 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
May 08, 2025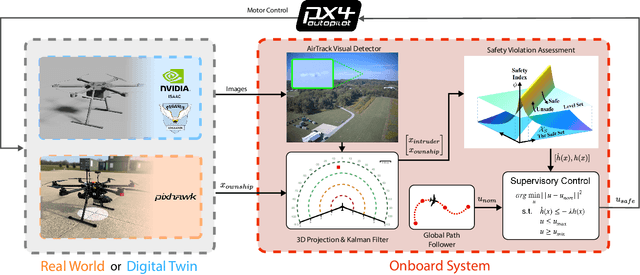
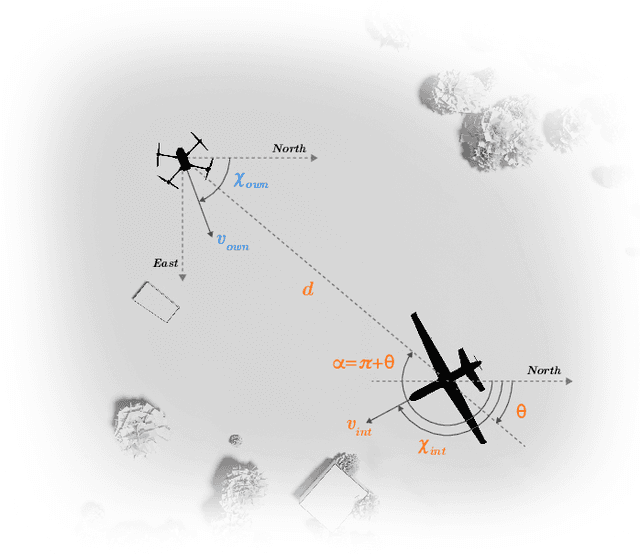

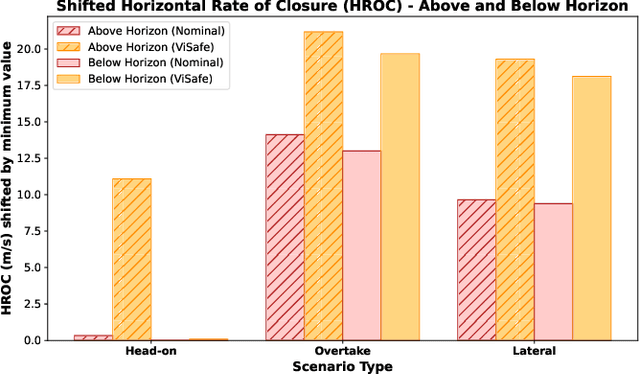
Assured safe-separation is essential for achieving seamless high-density operation of airborne vehicles in a shared airspace. To equip resource-constrained aerial systems with this safety-critical capability, we present ViSafe, a high-speed vision-only airborne collision avoidance system. ViSafe offers a full-stack solution to the Detect and Avoid (DAA) problem by tightly integrating a learning-based edge-AI framework with a custom multi-camera hardware prototype designed under SWaP-C constraints. By leveraging perceptual input-focused control barrier functions (CBF) to design, encode, and enforce safety thresholds, ViSafe can provide provably safe runtime guarantees for self-separation in high-speed aerial operations. We evaluate ViSafe's performance through an extensive test campaign involving both simulated digital twins and real-world flight scenarios. By independently varying agent types, closure rates, interaction geometries, and environmental conditions (e.g., weather and lighting), we demonstrate that ViSafe consistently ensures self-separation across diverse scenarios. In first-of-its-kind real-world high-speed collision avoidance tests with closure rates reaching 144 km/h, ViSafe sets a new benchmark for vision-only autonomous collision avoidance, establishing a new standard for safety in high-speed aerial navigation.
Amelia: A Large Model and Dataset for Airport Surface Movement Forecasting
Jul 30, 2024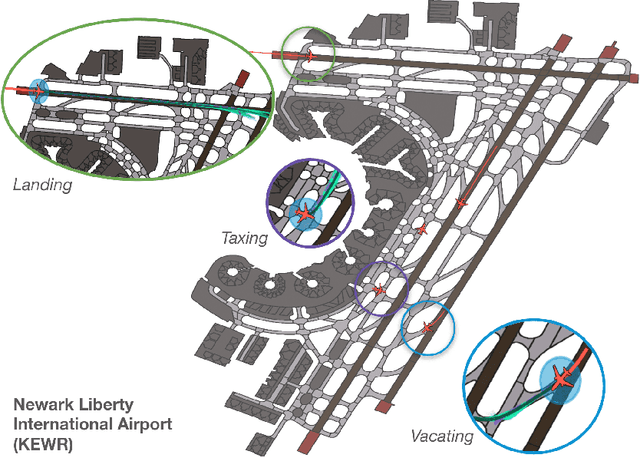

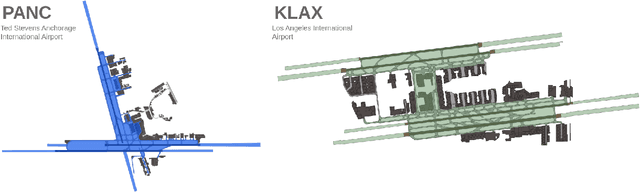
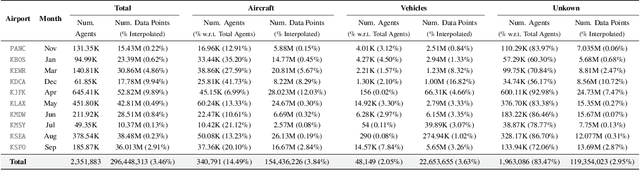
The growing demand for air travel requires technological advancements in air traffic management as well as mechanisms for monitoring and ensuring safe and efficient operations. In terminal airspaces, predictive models of future movements and traffic flows can help with proactive planning and efficient coordination; however, varying airport topologies, and interactions with other agents, among other factors, make accurate predictions challenging. Data-driven predictive models have shown promise for handling numerous variables to enable various downstream tasks, including collision risk assessment, taxi-out time prediction, departure metering, and emission estimations. While data-driven methods have shown improvements in these tasks, prior works lack large-scale curated surface movement datasets within the public domain and the development of generalizable trajectory forecasting models. In response to this, we propose two contributions: (1) Amelia-48, a large surface movement dataset collected using the System Wide Information Management (SWIM) Surface Movement Event Service (SMES). With data collection beginning in Dec 2022, the dataset provides more than a year's worth of SMES data (~30TB) and covers 48 airports within the US National Airspace System. In addition to releasing this data in the public domain, we also provide post-processing scripts and associated airport maps to enable research in the forecasting domain and beyond. (2) Amelia-TF model, a transformer-based next-token-prediction large multi-agent multi-airport trajectory forecasting model trained on 292 days or 9.4 billion tokens of position data encompassing 10 different airports with varying topology. The open-sourced model is validated on unseen airports with experiments showcasing the different prediction horizon lengths, ego-agent selection strategies, and training recipes to demonstrate the generalization capabilities.
FoundLoc: Vision-based Onboard Aerial Localization in the Wild
Oct 25, 2023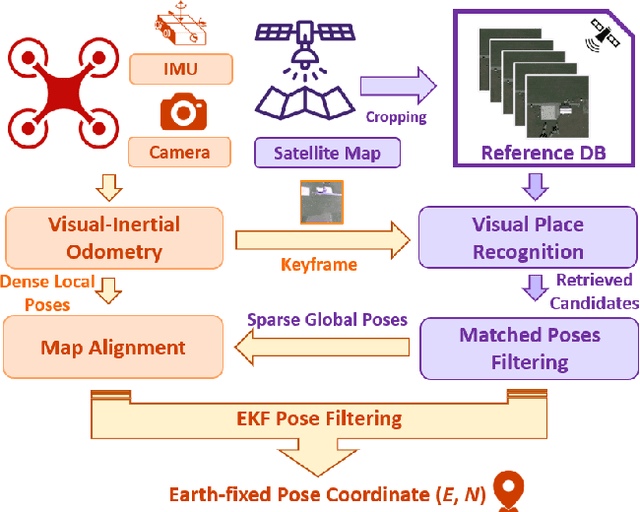
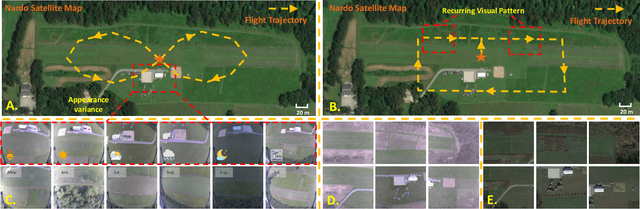

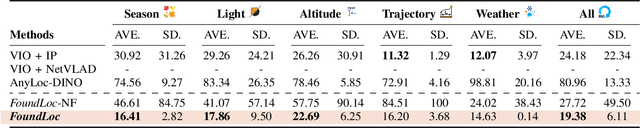
Robust and accurate localization for Unmanned Aerial Vehicles (UAVs) is an essential capability to achieve autonomous, long-range flights. Current methods either rely heavily on GNSS, face limitations in visual-based localization due to appearance variances and stylistic dissimilarities between camera and reference imagery, or operate under the assumption of a known initial pose. In this paper, we developed a GNSS-denied localization approach for UAVs that harnesses both Visual-Inertial Odometry (VIO) and Visual Place Recognition (VPR) using a foundation model. This paper presents a novel vision-based pipeline that works exclusively with a nadir-facing camera, an Inertial Measurement Unit (IMU), and pre-existing satellite imagery for robust, accurate localization in varied environments and conditions. Our system demonstrated average localization accuracy within a $20$-meter range, with a minimum error below $1$ meter, under real-world conditions marked by drastic changes in environmental appearance and with no assumption of the vehicle's initial pose. The method is proven to be effective and robust, addressing the crucial need for reliable UAV localization in GNSS-denied environments, while also being computationally efficient enough to be deployed on resource-constrained platforms.
Importance of negative sampling in weak label learning
Sep 23, 2023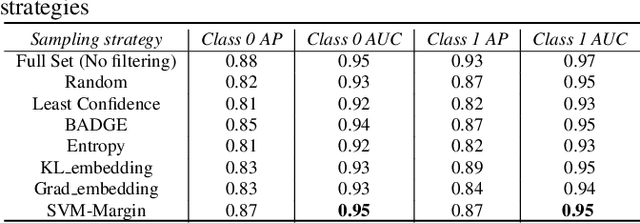
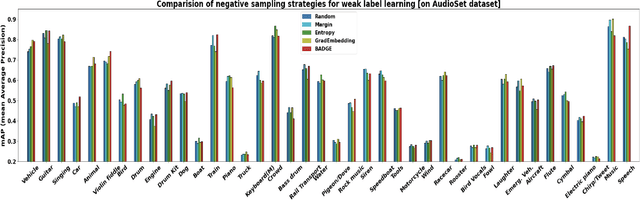
Weak-label learning is a challenging task that requires learning from data "bags" containing positive and negative instances, but only the bag labels are known. The pool of negative instances is usually larger than positive instances, thus making selecting the most informative negative instance critical for performance. Such a selection strategy for negative instances from each bag is an open problem that has not been well studied for weak-label learning. In this paper, we study several sampling strategies that can measure the usefulness of negative instances for weak-label learning and select them accordingly. We test our method on CIFAR-10 and AudioSet datasets and show that it improves the weak-label classification performance and reduces the computational cost compared to random sampling methods. Our work reveals that negative instances are not all equally irrelevant, and selecting them wisely can benefit weak-label learning.
CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference Frame
Mar 06, 2023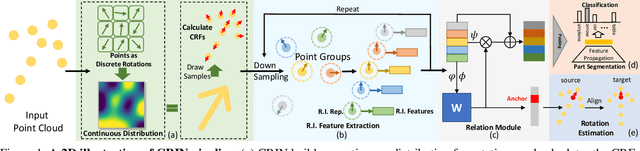
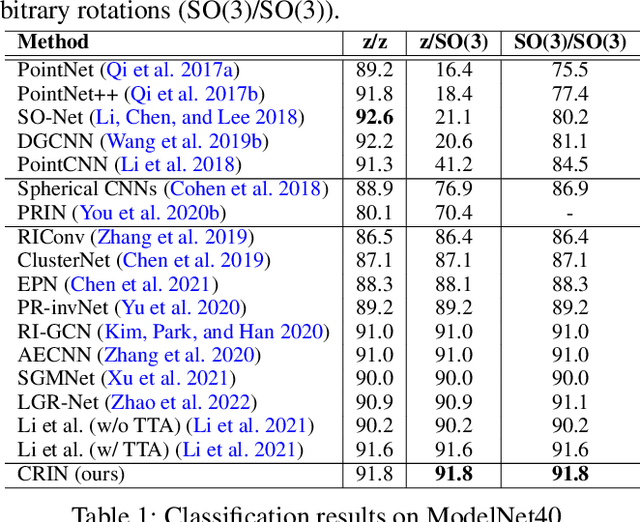
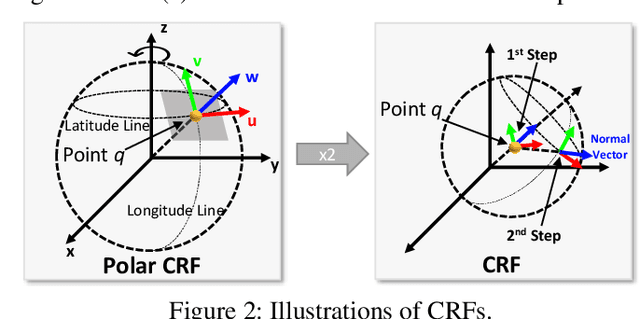
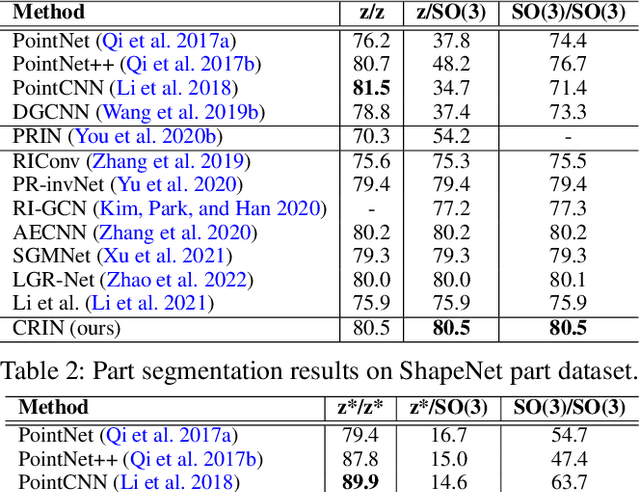
Various recent methods attempt to implement rotation-invariant 3D deep learning by replacing the input coordinates of points with relative distances and angles. Due to the incompleteness of these low-level features, they have to undertake the expense of losing global information. In this paper, we propose the CRIN, namely Centrifugal Rotation-Invariant Network. CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames. Aided by centrifugal reference frames, each point corresponds to a discrete rotation so that the information of rotations can be implicitly stored in point features. Unfortunately, discrete points are far from describing the whole rotation space. We further introduce a continuous distribution for 3D rotations based on points. Furthermore, we propose an attention-based down-sampling strategy to sample points invariant to rotations. A relation module is adopted at last for reinforcing the long-range dependencies between sampled points and predicts the anchor point for unsupervised rotation estimation. Extensive experiments show that our method achieves rotation invariance, accurately estimates the object rotation, and obtains state-of-the-art results on rotation-augmented classification and part segmentation. Ablation studies validate the effectiveness of the network design.
Visualizing Ensemble Predictions of Music Mood
Dec 14, 2021
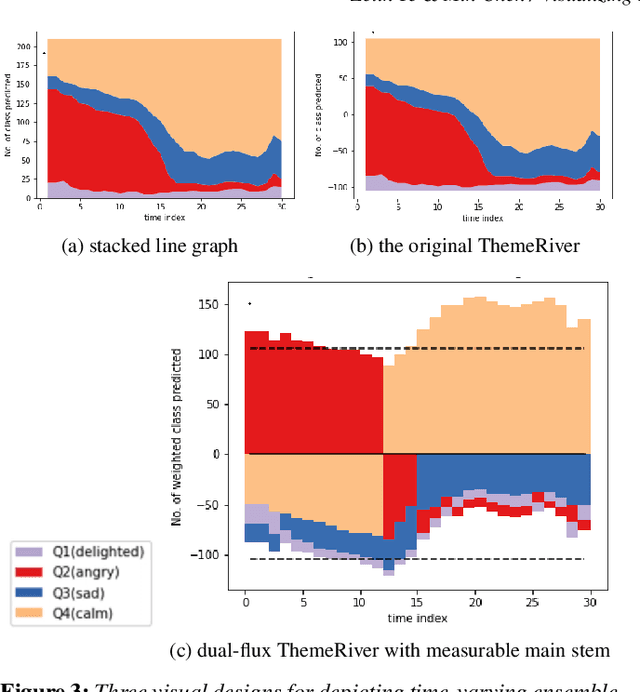
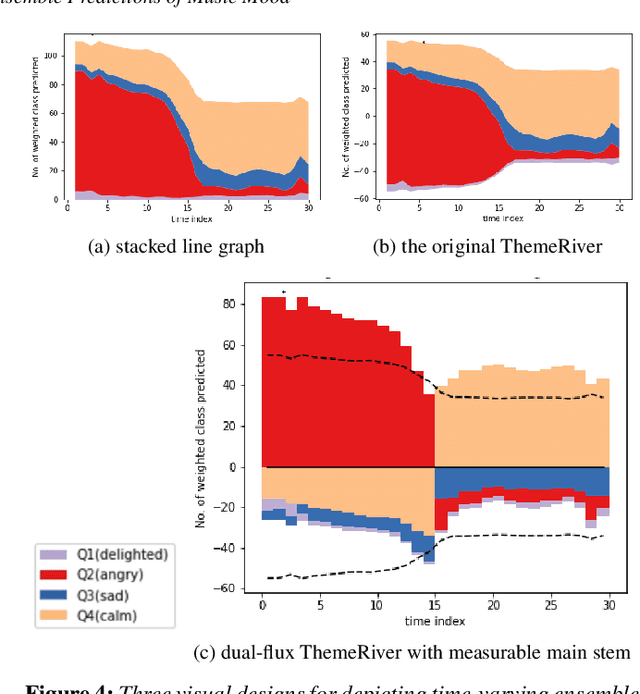

Music mood classification has been a challenging problem in comparison with some other classification problems (e.g., genre, composer, or period). One solution for addressing this challenging is to use an of ensemble machine learning models. In this paper, we show that visualization techniques can effectively convey the popular prediction as well as uncertainty at different music sections along the temporal axis, while enabling the analysis of individual ML models in conjunction with their application to different musical data. In addition to the traditional visual designs, such as stacked line graph, ThemeRiver, and pixel-based visualization, we introduced a new variant of ThemeRiver, called "dual-flux ThemeRiver", which allows viewers to observe and measure the most popular prediction more easily than stacked line graph and ThemeRiver. Testing indicates that visualizing ensemble predictions is helpful both in model-development workflows and for annotating music using model predictions.
Canonical Voting: Towards Robust Oriented Bounding Box Detection in 3D Scenes
Nov 24, 2020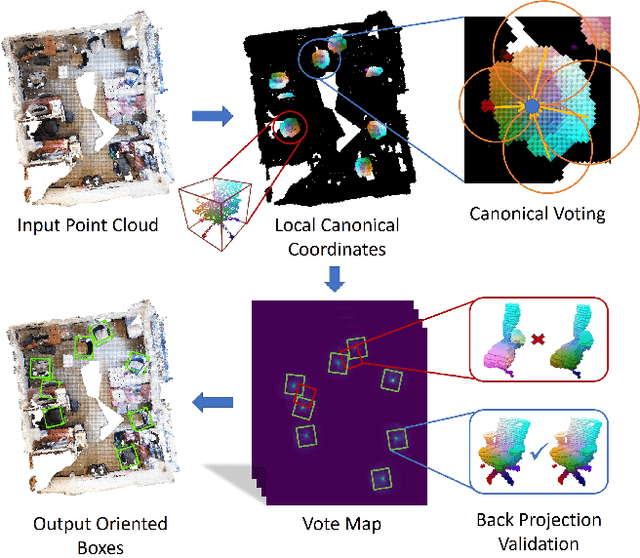

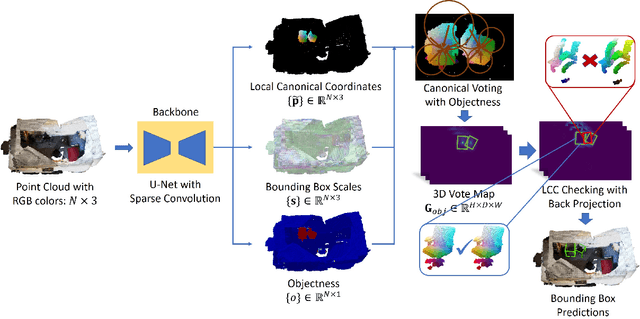
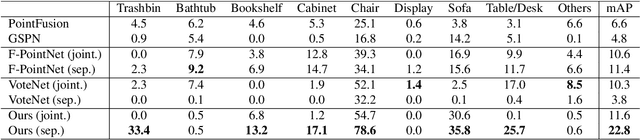
3D object detection has attracted much attention thanks to the advances in sensors and deep learning methods for point clouds. Current state-of-the-art methods like VoteNet regress direct offset towards object centers and box orientations with an additional Multi-Layer-Perceptron network. Both their offset and orientation predictions are not accurate due to the fundamental difficulty in rotation classification. In the work, we disentangle the direct offset into Local Canonical Coordinates (LCC), box scales and box orientations. Only LCC and box scales are regressed while box orientations are generated by a canonical voting scheme. Finally, a LCC-aware back-projection checking algorithm iteratively cuts out bounding boxes from the generated vote maps, with the elimination of false positives. Our model achieves state-of-the-art performance on challenging large-scale datasets of real point cloud scans: ScanNet, SceneNN with 11.4 and 5.3 mAP improvement respectively. Code is available on https://github.com/qq456cvb/CanonicalVoting.
Transferable Active Grasping and Real Embodied Dataset
Apr 28, 2020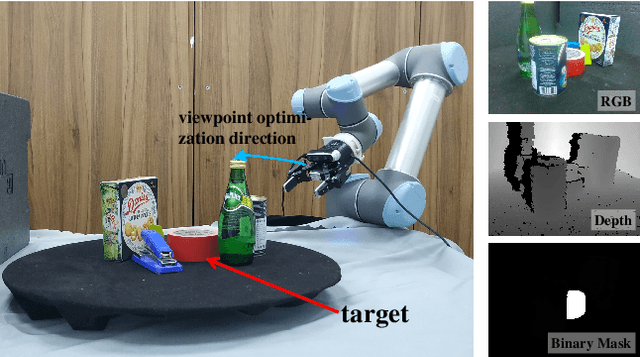



Grasping in cluttered scenes is challenging for robot vision systems, as detection accuracy can be hindered by partial occlusion of objects. We adopt a reinforcement learning (RL) framework and 3D vision architectures to search for feasible viewpoints for grasping by the use of hand-mounted RGB-D cameras. To overcome the disadvantages of photo-realistic environment simulation, we propose a large-scale dataset called Real Embodied Dataset (RED), which includes full-viewpoint real samples on the upper hemisphere with amodal annotation and enables a simulator that has real visual feedback. Based on this dataset, a practical 3-stage transferable active grasping pipeline is developed, that is adaptive to unseen clutter scenes. In our pipeline, we propose a novel mask-guided reward to overcome the sparse reward issue in grasping and ensure category-irrelevant behavior. The grasping pipeline and its possible variants are evaluated with extensive experiments both in simulation and on a real-world UR-5 robotic arm.
3D Objectness Estimation via Bottom-up Regret Grouping
Dec 05, 2019



3D objectness estimation, namely discovering semantic objects from 3D scene, is a challenging and significant task in 3D understanding. In this paper, we propose a 3D objectness method working in a bottom-up manner. Beginning with over-segmented 3D segments, we iteratively group them into object proposals by learning an ingenious grouping predictor to determine whether two 3D segments can be grouped or not. To enhance robustness, a novel regret mechanism is presented to withdraw incorrect grouping operations. Hence the irreparable consequences brought by mistaken grouping in prior bottom-up works can be greatly reduced. Our experiments show that our method outperforms state-of-the-art 3D objectness methods with a small number of proposals in two difficult datasets, GMU-kitchen and CTD. Further ablation study also demonstrates the effectiveness of our grouping predictor and regret mechanism.