 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Prognostics with Concept Bottleneck Models
May 27, 2024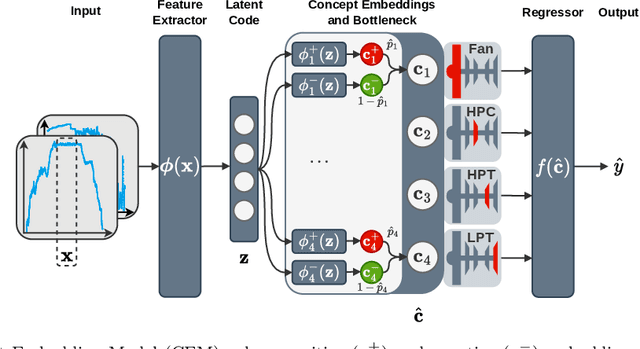
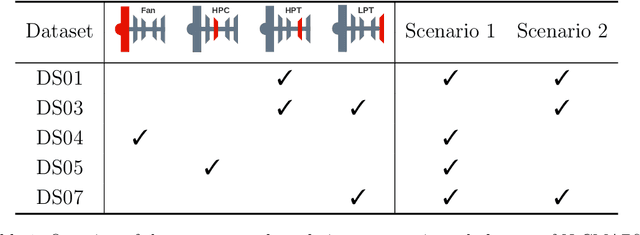
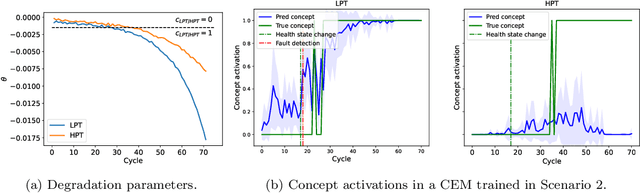
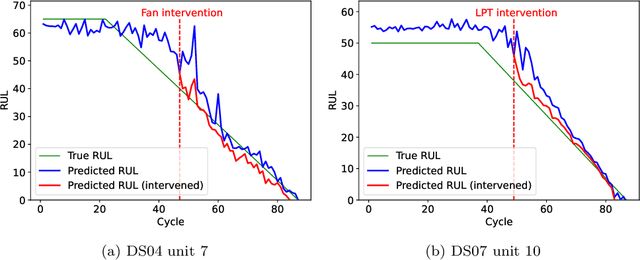
Deep learning approaches have recently been extensively explored for the prognostics of industrial assets. However, they still suffer from a lack of interpretability, which hinders their adoption in safety-critical applications. To improve their trustworthiness, explainable AI (XAI) techniques have been applied in prognostics, primarily to quantify the importance of input variables for predicting the remaining useful life (RUL) using post-hoc attribution methods. In this work, we propose the application of Concept Bottleneck Models (CBMs), a family of inherently interpretable neural network architectures based on concept explanations, to the task of RUL prediction. Unlike attribution methods, which explain decisions in terms of low-level input features, concepts represent high-level information that is easily understandable by users. Moreover, once verified in actual applications, CBMs enable domain experts to intervene on the concept activations at test-time. We propose using the different degradation modes of an asset as intermediate concepts. Our case studies on the New Commercial Modular AeroPropulsion System Simulation (N-CMAPSS) aircraft engine dataset for RUL prediction demonstrate that the performance of CBMs can be on par or superior to black-box models, while being more interpretable, even when the available labeled concepts are limited. Code available at \href{https://github.com/EPFL-IMOS/concept-prognostics/}{\url{github.com/EPFL-IMOS/concept-prognostics/}}.
Contrastive Feature Learning for Fault Detection and Diagnostics in Railway Applications
Aug 28, 2022
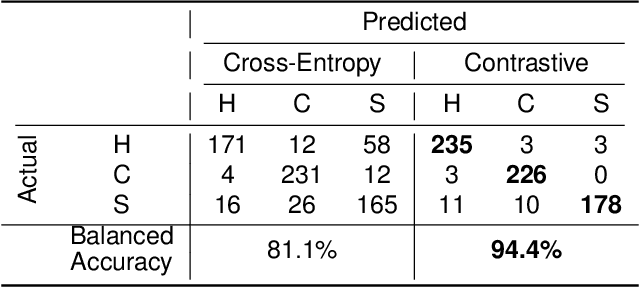


A railway is a complex system comprising multiple infrastructure and rolling stock assets. To operate the system safely, reliably, and efficiently, the condition many components needs to be monitored. To automate this process, data-driven fault detection and diagnostics models can be employed. In practice, however, the performance of data-driven models can be compromised if the training dataset is not representative of all possible future conditions. We propose to approach this problem by learning a feature representation that is, on the one hand, invariant to operating or environmental factors but, on the other hand, sensitive to changes in the asset's health condition. We evaluate how contrastive learning can be employed on supervised and unsupervised fault detection and diagnostics tasks given real condition monitoring datasets within a railway system - one image dataset from infrastructure assets and one time-series dataset from rolling stock assets. First, we evaluate the performance of supervised contrastive feature learning on a railway sleeper defect classification task given a labeled image dataset. Second, we evaluate the performance of unsupervised contrastive feature learning without access to faulty samples on an anomaly detection task given a railway wheel dataset. Here, we test the hypothesis of whether a feature encoder's sensitivity to degradation is also sensitive to novel fault patterns in the data. Our results demonstrate that contrastive feature learning improves the performance on the supervised classification task regarding sleepers compared to a state-of-the-art method. Moreover, on the anomaly detection task concerning the railway wheels, the detection of shelling defects is improved compared to state-of-the-art methods.
Controlled Generation of Unseen Faults for Partial and OpenSet&Partial Domain Adaptation
Apr 29, 2022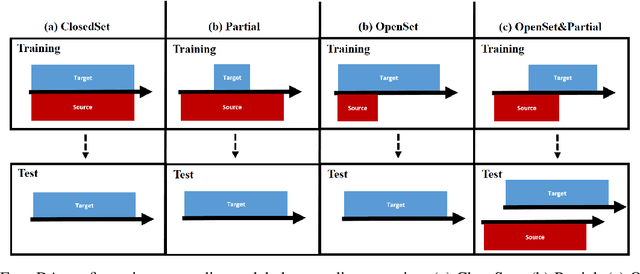
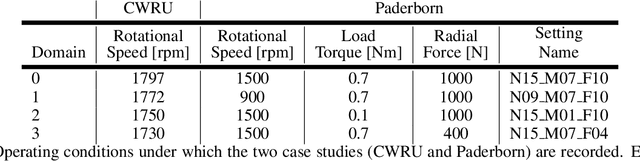
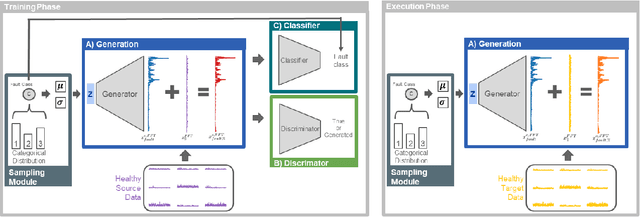
New operating conditions can result in a performance drop of fault diagnostics models due to the domain gap between the training and the testing data distributions. While several domain adaptation approaches have been proposed to overcome such domain shifts, their application is limited if the label spaces of the two domains are not congruent. To improve the transferability of the trained models, particularly in setups where only the healthy data class is shared between the two domains, we propose a new framework based on a Wasserstein GAN for Partial and OpenSet&Partial domain adaptation. The main contribution is the controlled fault data generation that enables to generate unobserved fault types and severity levels in the target domain by having only access to the healthy samples in the target domain and faulty samples in the source domain. To evaluate the ability of the proposed method to bridge domain gaps in different domain adaption settings, we conduct Partial as well as OpenSet&Partial domain adaptation experiments on two bearing fault diagnostics case studies. The results show the versatility of the framework and that the synthetically generated fault data helps bridging the domain gaps, especially in instances where the domain gap is large.
Improving Generalization of Deep Fault Detection Models in the Presence of Mislabeled Data
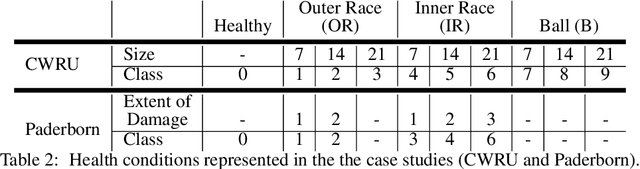
Sep 30, 2020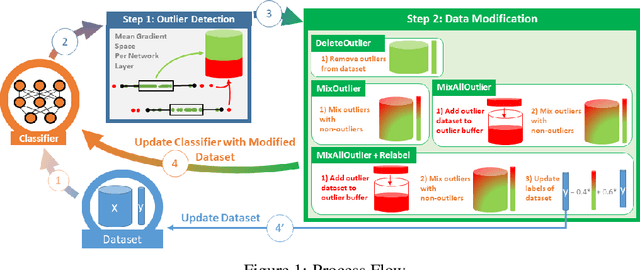

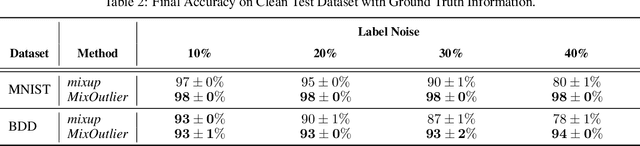
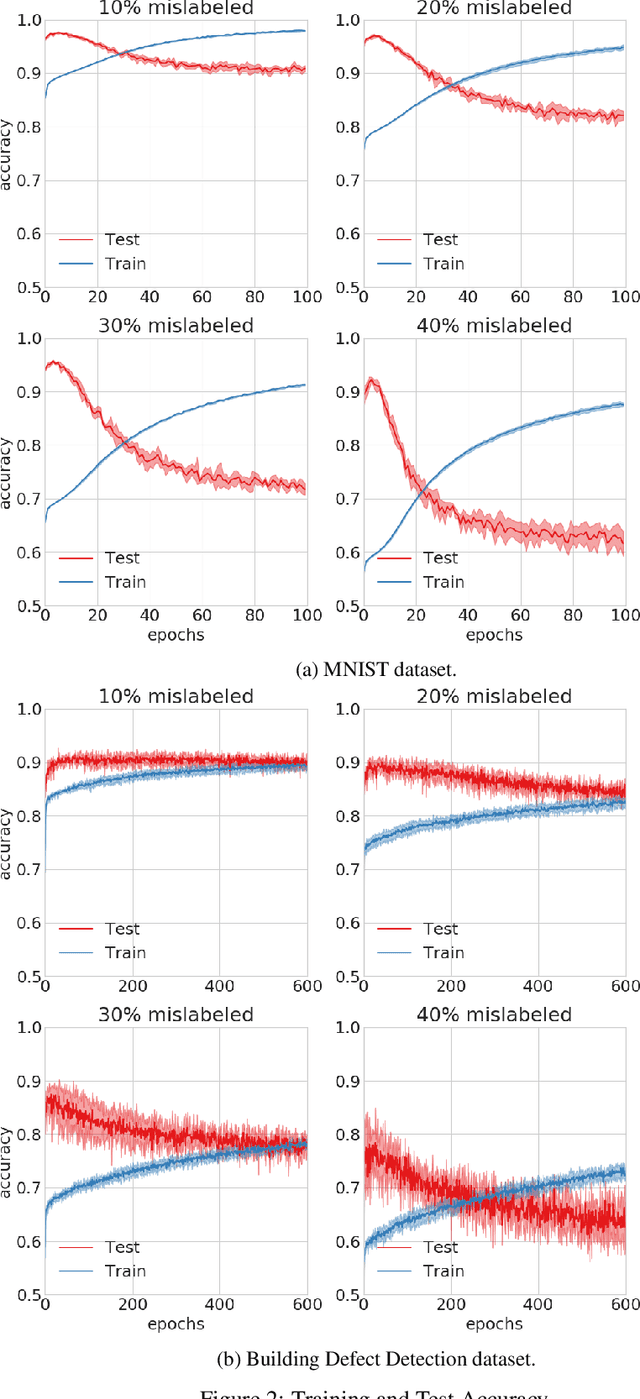
Mislabeled samples are ubiquitous in real-world datasets as rule-based or expert labeling is usually based on incorrect assumptions or subject to biased opinions. Neural networks can "memorize" these mislabeled samples and, as a result, exhibit poor generalization. This poses a critical issue in fault detection applications, where not only the training but also the validation datasets are prone to contain mislabeled samples. In this work, we propose a novel two-step framework for robust training with label noise. In the first step, we identify outliers (including the mislabeled samples) based on the update in the hypothesis space. In the second step, we propose different approaches to modifying the training data based on the identified outliers and a data augmentation technique. Contrary to previous approaches, we aim at finding a robust solution that is suitable for real-world applications, such as fault detection, where no clean, "noise-free" validation dataset is available. Under an approximate assumption about the upper limit of the label noise, we significantly improve the generalization ability of the model trained under massive label noise.
Supervised Learning and Reinforcement Learning of Feedback Models for Reactive Behaviors: Tactile Feedback Testbed
Jun 29, 2020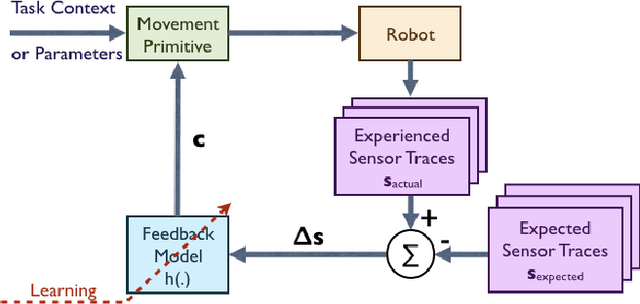
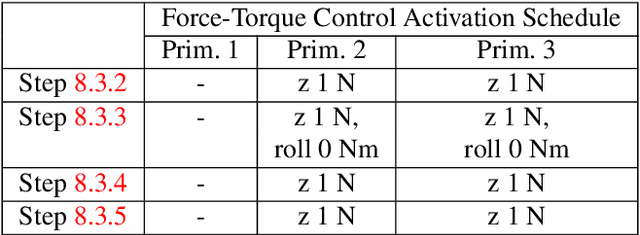

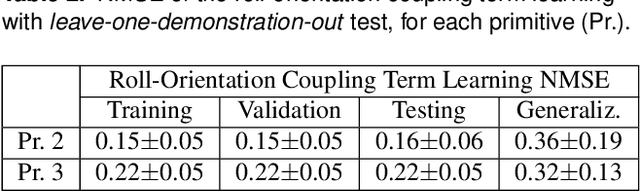
Robots need to be able to adapt to unexpected changes in the environment such that they can autonomously succeed in their tasks. However, hand-designing feedback models for adaptation is tedious, if at all possible, making data-driven methods a promising alternative. In this paper we introduce a full framework for learning feedback models for reactive motion planning. Our pipeline starts by segmenting demonstrations of a complete task into motion primitives via a semi-automated segmentation algorithm. Then, given additional demonstrations of successful adaptation behaviors, we learn initial feedback models through learning from demonstrations. In the final phase, a sample-efficient reinforcement learning algorithm fine-tunes these feedback models for novel task settings through few real system interactions. We evaluate our approach on a real anthropomorphic robot in learning a tactile feedback task.
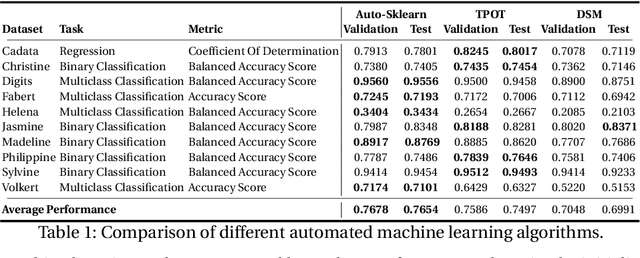
Automated Machine Learning in Practice: State of the Art and Recent Results
Jul 19, 2019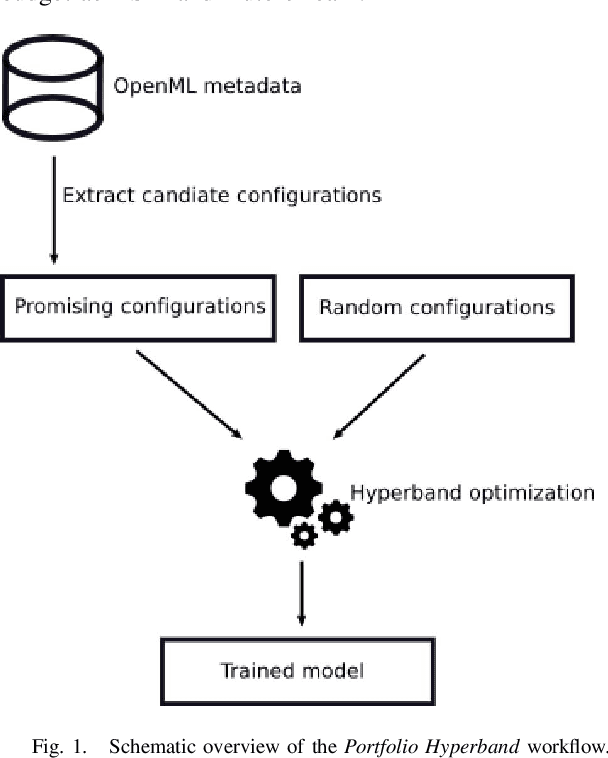
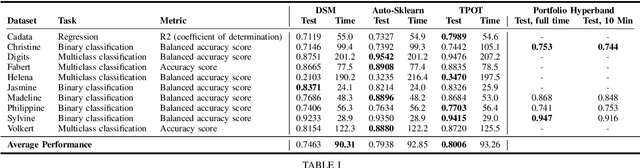
A main driver behind the digitization of industry and society is the belief that data-driven model building and decision making can contribute to higher degrees of automation and more informed decisions. Building such models from data often involves the application of some form of machine learning. Thus, there is an ever growing demand in work force with the necessary skill set to do so. This demand has given rise to a new research topic concerned with fitting machine learning models fully automatically - AutoML. This paper gives an overview of the state of the art in AutoML with a focus on practical applicability in a business context, and provides recent benchmark results on the most important AutoML algorithms.
Deep Learning in the Wild
Jul 13, 2018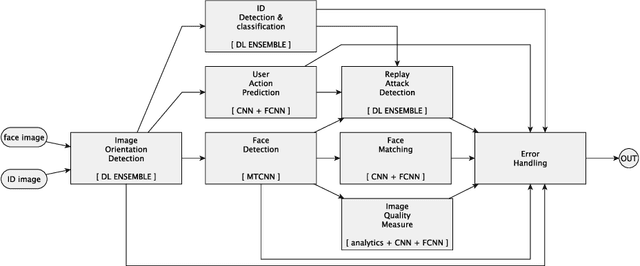


Deep learning with neural networks is applied by an increasing number of people outside of classic research environments, due to the vast success of the methodology on a wide range of machine perception tasks. While this interest is fueled by beautiful success stories, practical work in deep learning on novel tasks without existing baselines remains challenging. This paper explores the specific challenges arising in the realm of real world tasks, based on case studies from research \& development in conjunction with industry, and extracts lessons learned from them. It thus fills a gap between the publication of latest algorithmic and methodical developments, and the usually omitted nitty-gritty of how to make them work. Specifically, we give insight into deep learning projects on face matching, print media monitoring, industrial quality control, music scanning, strategy game playing, and automated machine learning, thereby providing best practices for deep learning in practice.