 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEMlets PoSh: Learning Part-Centric Heatmap Triplets for 3D Human Pose and Shape Estimation
Paper and Code
Mar 10, 2020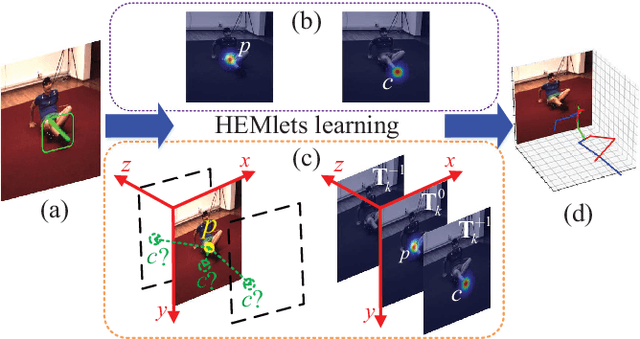
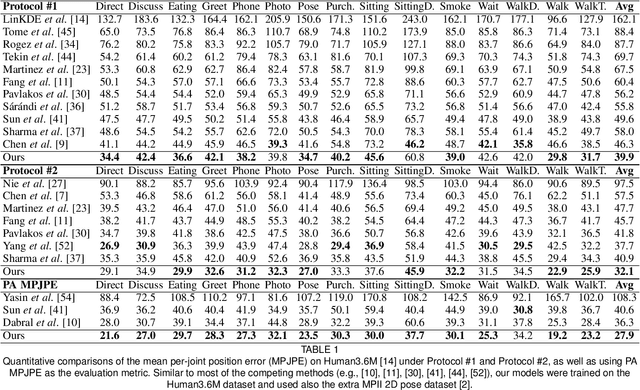
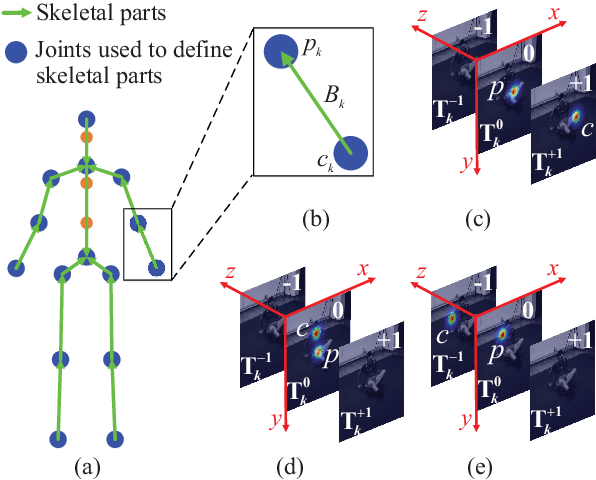
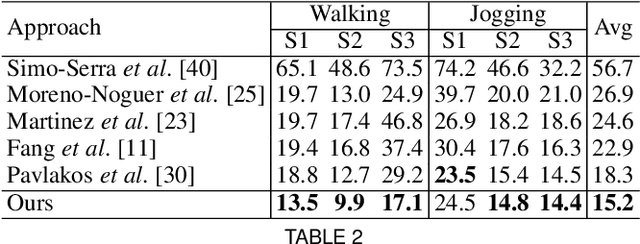
Estimating 3D human pose from a single image is a challenging task. This work attempts to address the uncertainty of lifting the detected 2D joints to the 3D space by introducing an intermediate state-Part-Centric Heatmap Triplets (HEMlets), which shortens the gap between the 2D observation and the 3D interpretation. The HEMlets utilize three joint-heatmaps to represent the relative depth information of the end-joints for each skeletal body part. In our approach, a Convolutional Network (ConvNet) is first trained to predict HEMlets from the input image, followed by a volumetric joint-heatmap regression. We leverage on the integral operation to extract the joint locations from the volumetric heatmaps, guaranteeing end-to-end learning. Despite the simplicity of the network design, the quantitative comparisons show a significant performance improvement over the best-of-grade methods (e.g. $20\%$ on Human3.6M). The proposed method naturally supports training with "in-the-wild" images, where only weakly-annotated relative depth information of skeletal joints is available. This further improves the generalization ability of our model, as validated by qualitative comparisons on outdoor images. Leveraging the strength of the HEMlets pose estimation, we further design and append a shallow yet effective network module to regress the SMPL parameters of the body pose and shape. We term the entire HEMlets-based human pose and shape recovery pipeline HEMlets PoSh. Extensive quantitative and qualitative experiments on the existing human body recovery benchmarks justify the state-of-the-art results obtained with our HEMlets PoSh approach.