 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOGITAO: A Visual Reasoning Framework To Study Compositionality & Generalization
Sep 05, 2025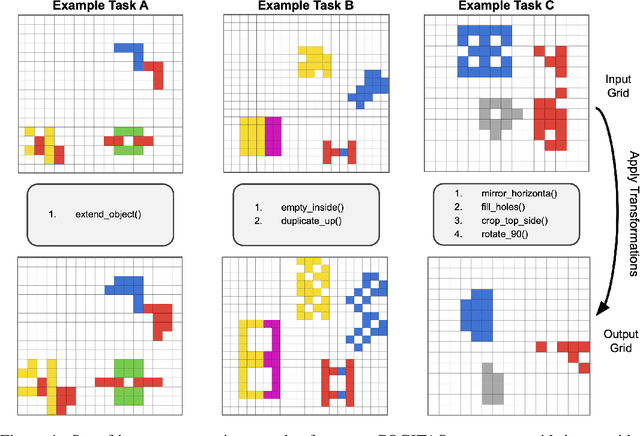
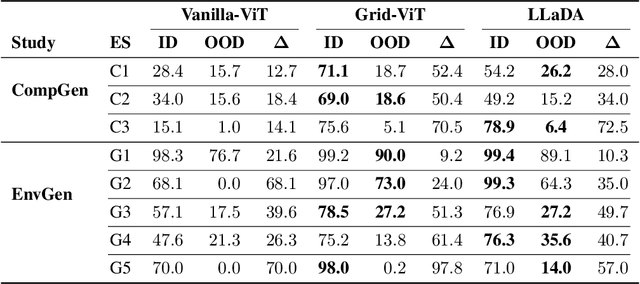
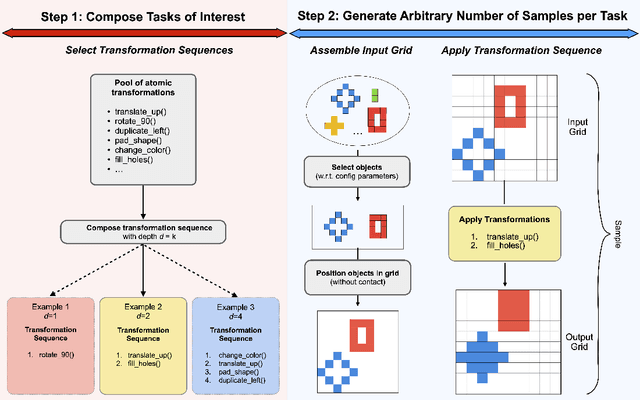
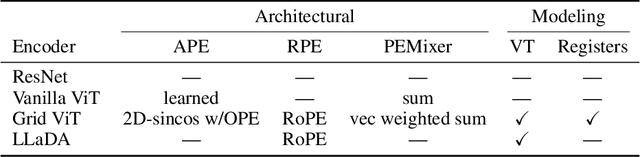
The ability to compose learned concepts and apply them in novel settings is key to human intelligence, but remains a persistent limitation in state-of-the-art machine learning models. To address this issue, we introduce COGITAO, a modular and extensible data generation framework and benchmark designed to systematically study compositionality and generalization in visual domains. Drawing inspiration from ARC-AGI's problem-setting, COGITAO constructs rule-based tasks which apply a set of transformations to objects in grid-like environments. It supports composition, at adjustable depth, over a set of 28 interoperable transformations, along with extensive control over grid parametrization and object properties. This flexibility enables the creation of millions of unique task rules -- surpassing concurrent datasets by several orders of magnitude -- across a wide range of difficulties, while allowing virtually unlimited sample generation per rule. We provide baseline experiments using state-of-the-art vision models, highlighting their consistent failures to generalize to novel combinations of familiar elements, despite strong in-domain performance. COGITAO is fully open-sourced, including all code and datasets, to support continued research in this field.
Efficient Rotation Invariance in Deep Neural Networks through Artificial Mental Rotation
Nov 14, 2023Humans and animals recognize objects irrespective of the beholder's point of view, which may drastically change their appearances. Artificial pattern recognizers also strive to achieve this, e.g., through translational invariance in convolutional neural networks (CNNs). However, both CNNs and vision transformers (ViTs) perform very poorly on rotated inputs. Here we present artificial mental rotation (AMR), a novel deep learning paradigm for dealing with in-plane rotations inspired by the neuro-psychological concept of mental rotation. Our simple AMR implementation works with all common CNN and ViT architectures. We test it on ImageNet, Stanford Cars, and Oxford Pet. With a top-1 error (averaged across datasets and architectures) of $0.743$, AMR outperforms the current state of the art (rotational data augmentation, average top-1 error of $0.626$) by $19\%$. We also easily transfer a trained AMR module to a downstream task to improve the performance of a pre-trained semantic segmentation model on rotated CoCo from $32.7$ to $55.2$ IoU.
Video object detection for privacy-preserving patient monitoring in intensive care
Jun 26, 2023Patient monitoring in intensive care units, although assisted by biosensors, needs continuous supervision of staff. To reduce the burden on staff members, IT infrastructures are built to record monitoring data and develop clinical decision support systems. These systems, however, are vulnerable to artifacts (e.g. muscle movement due to ongoing treatment), which are often indistinguishable from real and potentially dangerous signals. Video recordings could facilitate the reliable classification of biosignals using object detection (OD) methods to find sources of unwanted artifacts. Due to privacy restrictions, only blurred videos can be stored, which severely impairs the possibility to detect clinically relevant events such as interventions or changes in patient status with standard OD methods. Hence, new kinds of approaches are necessary that exploit every kind of available information due to the reduced information content of blurred footage and that are at the same time easily implementable within the IT infrastructure of a normal hospital. In this paper, we propose a new method for exploiting information in the temporal succession of video frames. To be efficiently implementable using off-the-shelf object detectors that comply with given hardware constraints, we repurpose the image color channels to account for temporal consistency, leading to an improved detection rate of the object classes. Our method outperforms a standard YOLOv5 baseline model by +1.7% mAP@.5 while also training over ten times faster on our proprietary dataset. We conclude that this approach has shown effectiveness in the preliminary experiments and holds potential for more general video OD in the future.
Is it Enough to Optimize CNN Architectures on ImageNet?
Mar 16, 2021
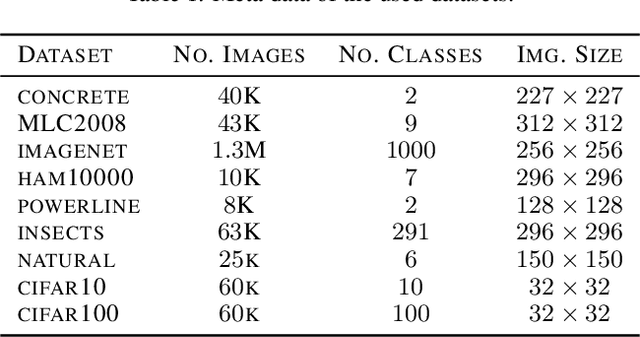


An implicit but pervasive hypothesis of modern computer vision research is that convolutional neural network (CNN) architectures that perform better on ImageNet will also perform better on other vision datasets. We challenge this hypothesis through an extensive empirical study for which we train 500 sampled CNN architectures on ImageNet as well as 8 other image classification datasets from a wide array of application domains. The relationship between architecture and performance varies wildly, depending on the datasets. For some of them, the performance correlation with ImageNet is even negative. Clearly, it is not enough to optimize architectures solely for ImageNet when aiming for progress that is relevant for all applications. Therefore, we identify two dataset-specific performance indicators: the cumulative width across layers as well as the total depth of the network. Lastly, we show that the range of dataset variability covered by ImageNet can be significantly extended by adding ImageNet subsets restricted to few classes.
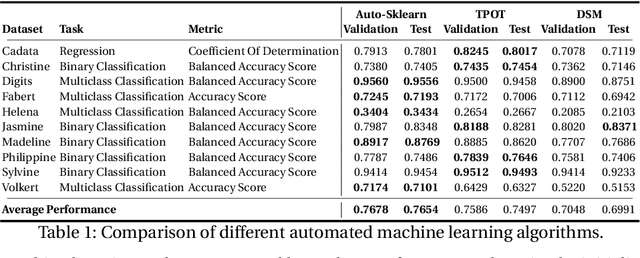
Automated Machine Learning in Practice: State of the Art and Recent Results
Jul 19, 2019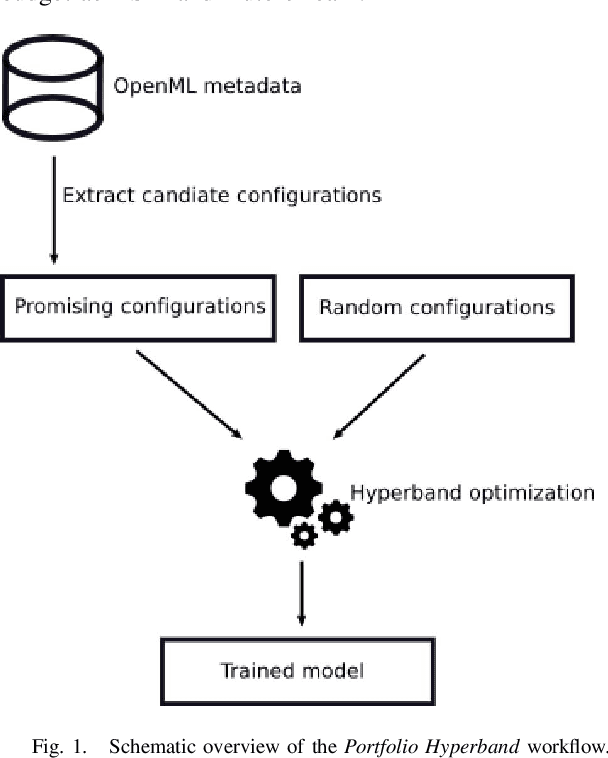
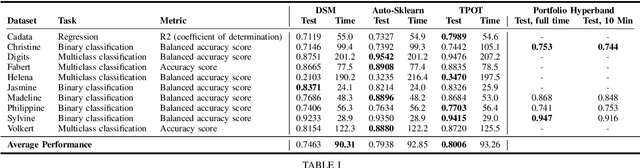
A main driver behind the digitization of industry and society is the belief that data-driven model building and decision making can contribute to higher degrees of automation and more informed decisions. Building such models from data often involves the application of some form of machine learning. Thus, there is an ever growing demand in work force with the necessary skill set to do so. This demand has given rise to a new research topic concerned with fitting machine learning models fully automatically - AutoML. This paper gives an overview of the state of the art in AutoML with a focus on practical applicability in a business context, and provides recent benchmark results on the most important AutoML algorithms.
DeepScores and Deep Watershed Detection: current state and open issues
Oct 12, 2018

This paper gives an overview of our current Optical Music Recognition (OMR) research. We recently released the OMR dataset \emph{DeepScores} as well as the object detection method \emph{Deep Watershed Detector}. We are currently taking some additional steps to improve both of them. Here we summarize current and future efforts, aimed at improving usefulness on real-world task and tackling extreme class imbalance.
Deep Learning in the Wild
Jul 13, 2018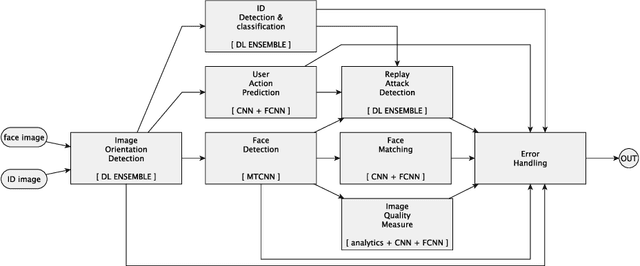


Deep learning with neural networks is applied by an increasing number of people outside of classic research environments, due to the vast success of the methodology on a wide range of machine perception tasks. While this interest is fueled by beautiful success stories, practical work in deep learning on novel tasks without existing baselines remains challenging. This paper explores the specific challenges arising in the realm of real world tasks, based on case studies from research \& development in conjunction with industry, and extracts lessons learned from them. It thus fills a gap between the publication of latest algorithmic and methodical developments, and the usually omitted nitty-gritty of how to make them work. Specifically, we give insight into deep learning projects on face matching, print media monitoring, industrial quality control, music scanning, strategy game playing, and automated machine learning, thereby providing best practices for deep learning in practice.
Deep Watershed Detector for Music Object Recognition
May 26, 2018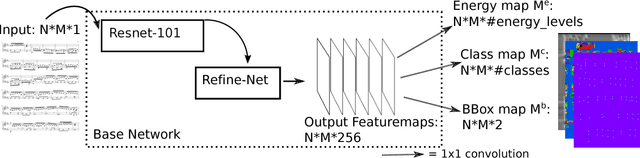
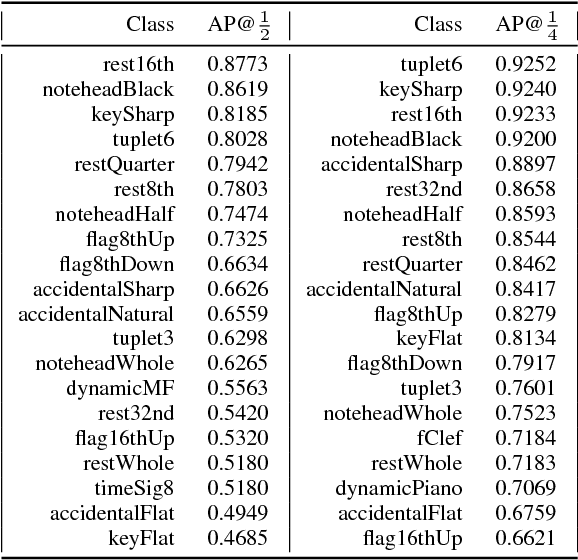
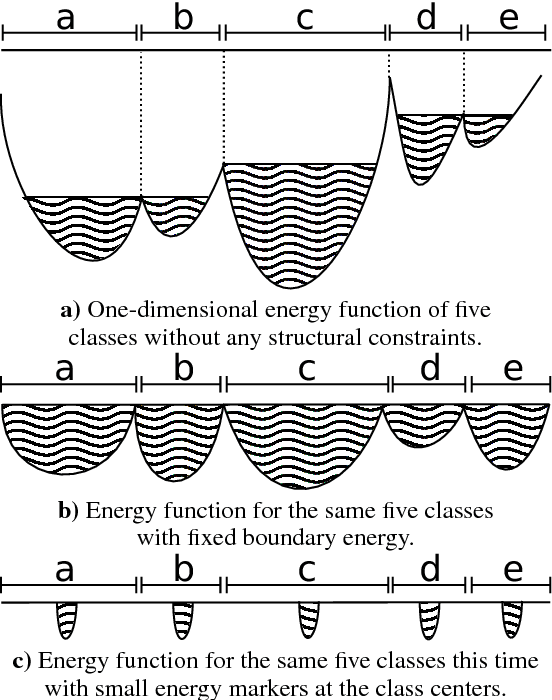
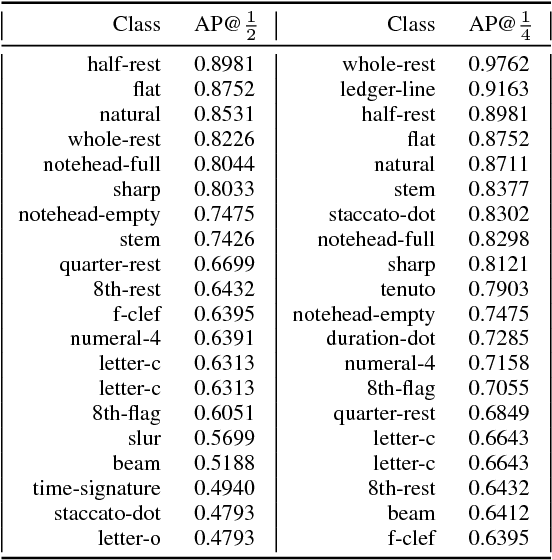
Optical Music Recognition (OMR) is an important and challenging area within music information retrieval, the accurate detection of music symbols in digital images is a core functionality of any OMR pipeline. In this paper, we introduce a novel object detection method, based on synthetic energy maps and the watershed transform, called Deep Watershed Detector (DWD). Our method is specifically tailored to deal with high resolution images that contain a large number of very small objects and is therefore able to process full pages of written music. We present state-of-the-art detection results of common music symbols and show DWD's ability to work with synthetic scores equally well as on handwritten music.
DeepScores -- A Dataset for Segmentation, Detection and Classification of Tiny Objects
May 26, 2018



We present the DeepScores dataset with the goal of advancing the state-of-the-art in small objects recognition, and by placing the question of object recognition in the context of scene understanding. DeepScores contains high quality images of musical scores, partitioned into 300,000 sheets of written music that contain symbols of different shapes and sizes. With close to a hundred millions of small objects, this makes our dataset not only unique, but also the largest public dataset. DeepScores comes with ground truth for object classification, detection and semantic segmentation. DeepScores thus poses a relevant challenge for computer vision in general, beyond the scope of optical music recognition (OMR) research. We present a detailed statistical analysis of the dataset, comparing it with other computer vision datasets like Caltech101/256, PASCAL VOC, SUN, SVHN, ImageNet, MS-COCO, smaller computer vision datasets, as well as with other OMR datasets. Finally, we provide baseline performances for object classification and give pointers to future research based on this dataset.