 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it Enough to Optimize CNN Architectures on ImageNet?
Paper and Code

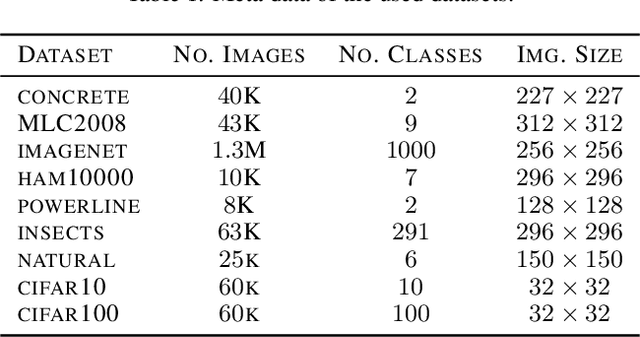


An implicit but pervasive hypothesis of modern computer vision research is that convolutional neural network (CNN) architectures that perform better on ImageNet will also perform better on other vision datasets. We challenge this hypothesis through an extensive empirical study for which we train 500 sampled CNN architectures on ImageNet as well as 8 other image classification datasets from a wide array of application domains. The relationship between architecture and performance varies wildly, depending on the datasets. For some of them, the performance correlation with ImageNet is even negative. Clearly, it is not enough to optimize architectures solely for ImageNet when aiming for progress that is relevant for all applications. Therefore, we identify two dataset-specific performance indicators: the cumulative width across layers as well as the total depth of the network. Lastly, we show that the range of dataset variability covered by ImageNet can be significantly extended by adding ImageNet subsets restricted to few classes.