 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Source-Free Domain Adaptation for Object Detection: Effective Self-Training Strategies and Performance Insights
Jul 10, 2024

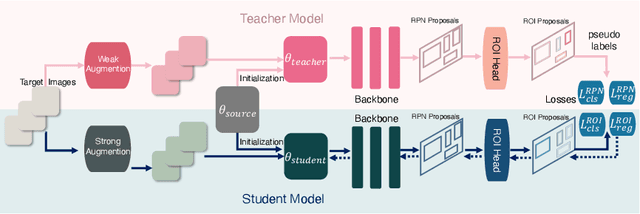

This paper focuses on source-free domain adaptation for object detection in computer vision. This task is challenging and of great practical interest, due to the cost of obtaining annotated data sets for every new domain. Recent research has proposed various solutions for Source-Free Object Detection (SFOD), most being variations of teacher-student architectures with diverse feature alignment, regularization and pseudo-label selection strategies. Our work investigates simpler approaches and their performance compared to more complex SFOD methods in several adaptation scenarios. We highlight the importance of batch normalization layers in the detector backbone, and show that adapting only the batch statistics is a strong baseline for SFOD. We propose a simple extension of a Mean Teacher with strong-weak augmentation in the source-free setting, Source-Free Unbiased Teacher (SF-UT), and show that it actually outperforms most of the previous SFOD methods. Additionally, we showcase that an even simpler strategy consisting in training on a fixed set of pseudo-labels can achieve similar performance to the more complex teacher-student mutual learning, while being computationally efficient and mitigating the major issue of teacher-student collapse. We conduct experiments on several adaptation tasks using benchmark driving datasets including (Foggy)Cityscapes, Sim10k and KITTI, and achieve a notable improvement of 4.7\% AP50 on Cityscapes$\rightarrow$Foggy-Cityscapes compared with the latest state-of-the-art in SFOD. Source code is available at https://github.com/EPFL-IMOS/simple-SFOD.
Nothing Stands Still: A Spatiotemporal Benchmark on 3D Point Cloud Registration Under Large Geometric and Temporal Change
Nov 15, 2023Building 3D geometric maps of man-made spaces is a well-established and active field that is fundamental to computer vision and robotics. However, considering the evolving nature of built environments, it is essential to question the capabilities of current mapping efforts in handling temporal changes. In addition, spatiotemporal mapping holds significant potential for achieving sustainability and circularity goals. Existing mapping approaches focus on small changes, such as object relocation or self-driving car operation; in all cases where the main structure of the scene remains fixed. Consequently, these approaches fail to address more radical changes in the structure of the built environment, such as geometry and topology. To this end, we introduce the Nothing Stands Still (NSS) benchmark, which focuses on the spatiotemporal registration of 3D scenes undergoing large spatial and temporal change, ultimately creating one coherent spatiotemporal map. Specifically, the benchmark involves registering two or more partial 3D point clouds (fragments) from the same scene but captured from different spatiotemporal views. In addition to the standard pairwise registration, we assess the multi-way registration of multiple fragments that belong to any temporal stage. As part of NSS, we introduce a dataset of 3D point clouds recurrently captured in large-scale building indoor environments that are under construction or renovation. The NSS benchmark presents three scenarios of increasing difficulty, to quantify the generalization ability of point cloud registration methods over space (within one building and across buildings) and time. We conduct extensive evaluations of state-of-the-art methods on NSS. The results demonstrate the necessity for novel methods specifically designed to handle large spatiotemporal changes. The homepage of our benchmark is at http://nothing-stands-still.com.
3D Objectness Estimation via Bottom-up Regret Grouping
Dec 05, 2019



3D objectness estimation, namely discovering semantic objects from 3D scene, is a challenging and significant task in 3D understanding. In this paper, we propose a 3D objectness method working in a bottom-up manner. Beginning with over-segmented 3D segments, we iteratively group them into object proposals by learning an ingenious grouping predictor to determine whether two 3D segments can be grouped or not. To enhance robustness, a novel regret mechanism is presented to withdraw incorrect grouping operations. Hence the irreparable consequences brought by mistaken grouping in prior bottom-up works can be greatly reduced. Our experiments show that our method outperforms state-of-the-art 3D objectness methods with a small number of proposals in two difficult datasets, GMU-kitchen and CTD. Further ablation study also demonstrates the effectiveness of our grouping predictor and regret mechanism.
A novel hybrid model based on multi-objective Harris hawks optimization algorithm for daily PM2.5 and PM10 forecasting
May 30, 2019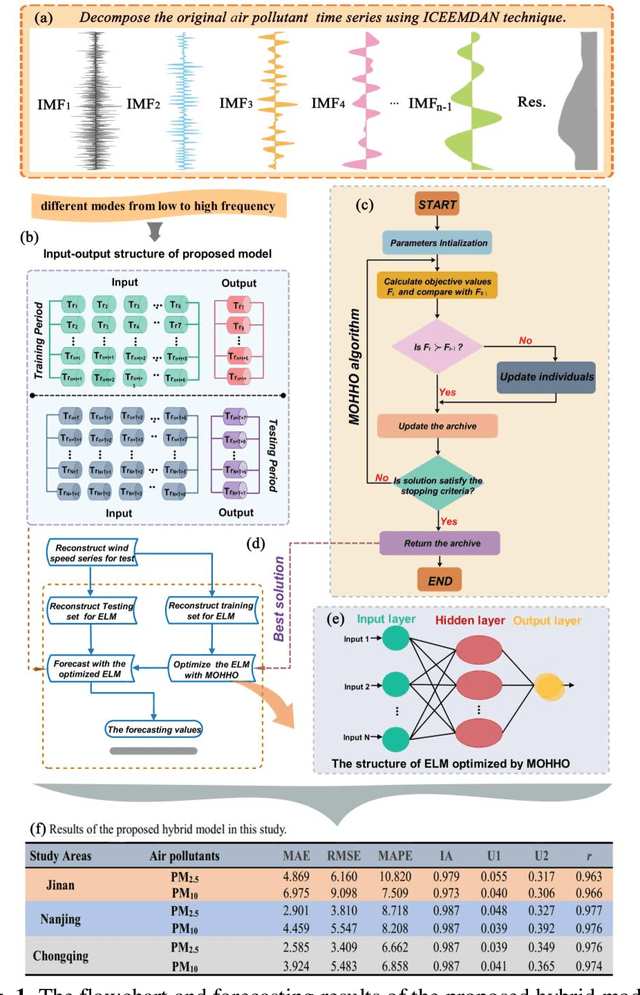
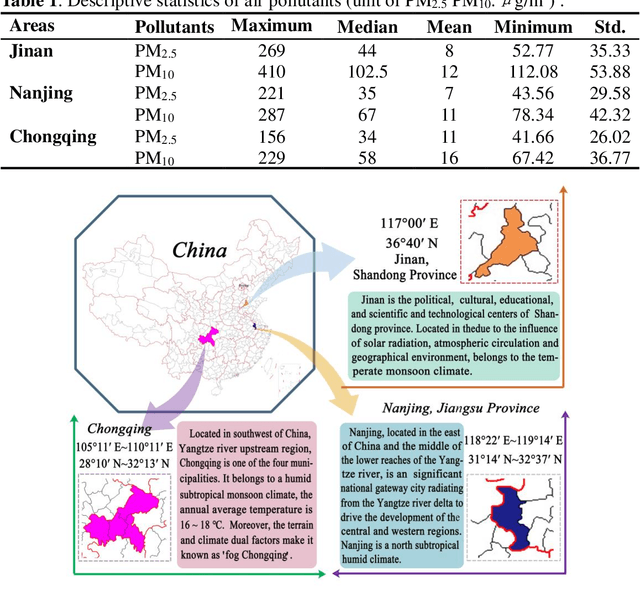
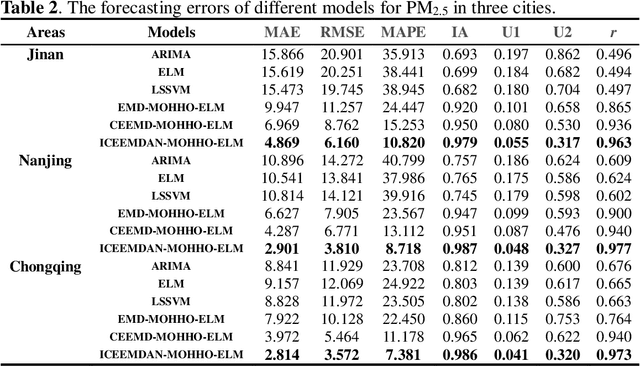
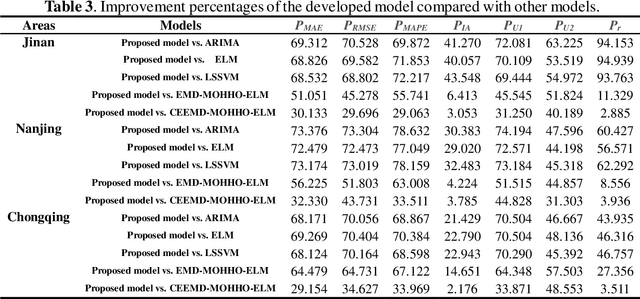
High levels of air pollution may seriously affect people's living environment and even endanger their lives. In order to reduce air pollution concentrations, and warn the public before the occurrence of hazardous air pollutants, it is urgent to design an accurate and reliable air pollutant forecasting model. However, most previous research have many deficiencies, such as ignoring the importance of predictive stability, and poor initial parameters and so on, which have significantly effect on the performance of air pollution prediction. Therefore, to address these issues, a novel hybrid model is proposed in this study. Specifically, a powerful data preprocessing techniques is applied to decompose the original time series into different modes from low- frequency to high- frequency. Next, a new multi-objective algorithm called MOHHO is first developed in this study, which are introduced to tune the parameters of ELM model with high forecasting accuracy and stability for air pollution series prediction, simultaneously. And the optimized ELM model is used to perform the time series prediction. Finally, a scientific and robust evaluation system including several error criteria, benchmark models, and several experiments using six air pollutant concentrations time series from three cities in China is designed to perform a compressive assessment for the presented hybrid forecasting model. Experimental results indicate that the proposed hybrid model can guarantee a more stable and higher predictive performance compared to others, whose superior prediction ability may help to develop effective plans for air pollutant emissions and prevent health problems caused by air pollution.
Visual Rhythm Prediction with Feature-Aligning Network
Jan 29, 2019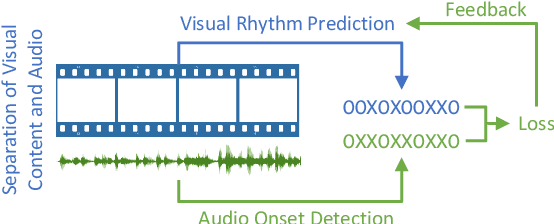

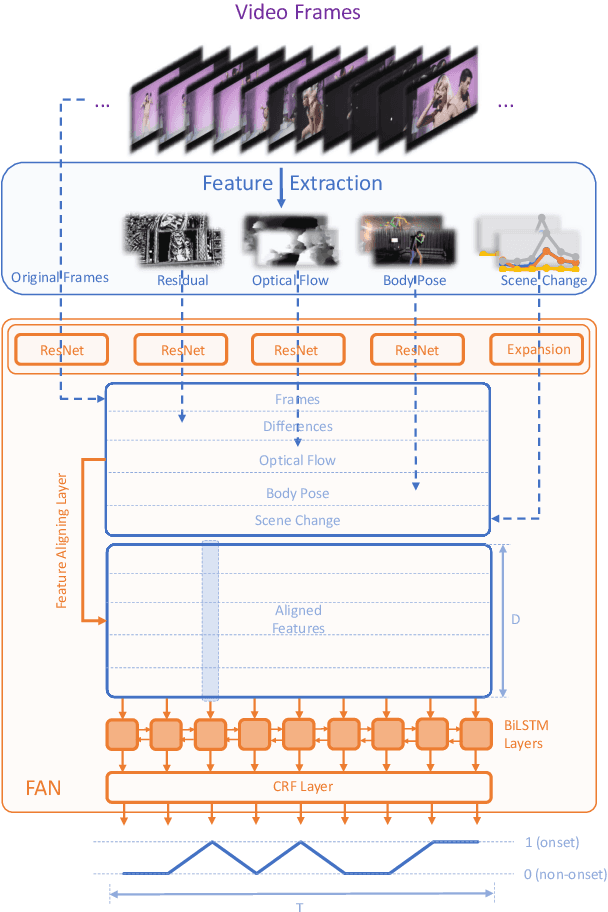
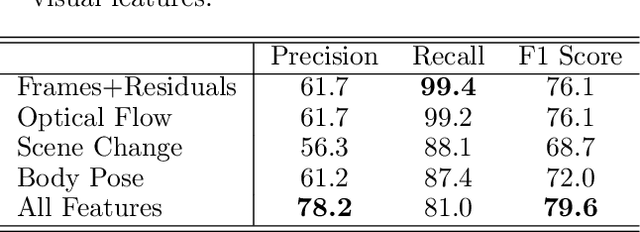
In this paper, we propose a data-driven visual rhythm prediction method, which overcomes the previous works' deficiency that predictions are made primarily by human-crafted hard rules. In our approach, we first extract features including original frames and their residuals, optical flow, scene change, and body pose. These visual features will be next taken into an end-to-end neural network as inputs. Here we observe that there are some slight misaligning between features over the timeline and assume that this is due to the distinctions between how different features are computed. To solve this problem, the extracted features are aligned by an elaborately designed layer, which can also be applied to other models suffering from mismatched features, and boost performance. Then these aligned features are fed into sequence labeling layers implemented with BiLSTM and CRF to predict the onsets. Due to the lack of existing public training and evaluation set, we experiment on a dataset constructed by ourselves based on professionally edited Music Videos (MVs), and the F1 score of our approach reaches 79.6.
Image Segmentation Algorithms Overview
Jul 07, 2017

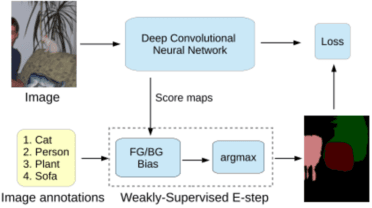
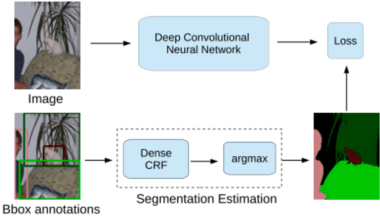
The technology of image segmentation is widely used in medical image processing, face recognition pedestrian detection, etc. The current image segmentation techniques include region-based segmentation, edge detection segmentation, segmentation based on clustering, segmentation based on weakly-supervised learning in CNN, etc. This paper analyzes and summarizes these algorithms of image segmentation, and compares the advantages and disadvantages of different algorithms. Finally, we make a prediction of the development trend of image segmentation with the combination of these algorithms.