 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Retrieval at CheckThat! 2025: Identifying Scientific Papers from Implicit Social Media Mentions via Hybrid Retrieval and Re-Ranking
May 29, 2025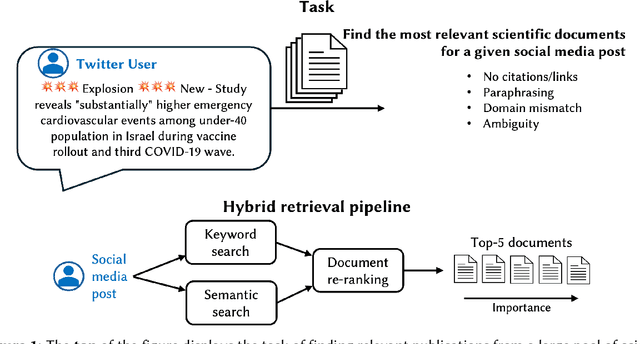
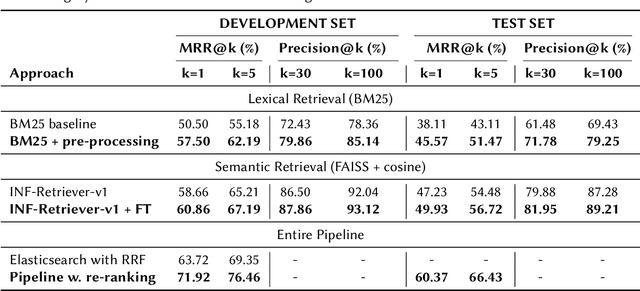
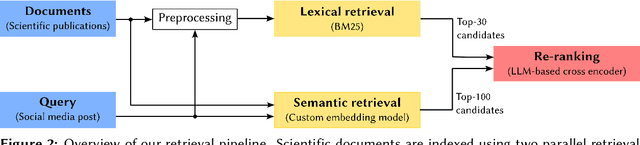
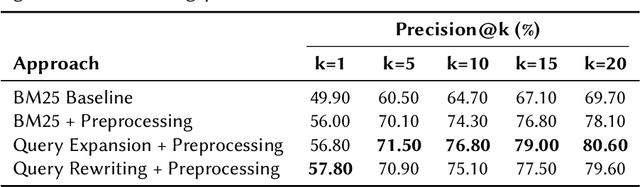
We present the methodology and results of the Deep Retrieval team for subtask 4b of the CLEF CheckThat! 2025 competition, which focuses on retrieving relevant scientific literature for given social media posts. To address this task, we propose a hybrid retrieval pipeline that combines lexical precision, semantic generalization, and deep contextual re-ranking, enabling robust retrieval that bridges the informal-to-formal language gap. Specifically, we combine BM25-based keyword matching with a FAISS vector store using a fine-tuned INF-Retriever-v1 model for dense semantic retrieval. BM25 returns the top 30 candidates, and semantic search yields 100 candidates, which are then merged and re-ranked via a large language model (LLM)-based cross-encoder. Our approach achieves a mean reciprocal rank at 5 (MRR@5) of 76.46% on the development set and 66.43% on the hidden test set, securing the 1st position on the development leaderboard and ranking 3rd on the test leaderboard (out of 31 teams), with a relative performance gap of only 2 percentage points compared to the top-ranked system. We achieve this strong performance by running open-source models locally and without external training data, highlighting the effectiveness of a carefully designed and fine-tuned retrieval pipeline.
Learning Actionable World Models for Industrial Process Control
Mar 03, 2025



To go from (passive) process monitoring to active process control, an effective AI system must learn about the behavior of the complex system from very limited training data, forming an ad-hoc digital twin with respect to process in- and outputs that captures the consequences of actions on the process's world. We propose a novel methodology based on learning world models that disentangles process parameters in the learned latent representation, allowing for fine-grained control. Representation learning is driven by the latent factors that influence the processes through contrastive learning within a joint embedding predictive architecture. This makes changes in representations predictable from changes in inputs and vice versa, facilitating interpretability of key factors responsible for process variations, paving the way for effective control actions to keep the process within operational bounds. The effectiveness of our method is validated on the example of plastic injection molding, demonstrating practical relevance in proposing specific control actions for a notoriously unstable process.
AI Agents for Computer Use: A Review of Instruction-based Computer Control, GUI Automation, and Operator Assistants
Jan 27, 2025



Instruction-based computer control agents (CCAs) execute complex action sequences on personal computers or mobile devices to fulfill tasks using the same graphical user interfaces as a human user would, provided instructions in natural language. This review offers a comprehensive overview of the emerging field of instruction-based computer control, examining available agents -- their taxonomy, development, and respective resources -- and emphasizing the shift from manually designed, specialized agents to leveraging foundation models such as large language models (LLMs) and vision-language models (VLMs). We formalize the problem and establish a taxonomy of the field to analyze agents from three perspectives: (a) the environment perspective, analyzing computer environments; (b) the interaction perspective, describing observations spaces (e.g., screenshots, HTML) and action spaces (e.g., mouse and keyboard actions, executable code); and (c) the agent perspective, focusing on the core principle of how an agent acts and learns to act. Our framework encompasses both specialized and foundation agents, facilitating their comparative analysis and revealing how prior solutions in specialized agents, such as an environment learning step, can guide the development of more capable foundation agents. Additionally, we review current CCA datasets and CCA evaluation methods and outline the challenges to deploying such agents in a productive setting. In total, we review and classify 86 CCAs and 33 related datasets. By highlighting trends, limitations, and future research directions, this work presents a comprehensive foundation to obtain a broad understanding of the field and push its future development.
The Dynamic Net Architecture: Learning Robust and Holistic Visual Representations Through Self-Organizing Networks
Jul 08, 2024



We present a novel intelligent-system architecture called "Dynamic Net Architecture" (DNA) that relies on recurrence-stabilized networks and discuss it in application to vision. Our architecture models a (cerebral cortical) area wherein elementary feature neurons encode details of visual structures, and coherent nets of such neurons model holistic object structures. By interpreting smaller or larger coherent pieces of an area network as complex features, our model encodes hierarchical feature representations essentially different than artificial neural networks (ANNs). DNA models operate on a dynamic connectionism principle, wherein neural activations stemming from initial afferent signals undergo stabilization through a self-organizing mechanism facilitated by Hebbian plasticity alongside periodically tightening inhibition. In contrast to ANNs, which rely on feed-forward connections and backpropagation of error, we posit that this processing paradigm leads to highly robust representations, as by employing dynamic lateral connections, irrelevant details in neural activations are filtered out, freeing further processing steps from distracting noise and premature decisions. We empirically demonstrate the viability of the DNA by composing line fragments into longer lines and show that the construction of nets representing lines remains robust even with the introduction of up to $59\%$ noise at each spatial location. Furthermore, we demonstrate the model's capability to reconstruct anticipated features from partially obscured inputs and that it can generalize to patterns not observed during training. In this work, we limit the DNA to one cortical area and focus on its internals while providing insights into a standalone area's strengths and shortcomings. Additionally, we provide an outlook on how future work can implement invariant object recognition by combining multiple areas.
MathNet: A Data-Centric Approach for Printed Mathematical Expression Recognition
Apr 21, 2024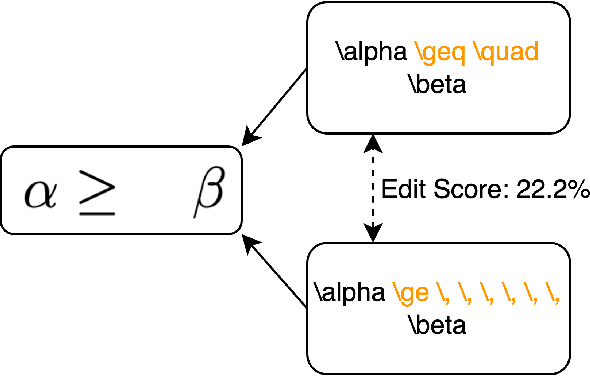
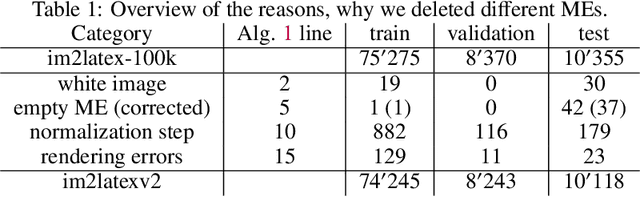
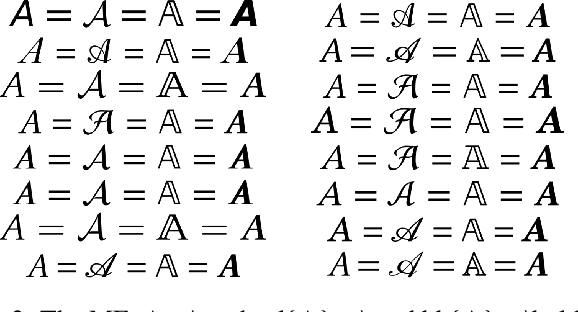
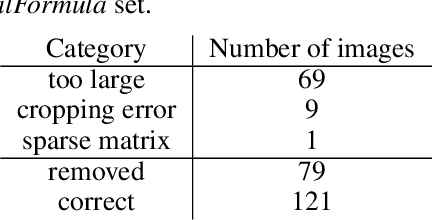
Printed mathematical expression recognition (MER) models are usually trained and tested using LaTeX-generated mathematical expressions (MEs) as input and the LaTeX source code as ground truth. As the same ME can be generated by various different LaTeX source codes, this leads to unwanted variations in the ground truth data that bias test performance results and hinder efficient learning. In addition, the use of only one font to generate the MEs heavily limits the generalization of the reported results to realistic scenarios. We propose a data-centric approach to overcome this problem, and present convincing experimental results: Our main contribution is an enhanced LaTeX normalization to map any LaTeX ME to a canonical form. Based on this process, we developed an improved version of the benchmark dataset im2latex-100k, featuring 30 fonts instead of one. Second, we introduce the real-world dataset realFormula, with MEs extracted from papers. Third, we developed a MER model, MathNet, based on a convolutional vision transformer, with superior results on all four test sets (im2latex-100k, im2latexv2, realFormula, and InftyMDB-1), outperforming the previous state of the art by up to 88.3%.
Efficient Rotation Invariance in Deep Neural Networks through Artificial Mental Rotation
Nov 14, 2023Humans and animals recognize objects irrespective of the beholder's point of view, which may drastically change their appearances. Artificial pattern recognizers also strive to achieve this, e.g., through translational invariance in convolutional neural networks (CNNs). However, both CNNs and vision transformers (ViTs) perform very poorly on rotated inputs. Here we present artificial mental rotation (AMR), a novel deep learning paradigm for dealing with in-plane rotations inspired by the neuro-psychological concept of mental rotation. Our simple AMR implementation works with all common CNN and ViT architectures. We test it on ImageNet, Stanford Cars, and Oxford Pet. With a top-1 error (averaged across datasets and architectures) of $0.743$, AMR outperforms the current state of the art (rotational data augmentation, average top-1 error of $0.626$) by $19\%$. We also easily transfer a trained AMR module to a downstream task to improve the performance of a pre-trained semantic segmentation model on rotated CoCo from $32.7$ to $55.2$ IoU.
Deep Neural Networks for Automatic Speaker Recognition Do Not Learn Supra-Segmental Temporal Features
Nov 02, 2023



While deep neural networks have shown impressive results in automatic speaker recognition and related tasks, it is dissatisfactory how little is understood about what exactly is responsible for these results. Part of the success has been attributed in prior work to their capability to model supra-segmental temporal information (SST), i.e., learn rhythmic-prosodic characteristics of speech in addition to spectral features. In this paper, we (i) present and apply a novel test to quantify to what extent the performance of state-of-the-art neural networks for speaker recognition can be explained by modeling SST; and (ii) present several means to force respective nets to focus more on SST and evaluate their merits. We find that a variety of CNN- and RNN-based neural network architectures for speaker recognition do not model SST to any sufficient degree, even when forced. The results provide a highly relevant basis for impactful future research into better exploitation of the full speech signal and give insights into the inner workings of such networks, enhancing explainability of deep learning for speech technologies.
A Comprehensive Survey of Deep Transfer Learning for Anomaly Detection in Industrial Time Series: Methods, Applications, and Directions
Jul 11, 2023



Automating the monitoring of industrial processes has the potential to enhance efficiency and optimize quality by promptly detecting abnormal events and thus facilitating timely interventions. Deep learning, with its capacity to discern non-trivial patterns within large datasets, plays a pivotal role in this process. Standard deep learning methods are suitable to solve a specific task given a specific type of data. During training, the algorithms demand large volumes of labeled training data. However, due to the dynamic nature of processes and the environment, it is impractical to acquire the needed data for standard deep learning training for every slightly different case anew. Deep transfer learning offers a solution to this problem. By leveraging knowledge from related tasks and accounting for variations in data distributions, this learning framework solves new tasks even with little or no additional labeled data. The approach bypasses the need to retrain a model from scratch for every new setup and dramatically reduces the labeled data requirement. This survey provides an in-depth review of deep transfer learning, examining the problem settings of transfer learning and classifying the prevailing deep transfer learning methods. Moreover, we delve into applying deep transfer learning in the context of a broad spectrum of time series anomaly detection tasks prevalent in primary industrial domains, e.g., manufacturing process monitoring, predictive maintenance, energy management, and infrastructure facility monitoring. We conclude this survey by underlining the challenges and limitations of deep transfer learning in industrial contexts. We also provide practical directions for solution design and implementation for these tasks, leading to specific, actionable suggestions.
Video object detection for privacy-preserving patient monitoring in intensive care
Jun 26, 2023Patient monitoring in intensive care units, although assisted by biosensors, needs continuous supervision of staff. To reduce the burden on staff members, IT infrastructures are built to record monitoring data and develop clinical decision support systems. These systems, however, are vulnerable to artifacts (e.g. muscle movement due to ongoing treatment), which are often indistinguishable from real and potentially dangerous signals. Video recordings could facilitate the reliable classification of biosignals using object detection (OD) methods to find sources of unwanted artifacts. Due to privacy restrictions, only blurred videos can be stored, which severely impairs the possibility to detect clinically relevant events such as interventions or changes in patient status with standard OD methods. Hence, new kinds of approaches are necessary that exploit every kind of available information due to the reduced information content of blurred footage and that are at the same time easily implementable within the IT infrastructure of a normal hospital. In this paper, we propose a new method for exploiting information in the temporal succession of video frames. To be efficiently implementable using off-the-shelf object detectors that comply with given hardware constraints, we repurpose the image color channels to account for temporal consistency, leading to an improved detection rate of the object classes. Our method outperforms a standard YOLOv5 baseline model by +1.7% mAP@.5 while also training over ten times faster on our proprietary dataset. We conclude that this approach has shown effectiveness in the preliminary experiments and holds potential for more general video OD in the future.
Trace and Detect Adversarial Attacks on CNNs using Feature Response Maps
Aug 24, 2022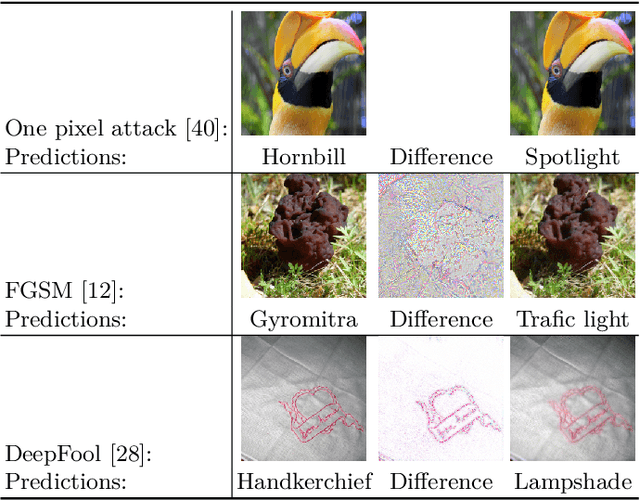
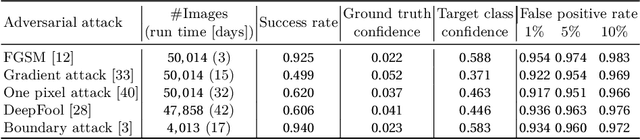

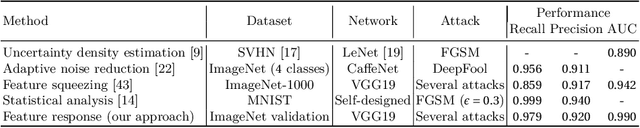
The existence of adversarial attacks on convolutional neural networks (CNN) questions the fitness of such models for serious applications. The attacks manipulate an input image such that misclassification is evoked while still looking normal to a human observer -- they are thus not easily detectable. In a different context, backpropagated activations of CNN hidden layers -- "feature responses" to a given input -- have been helpful to visualize for a human "debugger" what the CNN "looks at" while computing its output. In this work, we propose a novel detection method for adversarial examples to prevent attacks. We do so by tracking adversarial perturbations in feature responses, allowing for automatic detection using average local spatial entropy. The method does not alter the original network architecture and is fully human-interpretable. Experiments confirm the validity of our approach for state-of-the-art attacks on large-scale models trained on ImageNet.
* 13 pages, 6 figures