 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Feature Learning for Fault Detection and Diagnostics in Railway Applications
Aug 28, 2022
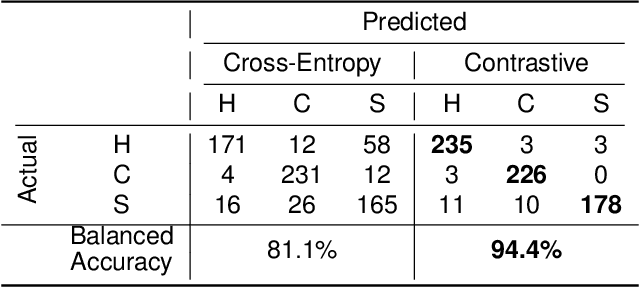


A railway is a complex system comprising multiple infrastructure and rolling stock assets. To operate the system safely, reliably, and efficiently, the condition many components needs to be monitored. To automate this process, data-driven fault detection and diagnostics models can be employed. In practice, however, the performance of data-driven models can be compromised if the training dataset is not representative of all possible future conditions. We propose to approach this problem by learning a feature representation that is, on the one hand, invariant to operating or environmental factors but, on the other hand, sensitive to changes in the asset's health condition. We evaluate how contrastive learning can be employed on supervised and unsupervised fault detection and diagnostics tasks given real condition monitoring datasets within a railway system - one image dataset from infrastructure assets and one time-series dataset from rolling stock assets. First, we evaluate the performance of supervised contrastive feature learning on a railway sleeper defect classification task given a labeled image dataset. Second, we evaluate the performance of unsupervised contrastive feature learning without access to faulty samples on an anomaly detection task given a railway wheel dataset. Here, we test the hypothesis of whether a feature encoder's sensitivity to degradation is also sensitive to novel fault patterns in the data. Our results demonstrate that contrastive feature learning improves the performance on the supervised classification task regarding sleepers compared to a state-of-the-art method. Moreover, on the anomaly detection task concerning the railway wheels, the detection of shelling defects is improved compared to state-of-the-art methods.
Fully Learnable Deep Wavelet Transform for Unsupervised Monitoring of High-Frequency Time Series
May 03, 2021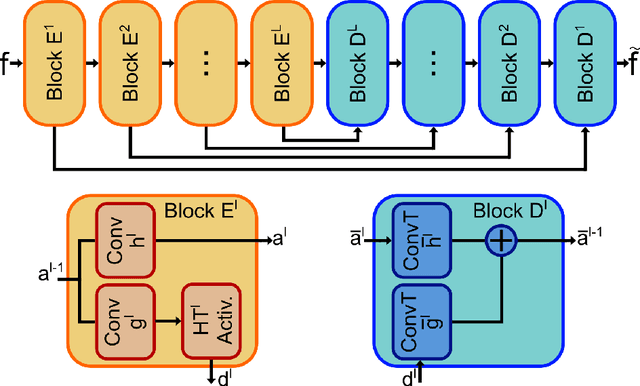
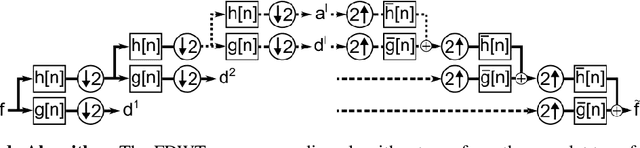

High-Frequency (HF) signal are ubiquitous in the industrial world and are of great use for the monitoring of industrial assets. Most deep learning tools are designed for inputs of fixed and/or very limited size and many successful applications of deep learning to the industrial context use as inputs extracted features, which is a manually and often arduously obtained compact representation of the original signal. In this paper, we propose a fully unsupervised deep learning framework that is able to extract meaningful and sparse representation of raw HF signals. We embed in our architecture important properties of the fast discrete wavelet transformation (FDWT) such as (1) the cascade algorithm, (2) the quadrature mirror filter property that relates together the wavelet, the scaling and transposed filter functions, and (3) the coefficient denoising. Using deep learning, we make this architecture fully learnable: both the wavelet bases and the wavelet coefficient denoising are learnable. To achieve this objective, we introduce a new activation function that performs a learnable hard-thresholding of the wavelet coefficients. With our framework, the denoising FDWT becomes a fully learnable unsupervised tool that does neither require any type of pre- nor post-processing, nor any prior knowledge on wavelet transform. We demonstrate the benefit of embedding all these properties on three machine-learning tasks performed on open source sound datasets. We achieve results well above baseline and we perform an ablation study of the impact of each property on the performance of the architecture.
Decision Support System for an Intelligent Operator of Utility Tunnel Boring Machines
Jan 08, 2021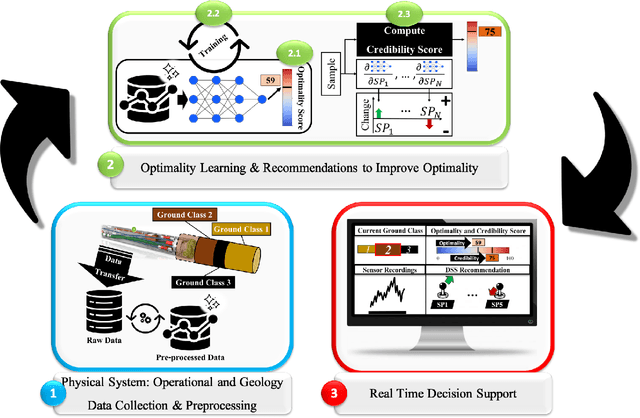

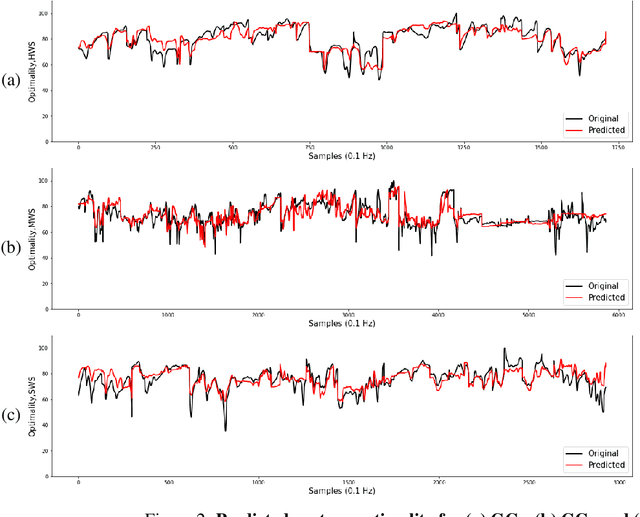
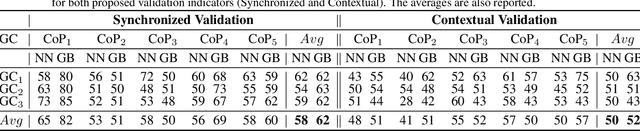
In tunnel construction projects, delays induce high costs. Thus, tunnel boring machines (TBM) operators aim for fast advance rates, without safety compromise, a difficult mission in uncertain ground environments. Finding the optimal control parameters based on the TBM sensors' measurements remains an open research question with large practical relevance. In this paper, we propose an intelligent decision support system developed in three steps. First past projects performances are evaluated with an optimality score, taking into account the advance rate and the working pressure safety. Then, a deep learning model learns the mapping between the TBM measurements and this optimality score. Last, in real application, the model provides incremental recommendations to improve the optimality, taking into account the current setting and measurements of the TBM. The proposed approach is evaluated on real micro-tunnelling project and demonstrates great promises for future projects.
Improving Generalization of Deep Fault Detection Models in the Presence of Mislabeled Data
Sep 30, 2020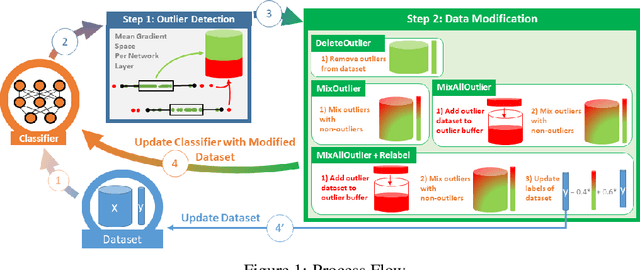

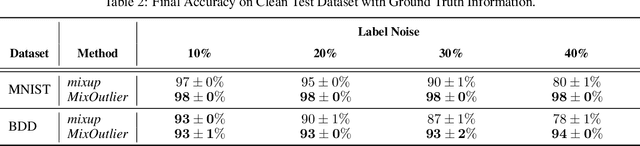
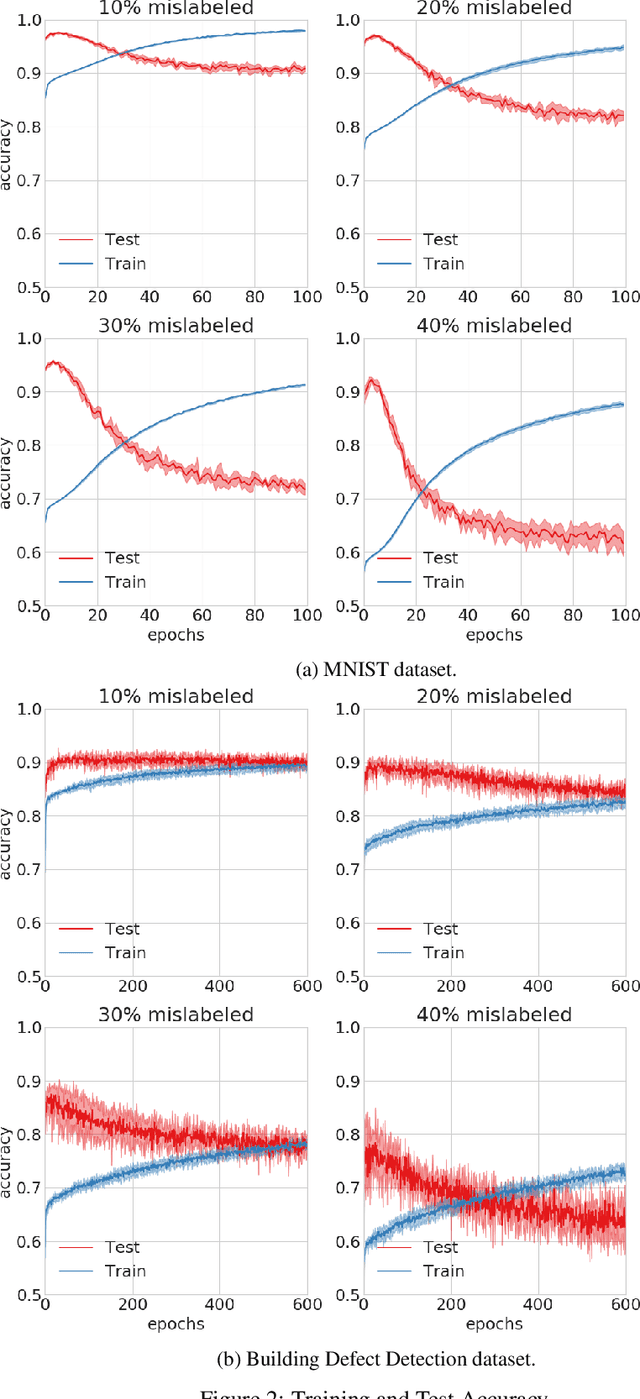
Mislabeled samples are ubiquitous in real-world datasets as rule-based or expert labeling is usually based on incorrect assumptions or subject to biased opinions. Neural networks can "memorize" these mislabeled samples and, as a result, exhibit poor generalization. This poses a critical issue in fault detection applications, where not only the training but also the validation datasets are prone to contain mislabeled samples. In this work, we propose a novel two-step framework for robust training with label noise. In the first step, we identify outliers (including the mislabeled samples) based on the update in the hypothesis space. In the second step, we propose different approaches to modifying the training data based on the identified outliers and a data augmentation technique. Contrary to previous approaches, we aim at finding a robust solution that is suitable for real-world applications, such as fault detection, where no clean, "noise-free" validation dataset is available. Under an approximate assumption about the upper limit of the label noise, we significantly improve the generalization ability of the model trained under massive label noise.
Interpretable Partial Discharge Detection with Temporal Convolution and Pulse Activation Maps: An application to Power Lines
Sep 17, 2020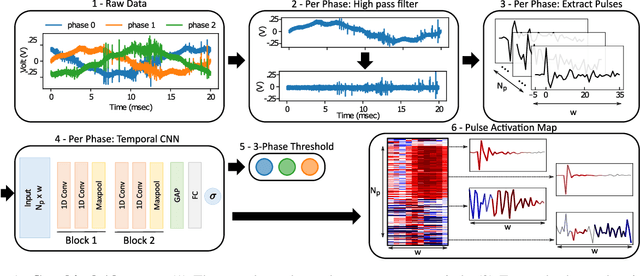


Partial discharge (PD) is a common indication of insulation damages in power systems and cables. These damages can eventually result in costly repairs and substantial power outages. PD detection traditionally relies on hand-crafted features and domain expertise to identify very specific pulses in the electrical current, and the performance declines in the presence of noise or of superposed pulses. In this paper, we propose a novel end-to-end framework based on convolutional neural networks. The framework has two contributions. First, it does not require any feature extraction and enables robust PD detection. Second, we devise the pulse activation map. It provides interpretability of the results for the domain experts with the identification of the pulses that led to the detection of the PDs. The performance is evaluated on a public dataset for the detection of damaged power lines. An ablation study demonstrates the benefits of each part of the proposed framework.
Transferring Complementary Operating Conditions for Anomaly Detection
Aug 18, 2020
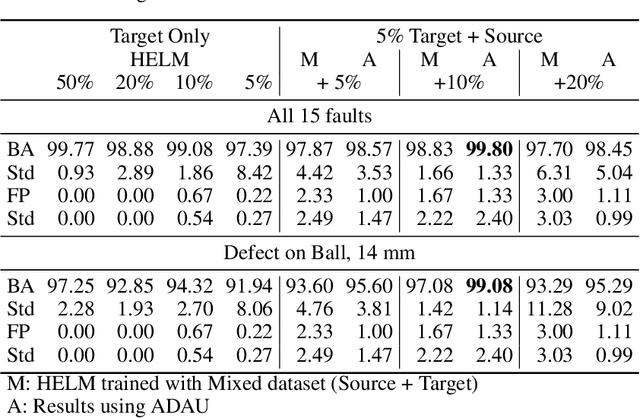
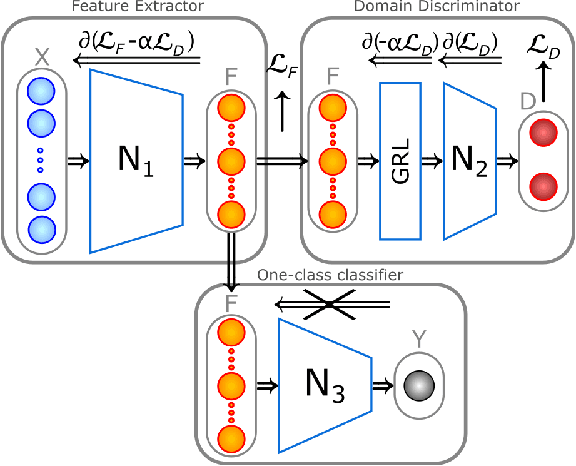
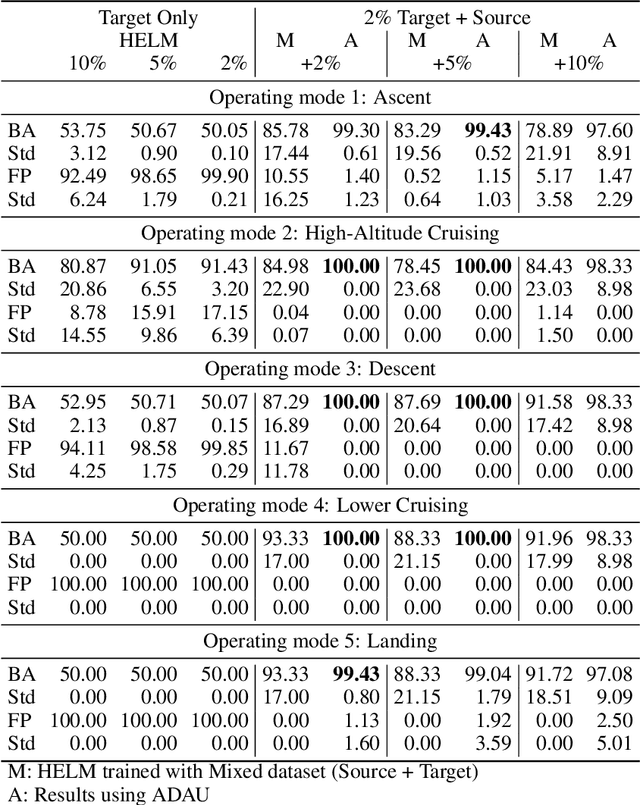
In complex industrial systems, the number of possible fault types is uncountable, making it impossible to train supervised models covering them all. Instead, anomaly detectors are trained on healthy operating condition data and raise an alarm when the data deviate from the healthy conditions, indicating the possible occurrence of faults. Data-driven anomaly detection performance relies on a representative collection of samples of the normal (healthy) class distribution. This means that the samples used to train the model should be sufficient in number and distributed so as to empirically determine the full healthy distribution. But for industrial systems in gradually varying environments or subject to changing usage, acquiring such a comprehensive set of samples would require a long collection period and delay the point at which the anomaly detector could be trained and operational. In this paper, we propose a framework for the transfer of complementary operating conditions between different units, to train more robust anomaly detectors. The domain shift due to different units' specificities needs to be accounted for. This problem is an extension of Unsupervised Domain Adaptation to the one-class classification task. We solve the problem with adversarial deep learning and replace the traditional classification loss, unavailable in one-class problems, with a new loss inspired by a dimensionality reduction tool. This loss enforces the conservation of the inherent variability of each dataset while the adversarial architecture ensures the alignment of the distributions, hence correcting the domain shift. We demonstrate the benefit of this approach using three open source datasets.
Time Series to Images: Monitoring the Condition of Industrial Assets with Deep Learning Image Processing Algorithms
May 19, 2020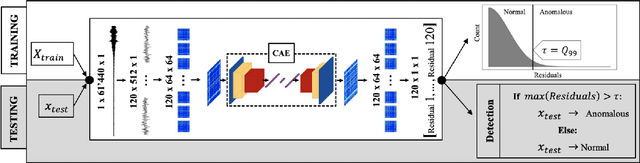
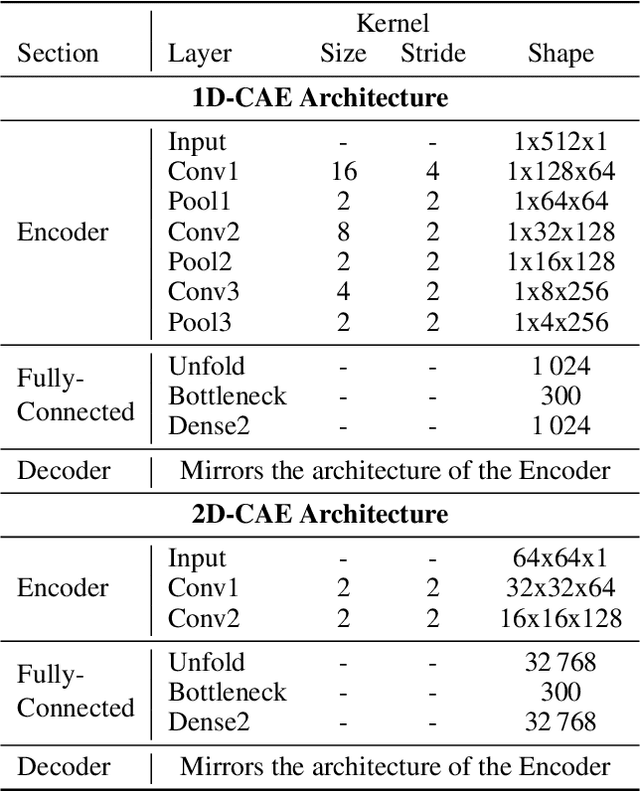
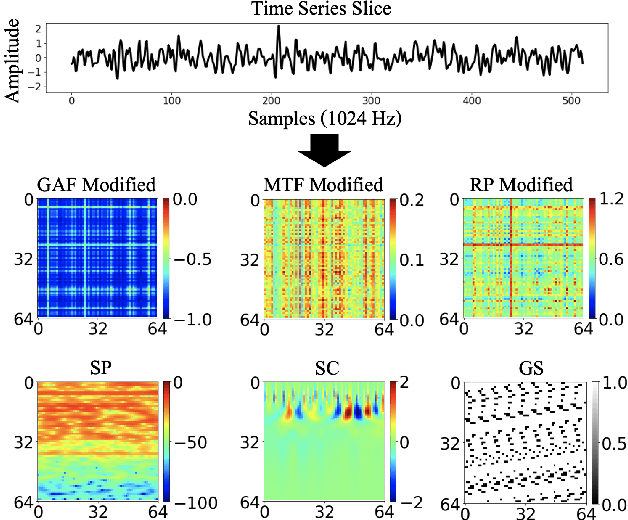
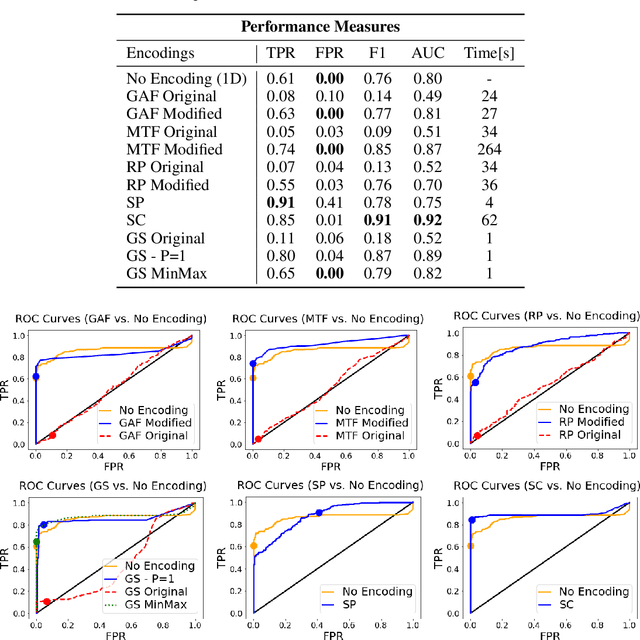
The ability to detect anomalies in time series is considered as highly valuable within plenty of application domains. The sequential nature of time series objects is responsible for an additional feature complexity, ultimately requiring specialized approaches for solving the task. Essential characteristics of time series, laying outside the time domain, are often difficult to capture with state-of-the-art anomaly detection methods, when no transformations on the time series have been applied. Inspired by the success of deep learning methods in computer vision, several studies have proposed to transform time-series into image-like representations, leading to very promising results. However, most of the previous studies implementing time-series to image encodings have focused on the supervised classification. The application to unsupervised anomaly detection tasks has been limited. The paper has the following contributions: First, we evaluate the application of six time-series to image encodings to DL algorithms: Gramian Angular Field, Markov Transition Field, Recurrence Plot, Grey Scale Encoding, Spectrogram and Scalogram. Second, we propose modifications of the original encoding definitions, to make them more robust to the variability in large datasets. And third, we provide a comprehensive comparison between using the raw time series directly and the different encodings, with and without the proposed improvements. The comparison is performed on a dataset collected and released by Airbus, containing highly complex vibration measurements from real helicopters flight tests. The different encodings provide competitive results for anomaly detection.
Anomaly Detection And Classification In Time Series With Kervolutional Neural Networks
May 14, 2020

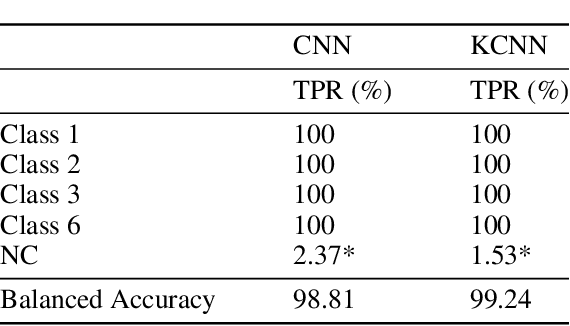
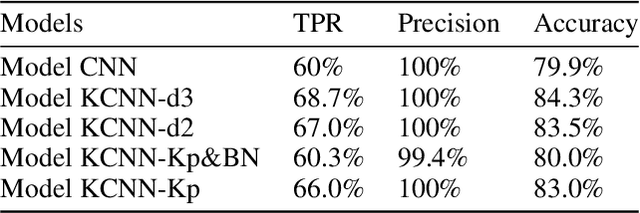
Recently, with the development of deep learning, end-to-end neural network architectures have been increasingly applied to condition monitoring signals. They have demonstrated superior performance for fault detection and classification, in particular using convolutional neural networks. Even more recently, an extension of the concept of convolution to the concept of kervolution has been proposed with some promising results in image classification tasks. In this paper, we explore the potential of kervolutional neural networks applied to time series data. We demonstrate that using a mixture of convolutional and kervolutional layers improves the model performance. The mixed model is first applied to a classification task in time series, as a benchmark dataset. Subsequently, the proposed mixed architecture is used to detect anomalies in time series data recorded by accelerometers on helicopters. We propose a residual-based anomaly detection approach using a temporal auto-encoder. We demonstrate that mixing kervolutional with convolutional layers in the encoder is more sensitive to variations in the input data and is able to detect anomalous time series in a better way.
Missing-Class-Robust Domain Adaptation by Unilateral Alignment for Fault Diagnosis
Jan 07, 2020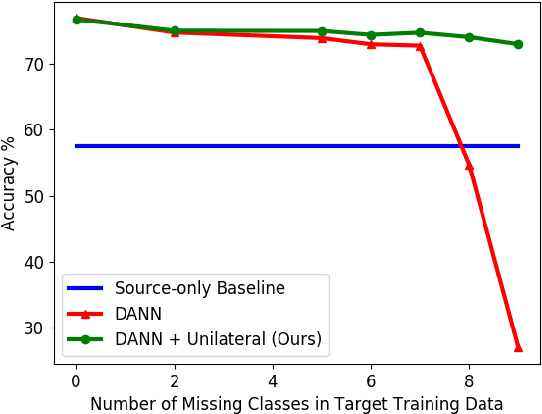
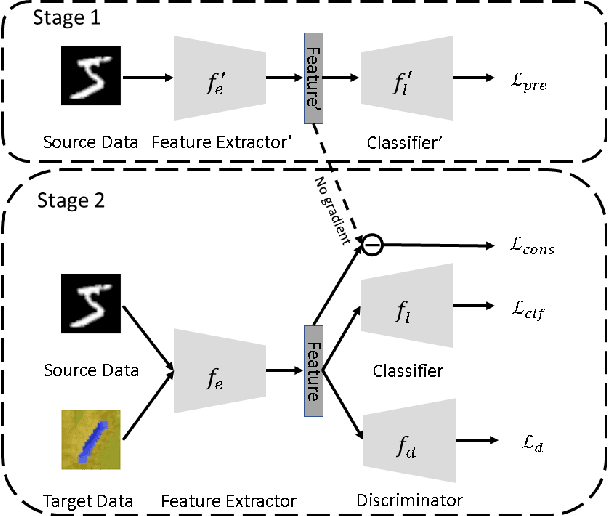
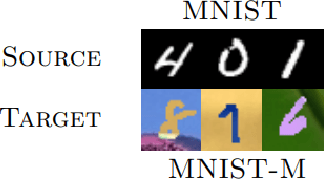

Domain adaptation aims at improving model performance by leveraging the learned knowledge in the source domain and transferring it to the target domain. Recently, domain adversarial methods have been particularly successful in alleviating the distribution shift between the source and the target domains. However, these methods assume an identical label space between the two domains. This assumption imposes a significant limitation for real applications since the target training set may not contain the complete set of classes. We demonstrate in this paper that the performance of domain adversarial methods can be vulnerable to an incomplete target label space during training. To overcome this issue, we propose a two-stage unilateral alignment approach. The proposed methodology makes use of the inter-class relationships of the source domain and aligns unilaterally the target to the source domain. The benefits of the proposed methodology are first evaluated on the MNIST$\rightarrow$MNIST-M adaptation task. The proposed methodology is also evaluated on a fault diagnosis task, where the problem of missing fault types in the target training dataset is common in practice. Both experiments demonstrate the effectiveness of the proposed methodology.
Fully Unsupervised Feature Alignment for Critical System Health Monitoring with Varied Operating Conditions
Jul 22, 2019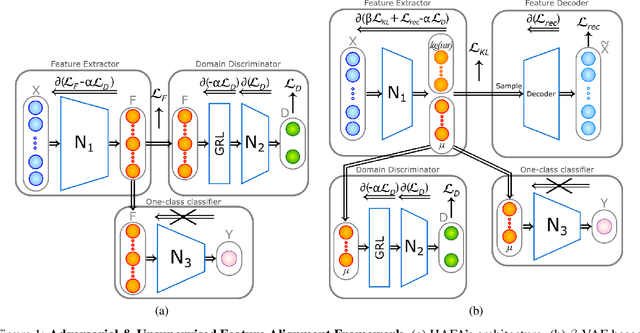
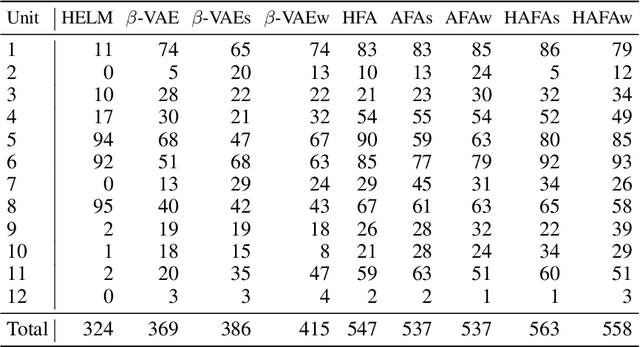

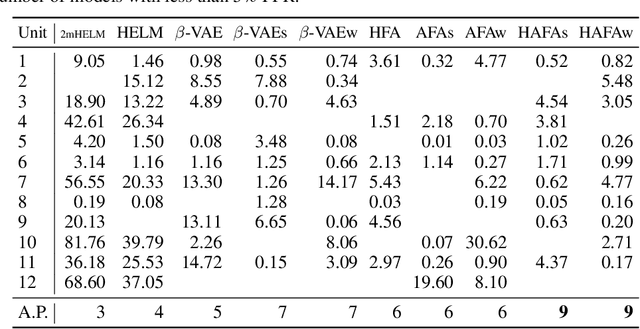
The failure of a complex and safety critical industrial asset can have extremely high consequences. Close monitoring for early detection of abnormal system conditions is therefore required. Data-driven solutions to this problem have been limited for two reasons: First, safety critical assets are designed and maintained to be highly reliable and faults are rare. Fault detection can thus not be supervised. Second, complex industrial systems usually have long lifetime and face very different operating conditions. Collecting a representative training dataset would require long observation periods, and delay the monitoring of the system. In this paper, we propose a methodology to monitor the systems in their early life. To do so, we enhance the training dataset with other units from a fleet, for which longer observations are available. Since each unit has its own specificity, we propose to extract features made independent of their origin by three unsupervised feature alignment techniques. First, using a variational encoder, we impose a shared latent space for both units. Second, we introduce a new loss designed to conserve inter-point spacial relationships between the input and the latent spaces. Last, we propose to train in an adversarial manner a discriminator on the origin of the features. Once aligned, the features are fed to a one-class classifier to monitor the health of the system. By exploring the different combinations of the proposed alignment strategies, and by testing them on a real case study, a fleet composed of 112 power plants operated in different geographical locations and under very different operating regimes, we demonstrate that this alignment is necessary and beneficial.