 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization of Deep Fault Detection Models in the Presence of Mislabeled Data
Paper and Code
Sep 30, 2020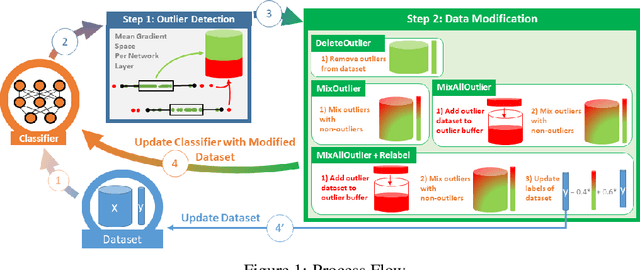

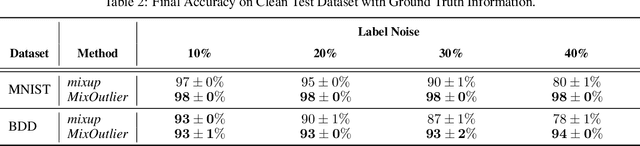
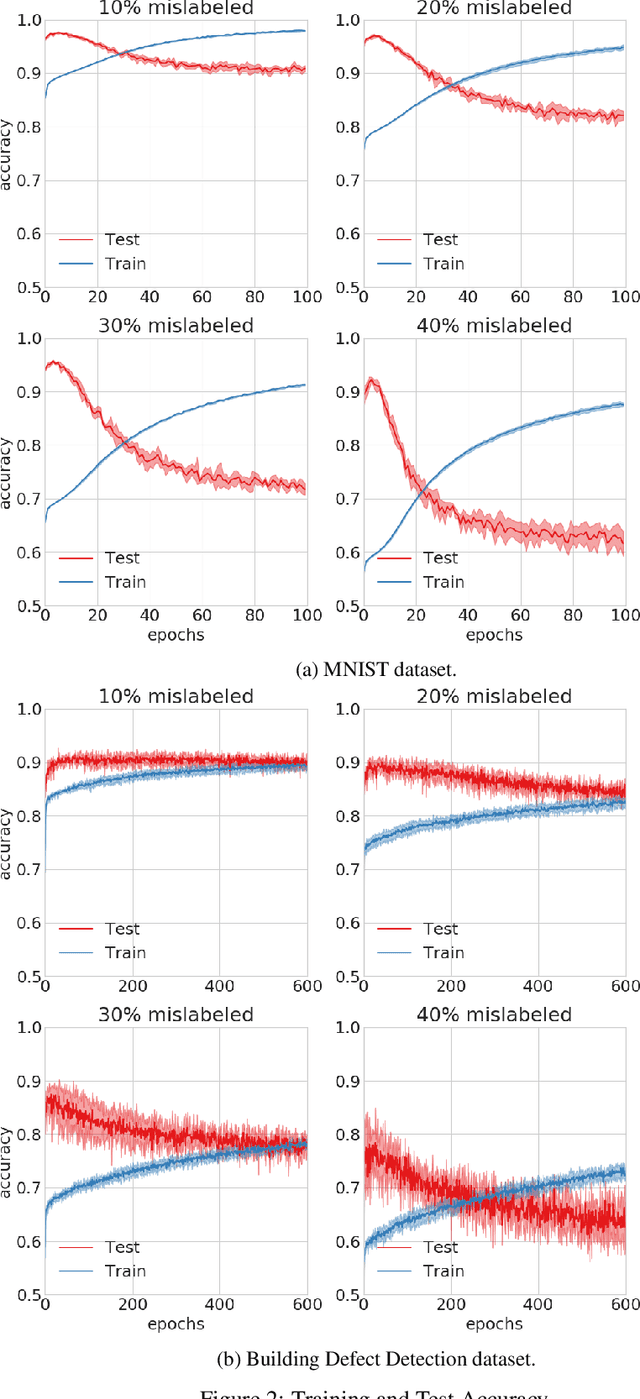
Mislabeled samples are ubiquitous in real-world datasets as rule-based or expert labeling is usually based on incorrect assumptions or subject to biased opinions. Neural networks can "memorize" these mislabeled samples and, as a result, exhibit poor generalization. This poses a critical issue in fault detection applications, where not only the training but also the validation datasets are prone to contain mislabeled samples. In this work, we propose a novel two-step framework for robust training with label noise. In the first step, we identify outliers (including the mislabeled samples) based on the update in the hypothesis space. In the second step, we propose different approaches to modifying the training data based on the identified outliers and a data augmentation technique. Contrary to previous approaches, we aim at finding a robust solution that is suitable for real-world applications, such as fault detection, where no clean, "noise-free" validation dataset is available. Under an approximate assumption about the upper limit of the label noise, we significantly improve the generalization ability of the model trained under massive label noise.