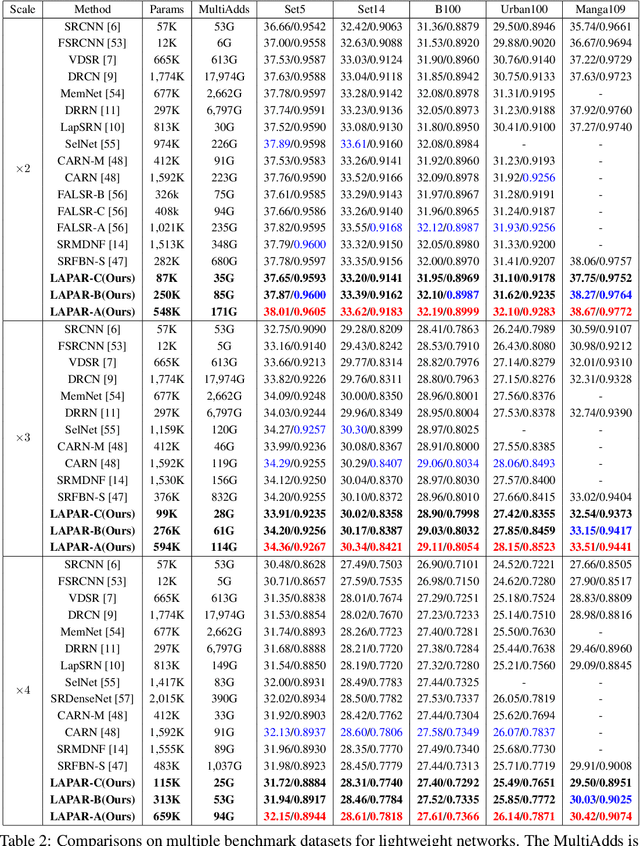
Single image super-resolution (SISR) deals with a fundamental problem of upsampling a low-resolution (LR) image to its high-resolution (HR) version. Last few years have witnessed impressive progress propelled by deep learning methods. However, one critical challenge faced by existing methods is to strike a sweet spot of deep model complexity and resulting SISR quality. This paper addresses this pain point by proposing a linearly-assembled pixel-adaptive regression network (LAPAR), which casts the direct LR to HR mapping learning into a linear coefficient regression task over a dictionary of multiple predefined filter bases. Such a parametric representation renders our model highly lightweight and easy to optimize while achieving state-of-the-art results on SISR benchmarks. Moreover, based on the same idea, LAPAR is extended to tackle other restoration tasks, e.g., image denoising and JPEG image deblocking, and again, yields strong performance. The code is available at https://github.com/dvlab-research/Simple-SR.
Best-Buddy GANs for Highly Detailed Image Super-Resolution
Mar 29, 2021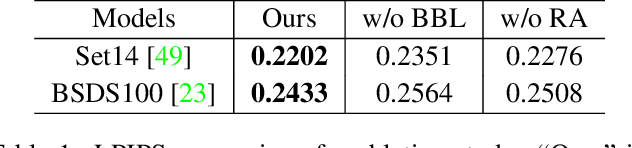


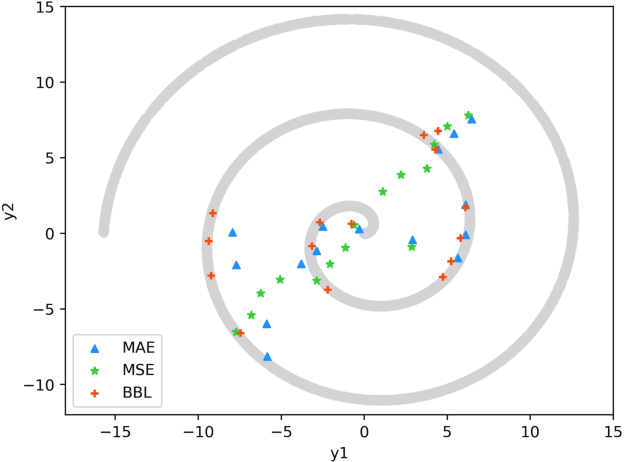
We consider the single image super-resolution (SISR) problem, where a high-resolution (HR) image is generated based on a low-resolution (LR) input. Recently, generative adversarial networks (GANs) become popular to hallucinate details. Most methods along this line rely on a predefined single-LR-single-HR mapping, which is not flexible enough for the SISR task. Also, GAN-generated fake details may often undermine the realism of the whole image. We address these issues by proposing best-buddy GANs (Beby-GAN) for rich-detail SISR. Relaxing the immutable one-to-one constraint, we allow the estimated patches to dynamically seek the best supervision during training, which is beneficial to producing more reasonable details. Besides, we propose a region-aware adversarial learning strategy that directs our model to focus on generating details for textured areas adaptively. Extensive experiments justify the effectiveness of our method. An ultra-high-resolution 4K dataset is also constructed to facilitate future super-resolution research.
JOLO-GCN: Mining Joint-Centered Light-Weight Information for Skeleton-Based Action Recognition
Nov 16, 2020
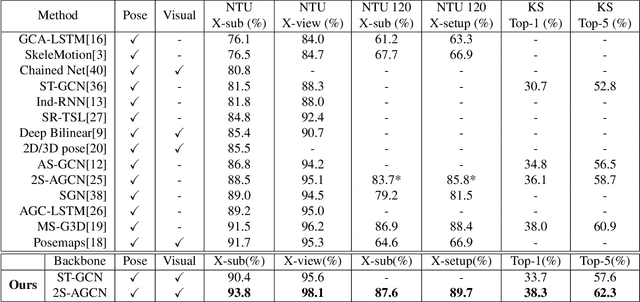
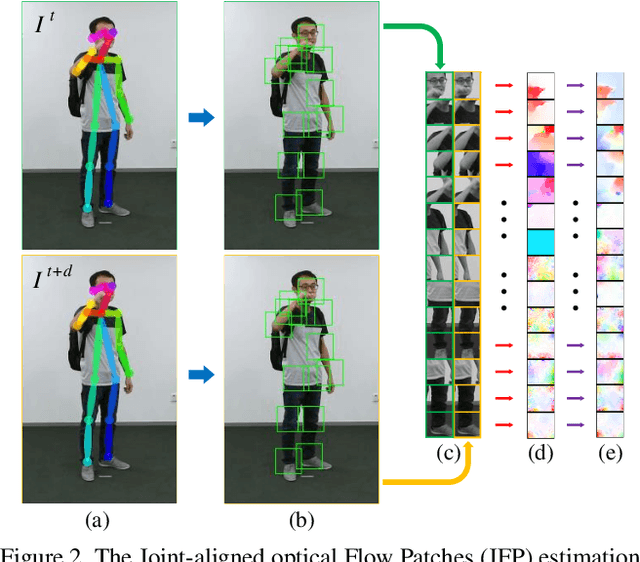

Skeleton-based action recognition has attracted research attentions in recent years. One common drawback in currently popular skeleton-based human action recognition methods is that the sparse skeleton information alone is not sufficient to fully characterize human motion. This limitation makes several existing methods incapable of correctly classifying action categories which exhibit only subtle motion differences. In this paper, we propose a novel framework for employing human pose skeleton and joint-centered light-weight information jointly in a two-stream graph convolutional network, namely, JOLO-GCN. Specifically, we use Joint-aligned optical Flow Patches (JFP) to capture the local subtle motion around each joint as the pivotal joint-centered visual information. Compared to the pure skeleton-based baseline, this hybrid scheme effectively boosts performance, while keeping the computational and memory overheads low. Experiments on the NTU RGB+D, NTU RGB+D 120, and the Kinetics-Skeleton dataset demonstrate clear accuracy improvements attained by the proposed method over the state-of-the-art skeleton-based methods.
A deep learning based interactive sketching system for fashion images design
Oct 09, 2020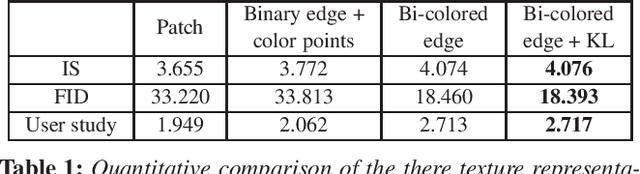
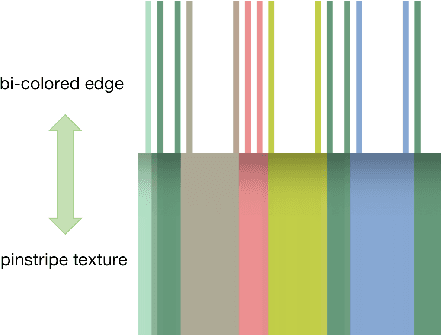
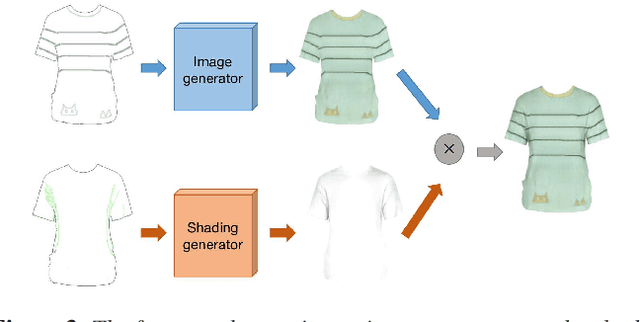

In this work, we propose an interactive system to design diverse high-quality garment images from fashion sketches and the texture information. The major challenge behind this system is to generate high-quality and detailed texture according to the user-provided texture information. Prior works mainly use the texture patch representation and try to map a small texture patch to a whole garment image, hence unable to generate high-quality details. In contrast, inspired by intrinsic image decomposition, we decompose this task into texture synthesis and shading enhancement. In particular, we propose a novel bi-colored edge texture representation to synthesize textured garment images and a shading enhancer to render shading based on the grayscale edges. The bi-colored edge representation provides simple but effective texture cues and color constraints, so that the details can be better reconstructed. Moreover, with the rendered shading, the synthesized garment image becomes more vivid.
HEMlets PoSh: Learning Part-Centric Heatmap Triplets for 3D Human Pose and Shape Estimation
Mar 10, 2020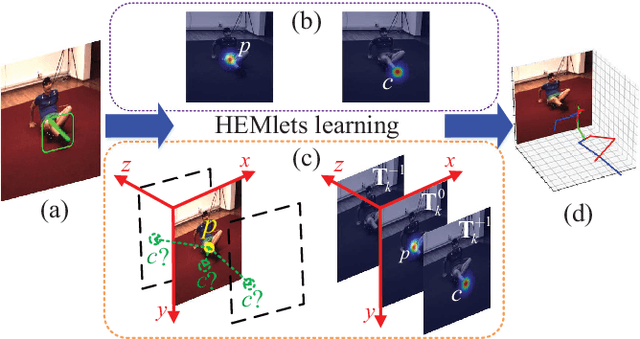
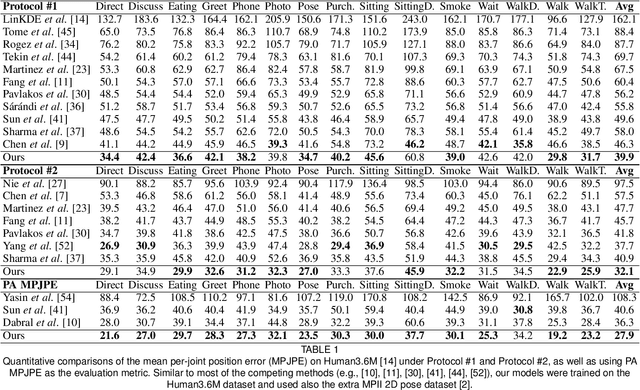
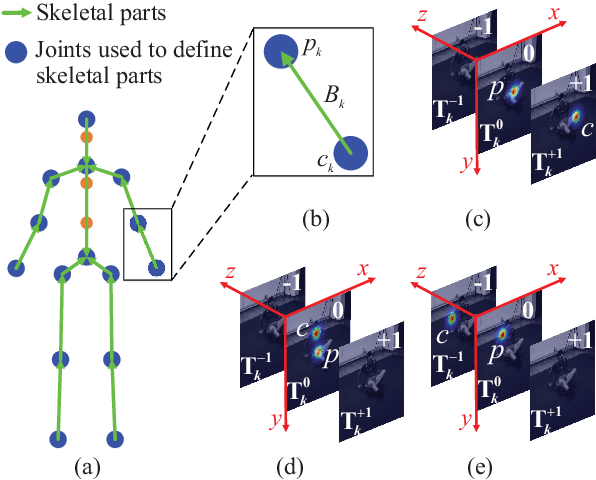
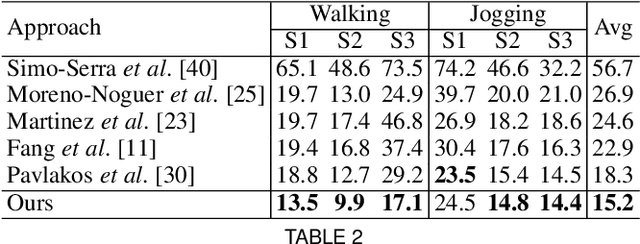
Estimating 3D human pose from a single image is a challenging task. This work attempts to address the uncertainty of lifting the detected 2D joints to the 3D space by introducing an intermediate state-Part-Centric Heatmap Triplets (HEMlets), which shortens the gap between the 2D observation and the 3D interpretation. The HEMlets utilize three joint-heatmaps to represent the relative depth information of the end-joints for each skeletal body part. In our approach, a Convolutional Network (ConvNet) is first trained to predict HEMlets from the input image, followed by a volumetric joint-heatmap regression. We leverage on the integral operation to extract the joint locations from the volumetric heatmaps, guaranteeing end-to-end learning. Despite the simplicity of the network design, the quantitative comparisons show a significant performance improvement over the best-of-grade methods (e.g. $20\%$ on Human3.6M). The proposed method naturally supports training with "in-the-wild" images, where only weakly-annotated relative depth information of skeletal joints is available. This further improves the generalization ability of our model, as validated by qualitative comparisons on outdoor images. Leveraging the strength of the HEMlets pose estimation, we further design and append a shallow yet effective network module to regress the SMPL parameters of the body pose and shape. We term the entire HEMlets-based human pose and shape recovery pipeline HEMlets PoSh. Extensive quantitative and qualitative experiments on the existing human body recovery benchmarks justify the state-of-the-art results obtained with our HEMlets PoSh approach.
HEMlets Pose: Learning Part-Centric Heatmap Triplets for Accurate 3D Human Pose Estimation
Oct 26, 2019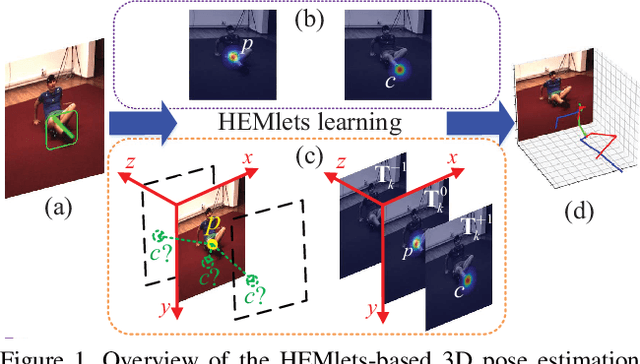

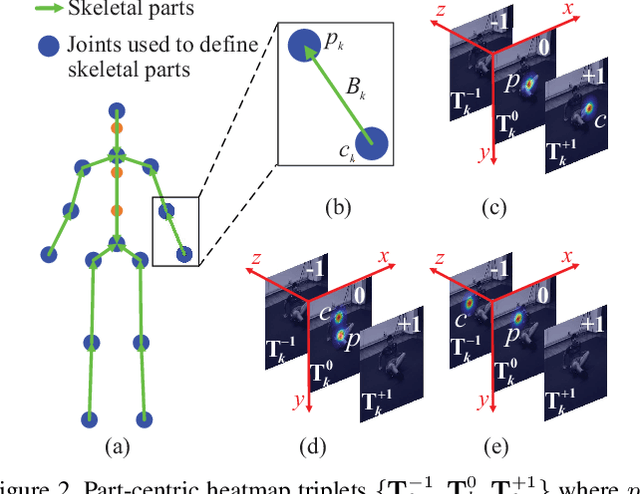

Estimating 3D human pose from a single image is a challenging task. This work attempts to address the uncertainty of lifting the detected 2D joints to the 3D space by introducing an intermediate state - Part-Centric Heatmap Triplets (HEMlets), which shortens the gap between the 2D observation and the 3D interpretation. The HEMlets utilize three joint-heatmaps to represent the relative depth information of the end-joints for each skeletal body part. In our approach, a Convolutional Network (ConvNet) is first trained to predict HEMlests from the input image, followed by a volumetric joint-heatmap regression. We leverage on the integral operation to extract the joint locations from the volumetric heatmaps, guaranteeing end-to-end learning. Despite the simplicity of the network design, the quantitative comparisons show a significant performance improvement over the best-of-grade method (by 20% on Human3.6M). The proposed method naturally supports training with "in-the-wild" images, where only weakly-annotated relative depth information of skeletal joints is available. This further improves the generalization ability of our model, as validated by qualitative comparisons on outdoor images.