 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermoxels: a voxel-based method to generate simulation-ready 3D thermal models
Apr 06, 2025In the European Union, buildings account for 42% of energy use and 35% of greenhouse gas emissions. Since most existing buildings will still be in use by 2050, retrofitting is crucial for emissions reduction. However, current building assessment methods rely mainly on qualitative thermal imaging, which limits data-driven decisions for energy savings. On the other hand, quantitative assessments using finite element analysis (FEA) offer precise insights but require manual CAD design, which is tedious and error-prone. Recent advances in 3D reconstruction, such as Neural Radiance Fields (NeRF) and Gaussian Splatting, enable precise 3D modeling from sparse images but lack clearly defined volumes and the interfaces between them needed for FEA. We propose Thermoxels, a novel voxel-based method able to generate FEA-compatible models, including both geometry and temperature, from a sparse set of RGB and thermal images. Using pairs of RGB and thermal images as input, Thermoxels represents a scene's geometry as a set of voxels comprising color and temperature information. After optimization, a simple process is used to transform Thermoxels' models into tetrahedral meshes compatible with FEA. We demonstrate Thermoxels' capability to generate RGB+Thermal meshes of 3D scenes, surpassing other state-of-the-art methods. To showcase the practical applications of Thermoxels' models, we conduct a simple heat conduction simulation using FEA, achieving convergence from an initial state defined by Thermoxels' thermal reconstruction. Additionally, we compare Thermoxels' image synthesis abilities with current state-of-the-art methods, showing competitive results, and discuss the limitations of existing metrics in assessing mesh quality.
Exploiting Semantic Scene Reconstruction for Estimating Building Envelope Characteristics
Oct 29, 2024Achieving the EU's climate neutrality goal requires retrofitting existing buildings to reduce energy use and emissions. A critical step in this process is the precise assessment of geometric building envelope characteristics to inform retrofitting decisions. Previous methods for estimating building characteristics, such as window-to-wall ratio, building footprint area, and the location of architectural elements, have primarily relied on applying deep-learning-based detection or segmentation techniques on 2D images. However, these approaches tend to focus on planar facade properties, limiting their accuracy and comprehensiveness when analyzing complete building envelopes in 3D. While neural scene representations have shown exceptional performance in indoor scene reconstruction, they remain under-explored for external building envelope analysis. This work addresses this gap by leveraging cutting-edge neural surface reconstruction techniques based on signed distance function (SDF) representations for 3D building analysis. We propose BuildNet3D, a novel framework to estimate geometric building characteristics from 2D image inputs. By integrating SDF-based representation with semantic modality, BuildNet3D recovers fine-grained 3D geometry and semantics of building envelopes, which are then used to automatically extract building characteristics. Our framework is evaluated on a range of complex building structures, demonstrating high accuracy and generalizability in estimating window-to-wall ratio and building footprint. The results underscore the effectiveness of BuildNet3D for practical applications in building analysis and retrofitting.
Simplifying Source-Free Domain Adaptation for Object Detection: Effective Self-Training Strategies and Performance Insights
Jul 10, 2024

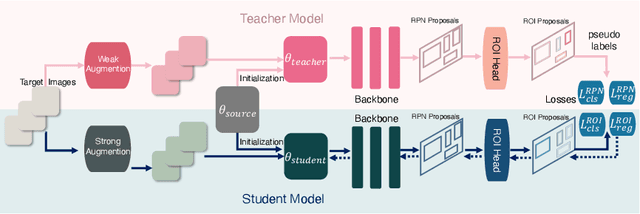

This paper focuses on source-free domain adaptation for object detection in computer vision. This task is challenging and of great practical interest, due to the cost of obtaining annotated data sets for every new domain. Recent research has proposed various solutions for Source-Free Object Detection (SFOD), most being variations of teacher-student architectures with diverse feature alignment, regularization and pseudo-label selection strategies. Our work investigates simpler approaches and their performance compared to more complex SFOD methods in several adaptation scenarios. We highlight the importance of batch normalization layers in the detector backbone, and show that adapting only the batch statistics is a strong baseline for SFOD. We propose a simple extension of a Mean Teacher with strong-weak augmentation in the source-free setting, Source-Free Unbiased Teacher (SF-UT), and show that it actually outperforms most of the previous SFOD methods. Additionally, we showcase that an even simpler strategy consisting in training on a fixed set of pseudo-labels can achieve similar performance to the more complex teacher-student mutual learning, while being computationally efficient and mitigating the major issue of teacher-student collapse. We conduct experiments on several adaptation tasks using benchmark driving datasets including (Foggy)Cityscapes, Sim10k and KITTI, and achieve a notable improvement of 4.7\% AP50 on Cityscapes$\rightarrow$Foggy-Cityscapes compared with the latest state-of-the-art in SFOD. Source code is available at https://github.com/EPFL-IMOS/simple-SFOD.
Interpretable Prognostics with Concept Bottleneck Models
May 27, 2024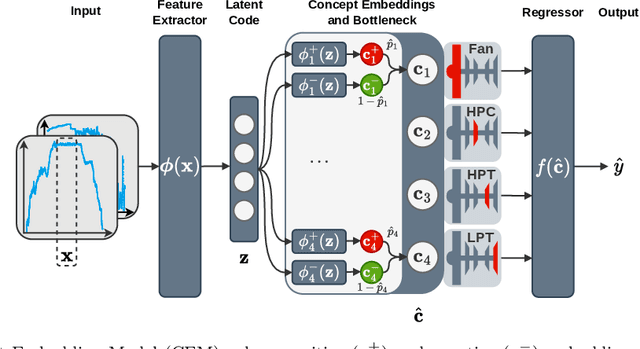
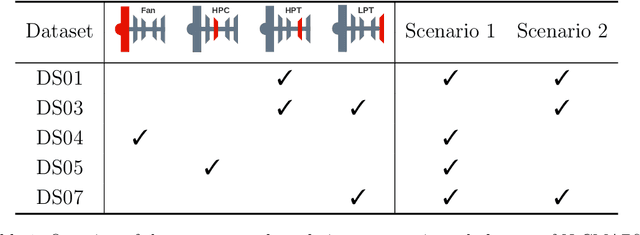
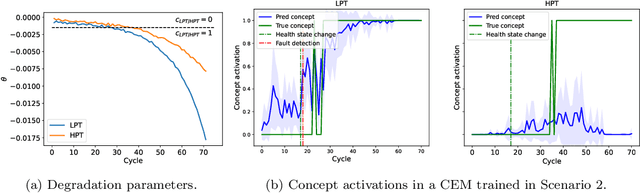
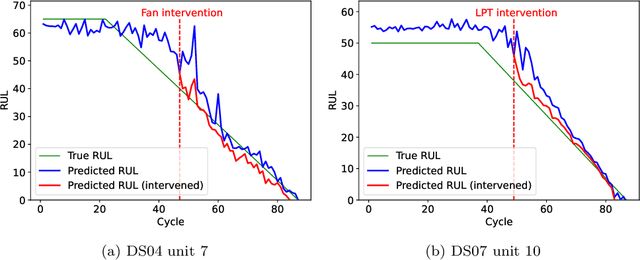
Deep learning approaches have recently been extensively explored for the prognostics of industrial assets. However, they still suffer from a lack of interpretability, which hinders their adoption in safety-critical applications. To improve their trustworthiness, explainable AI (XAI) techniques have been applied in prognostics, primarily to quantify the importance of input variables for predicting the remaining useful life (RUL) using post-hoc attribution methods. In this work, we propose the application of Concept Bottleneck Models (CBMs), a family of inherently interpretable neural network architectures based on concept explanations, to the task of RUL prediction. Unlike attribution methods, which explain decisions in terms of low-level input features, concepts represent high-level information that is easily understandable by users. Moreover, once verified in actual applications, CBMs enable domain experts to intervene on the concept activations at test-time. We propose using the different degradation modes of an asset as intermediate concepts. Our case studies on the New Commercial Modular AeroPropulsion System Simulation (N-CMAPSS) aircraft engine dataset for RUL prediction demonstrate that the performance of CBMs can be on par or superior to black-box models, while being more interpretable, even when the available labeled concepts are limited. Code available at \href{https://github.com/EPFL-IMOS/concept-prognostics/}{\url{github.com/EPFL-IMOS/concept-prognostics/}}.
ThermoNeRF: Multimodal Neural Radiance Fields for Thermal Novel View Synthesis
Mar 18, 2024Thermal scene reconstruction exhibit great potential for applications across a broad spectrum of fields, including building energy consumption analysis and non-destructive testing. However, existing methods typically require dense scene measurements and often rely on RGB images for 3D geometry reconstruction, with thermal information being projected post-reconstruction. This two-step strategy, adopted due to the lack of texture in thermal images, can lead to disparities between the geometry and temperatures of the reconstructed objects and those of the actual scene. To address this challenge, we propose ThermoNeRF, a novel multimodal approach based on Neural Radiance Fields, capable of rendering new RGB and thermal views of a scene jointly. To overcome the lack of texture in thermal images, we use paired RGB and thermal images to learn scene density, while distinct networks estimate color and temperature information. Furthermore, we introduce ThermoScenes, a new dataset to palliate the lack of available RGB+thermal datasets for scene reconstruction. Experimental results validate that ThermoNeRF achieves accurate thermal image synthesis, with an average mean absolute error of 1.5$^\circ$C, an improvement of over 50% compared to using concatenated RGB+thermal data with Nerfacto, a state-of-the-art NeRF method.
Uncertainty-Guided Alignment for Unsupervised Domain Adaptation in Regression
Jan 26, 2024



Unsupervised Domain Adaptation for Regression (UDAR) aims to adapt a model from a labeled source domain to an unlabeled target domain for regression tasks. Recent successful works in UDAR mostly focus on subspace alignment, involving the alignment of a selected subspace within the entire feature space. This contrasts with the feature alignment methods used for classification, which aim at aligning the entire feature space and have proven effective but are less so in regression settings. Specifically, while classification aims to identify separate clusters across the entire embedding dimension, regression induces less structure in the data representation, necessitating additional guidance for efficient alignment. In this paper, we propose an effective method for UDAR by incorporating guidance from uncertainty. Our approach serves a dual purpose: providing a measure of confidence in predictions and acting as a regularization of the embedding space. Specifically, we leverage the Deep Evidential Learning framework, which outputs both predictions and uncertainties for each input sample. We propose aligning the parameters of higher-order evidential distributions between the source and target domains using traditional alignment methods at the feature or posterior level. Additionally, we propose to augment the feature space representation by mixing source samples with pseudo-labeled target samples based on label similarity. This cross-domain mixing strategy produces more realistic samples than random mixing and introduces higher uncertainty, facilitating further alignment. We demonstrate the effectiveness of our approach on four benchmarks for UDAR, on which we outperform existing methods.
Calibrated Adaptive Teacher for Domain Adaptive Intelligent Fault Diagnosis
Dec 05, 2023Intelligent Fault Diagnosis (IFD) based on deep learning has proven to be an effective and flexible solution, attracting extensive research. Deep neural networks can learn rich representations from vast amounts of representative labeled data for various applications. In IFD, they achieve high classification performance from signals in an end-to-end manner, without requiring extensive domain knowledge. However, deep learning models usually only perform well on the data distribution they have been trained on. When applied to a different distribution, they may experience performance drops. This is also observed in IFD, where assets are often operated in working conditions different from those in which labeled data have been collected. Unsupervised domain adaptation (UDA) deals with the scenario where labeled data are available in a source domain, and only unlabeled data are available in a target domain, where domains may correspond to operating conditions. Recent methods rely on training with confident pseudo-labels for target samples. However, the confidence-based selection of pseudo-labels is hindered by poorly calibrated confidence estimates in the target domain, primarily due to over-confident predictions, which limits the quality of pseudo-labels and leads to error accumulation. In this paper, we propose a novel UDA method called Calibrated Adaptive Teacher (CAT), where we propose to calibrate the predictions of the teacher network throughout the self-training process, leveraging post-hoc calibration techniques. We evaluate CAT on domain-adaptive IFD and perform extensive experiments on the Paderborn benchmark for bearing fault diagnosis under varying operating conditions. Our proposed method achieves state-of-the-art performance on most transfer tasks.
From Classification to Segmentation with Explainable AI: A Study on Crack Detection and Growth Monitoring
Sep 20, 2023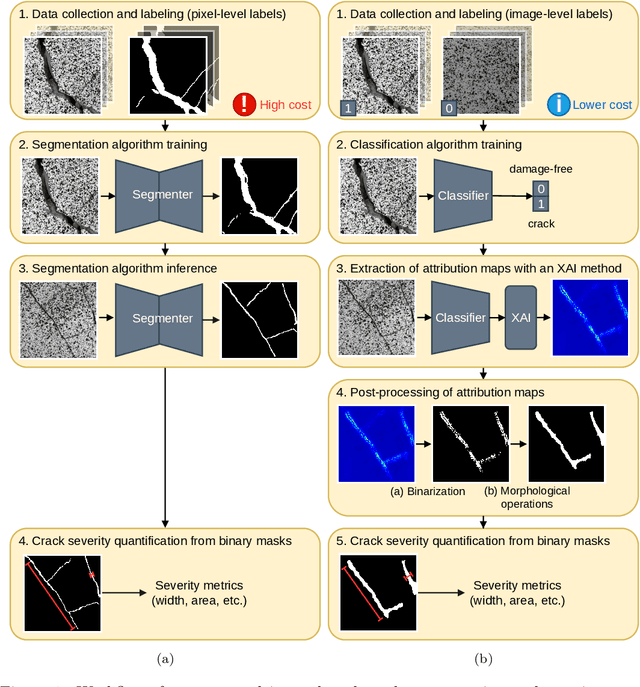



Monitoring surface cracks in infrastructure is crucial for structural health monitoring. Automatic visual inspection offers an effective solution, especially in hard-to-reach areas. Machine learning approaches have proven their effectiveness but typically require large annotated datasets for supervised training. Once a crack is detected, monitoring its severity often demands precise segmentation of the damage. However, pixel-level annotation of images for segmentation is labor-intensive. To mitigate this cost, one can leverage explainable artificial intelligence (XAI) to derive segmentations from the explanations of a classifier, requiring only weak image-level supervision. This paper proposes applying this methodology to segment and monitor surface cracks. We evaluate the performance of various XAI methods and examine how this approach facilitates severity quantification and growth monitoring. Results reveal that while the resulting segmentation masks may exhibit lower quality than those produced by supervised methods, they remain meaningful and enable severity monitoring, thus reducing substantial labeling costs.
Transformer-based conditional generative adversarial network for multivariate time series generation
Oct 05, 2022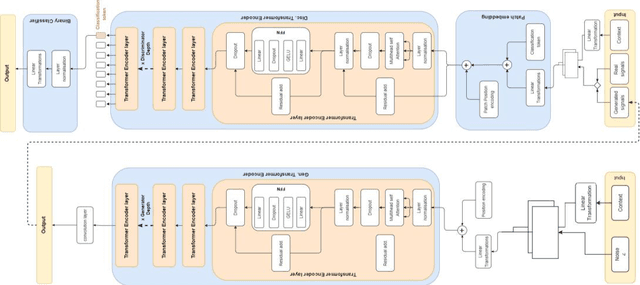
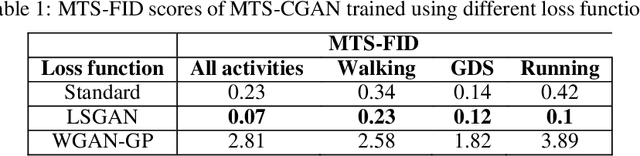

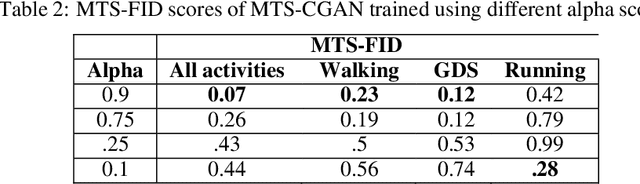
Conditional generation of time-dependent data is a task that has much interest, whether for data augmentation, scenario simulation, completing missing data, or other purposes. Recent works proposed a Transformer-based Time series generative adversarial network (TTS-GAN) to address the limitations of recurrent neural networks. However, this model assumes a unimodal distribution and tries to generate samples around the expectation of the real data distribution. One of its limitations is that it may generate a random multivariate time series; it may fail to generate samples in the presence of multiple sub-components within an overall distribution. One could train models to fit each sub-component separately to overcome this limitation. Our work extends the TTS-GAN by conditioning its generated output on a particular encoded context allowing the use of one model to fit a mixture distribution with multiple sub-components. Technically, it is a conditional generative adversarial network that models realistic multivariate time series under different types of conditions, such as categorical variables or multivariate time series. We evaluate our model on UniMiB Dataset, which contains acceleration data following the XYZ axes of human activities collected using Smartphones. We use qualitative evaluations and quantitative metrics such as Principal Component Analysis (PCA), and we introduce a modified version of the Frechet inception distance (FID) to measure the performance of our model and the statistical similarities between the generated and the real data distributions. We show that this transformer-based CGAN can generate realistic high-dimensional and long data sequences under different kinds of conditions.
A Survey and Implementation of Performance Metrics for Self-Organized Maps
Nov 11, 2020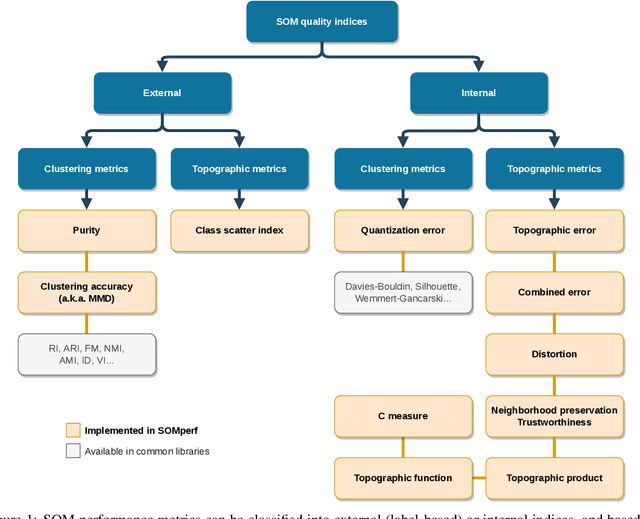
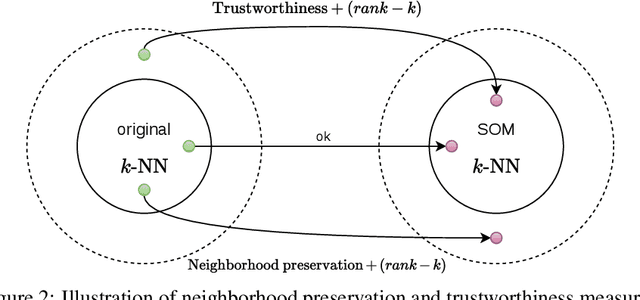
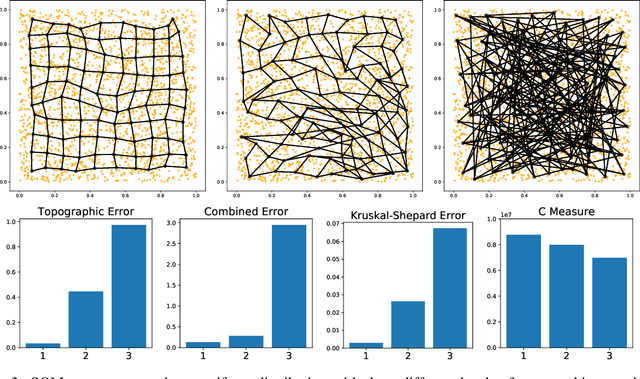
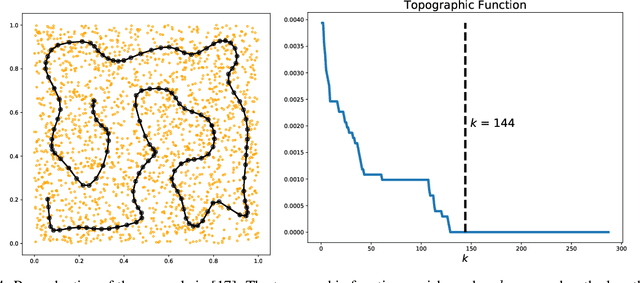
Self-Organizing Map algorithms have been used for almost 40 years across various application domains such as biology, geology, healthcare, industry and humanities as an interpretable tool to explore, cluster and visualize high-dimensional data sets. In every application, practitioners need to know whether they can \textit{trust} the resulting mapping, and perform model selection to tune algorithm parameters (e.g. the map size). Quantitative evaluation of self-organizing maps (SOM) is a subset of clustering validation, which is a challenging problem as such. Clustering model selection is typically achieved by using clustering validity indices. While they also apply to self-organized clustering models, they ignore the topology of the map, only answering the question: do the SOM code vectors approximate well the data distribution? Evaluating SOM models brings in the additional challenge of assessing their topology: does the mapping preserve neighborhood relationships between the map and the original data? The problem of assessing the performance of SOM models has already been tackled quite thoroughly in literature, giving birth to a family of quality indices incorporating neighborhood constraints, called \textit{topographic} indices. Commonly used examples of such metrics are the topographic error, neighborhood preservation or the topographic product. However, open-source implementations are almost impossible to find. This is the issue we try to solve in this work: after a survey of existing SOM performance metrics, we implemented them in Python and widely used numerical libraries, and provide them as an open-source library, SOMperf. This paper introduces each metric available in our module along with usage examples.