 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Centric Anthropomorphic 3D CT Phantom-Based Benchmark Dataset for Harmonization
Jul 02, 2025Artificial intelligence (AI) has introduced numerous opportunities for human assistance and task automation in medicine. However, it suffers from poor generalization in the presence of shifts in the data distribution. In the context of AI-based computed tomography (CT) analysis, significant data distribution shifts can be caused by changes in scanner manufacturer, reconstruction technique or dose. AI harmonization techniques can address this problem by reducing distribution shifts caused by various acquisition settings. This paper presents an open-source benchmark dataset containing CT scans of an anthropomorphic phantom acquired with various scanners and settings, which purpose is to foster the development of AI harmonization techniques. Using a phantom allows fixing variations attributed to inter- and intra-patient variations. The dataset includes 1378 image series acquired with 13 scanners from 4 manufacturers across 8 institutions using a harmonized protocol as well as several acquisition doses. Additionally, we present a methodology, baseline results and open-source code to assess image- and feature-level stability and liver tissue classification, promoting the development of AI harmonization strategies.
Artifact Reduction in 3D and 4D Cone-beam Computed Tomography Images with Deep Learning -- A Review
Mar 27, 2024Deep learning based approaches have been used to improve image quality in cone-beam computed tomography (CBCT), a medical imaging technique often used in applications such as image-guided radiation therapy, implant dentistry or orthopaedics. In particular, while deep learning methods have been applied to reduce various types of CBCT image artifacts arising from motion, metal objects, or low-dose acquisition, a comprehensive review summarizing the successes and shortcomings of these approaches, with a primary focus on the type of artifacts rather than the architecture of neural networks, is lacking in the literature. In this review, the data generation and simulation pipelines, and artifact reduction techniques are specifically investigated for each type of artifact. We provide an overview of deep learning techniques that have successfully been shown to reduce artifacts in 3D, as well as in time-resolved (4D) CBCT through the use of projection- and/or volume-domain optimizations, or by introducing neural networks directly within the CBCT reconstruction algorithms. Research gaps are identified to suggest avenues for future exploration. One of the key findings of this work is an observed trend towards the use of generative models including GANs and score-based or diffusion models, accompanied with the need for more diverse and open training datasets and simulations.
* 16 pages, 4 figures, 1 Table, published in IEEE Access Journal
Deep Learning for Robust and Explainable Models in Computer Vision
Mar 27, 2024Recent breakthroughs in machine and deep learning (ML and DL) research have provided excellent tools for leveraging enormous amounts of data and optimizing huge models with millions of parameters to obtain accurate networks for image processing. These developments open up tremendous opportunities for using artificial intelligence (AI) in the automation and human assisted AI industry. However, as more and more models are deployed and used in practice, many challenges have emerged. This thesis presents various approaches that address robustness and explainability challenges for using ML and DL in practice. Robustness and reliability are the critical components of any model before certification and deployment in practice. Deep convolutional neural networks (CNNs) exhibit vulnerability to transformations of their inputs, such as rotation and scaling, or intentional manipulations as described in the adversarial attack literature. In addition, building trust in AI-based models requires a better understanding of current models and developing methods that are more explainable and interpretable a priori. This thesis presents developments in computer vision models' robustness and explainability. Furthermore, this thesis offers an example of using vision models' feature response visualization (models' interpretations) to improve robustness despite interpretability and robustness being seemingly unrelated in the related research. Besides methodological developments for robust and explainable vision models, a key message of this thesis is introducing model interpretation techniques as a tool for understanding vision models and improving their design and robustness. In addition to the theoretical developments, this thesis demonstrates several applications of ML and DL in different contexts, such as medical imaging and affective computing.
* 150 pages, 37 figures, 12 tables
Trace and Detect Adversarial Attacks on CNNs using Feature Response Maps
Aug 24, 2022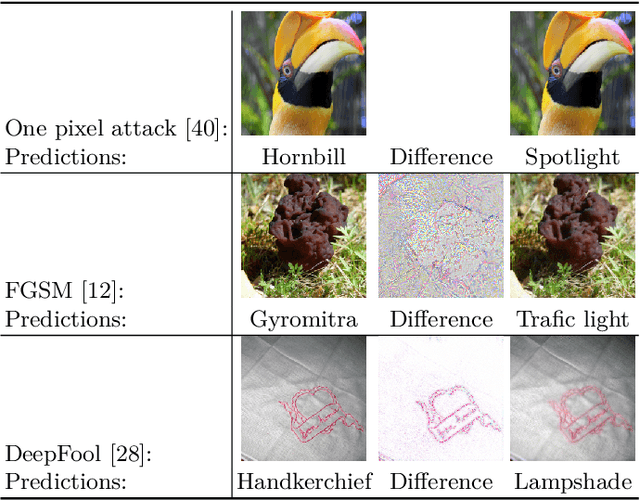
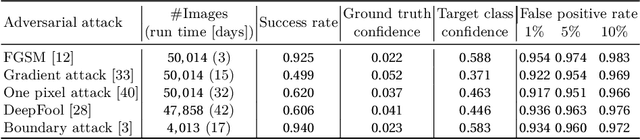

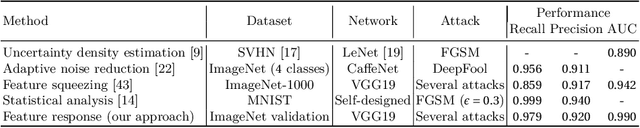
The existence of adversarial attacks on convolutional neural networks (CNN) questions the fitness of such models for serious applications. The attacks manipulate an input image such that misclassification is evoked while still looking normal to a human observer -- they are thus not easily detectable. In a different context, backpropagated activations of CNN hidden layers -- "feature responses" to a given input -- have been helpful to visualize for a human "debugger" what the CNN "looks at" while computing its output. In this work, we propose a novel detection method for adversarial examples to prevent attacks. We do so by tracking adversarial perturbations in feature responses, allowing for automatic detection using average local spatial entropy. The method does not alter the original network architecture and is fully human-interpretable. Experiments confirm the validity of our approach for state-of-the-art attacks on large-scale models trained on ImageNet.
* 13 pages, 6 figures
Radial Basis Function Networks for Convolutional Neural Networks to Learn Similarity Distance Metric and Improve Interpretability
Aug 24, 2022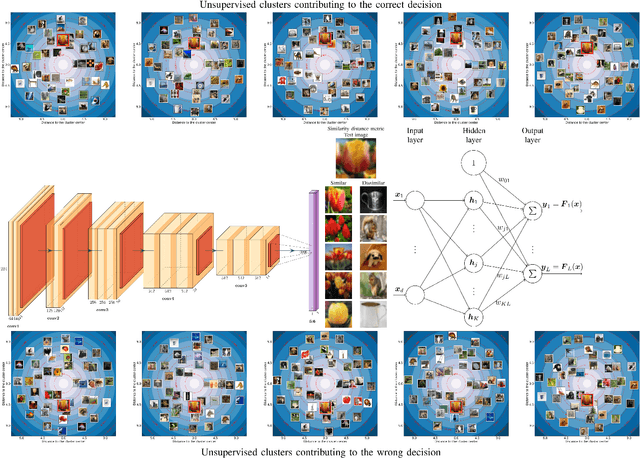
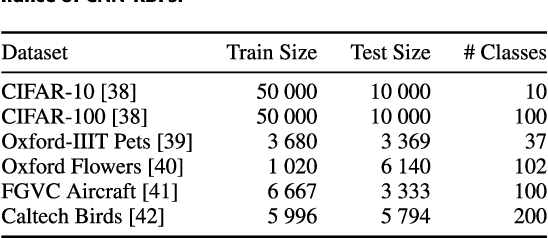
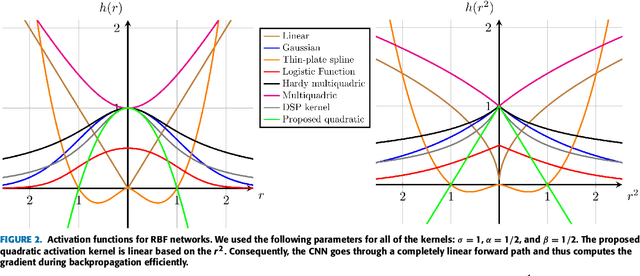
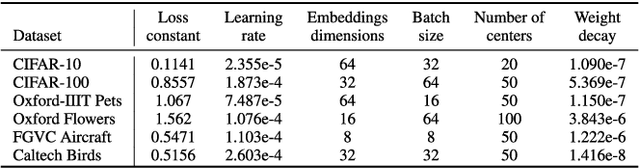
Radial basis function neural networks (RBFs) are prime candidates for pattern classification and regression and have been used extensively in classical machine learning applications. However, RBFs have not been integrated into contemporary deep learning research and computer vision using conventional convolutional neural networks (CNNs) due to their lack of adaptability with modern architectures. In this paper, we adapt RBF networks as a classifier on top of CNNs by modifying the training process and introducing a new activation function to train modern vision architectures end-to-end for image classification. The specific architecture of RBFs enables the learning of a similarity distance metric to compare and find similar and dissimilar images. Furthermore, we demonstrate that using an RBF classifier on top of any CNN architecture provides new human-interpretable insights about the decision-making process of the models. Finally, we successfully apply RBFs to a range of CNN architectures and evaluate the results on benchmark computer vision datasets.
* 12 pages, 8 figures
PrepNet: A Convolutional Auto-Encoder to Homogenize CT Scans for Cross-Dataset Medical Image Analysis
Aug 19, 2022
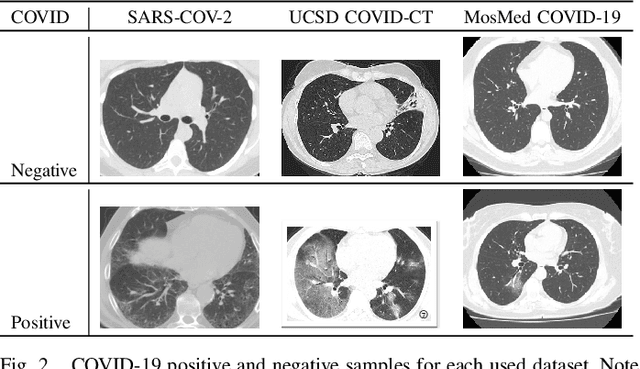
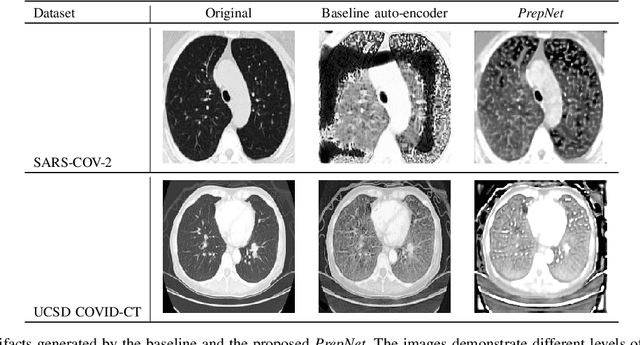
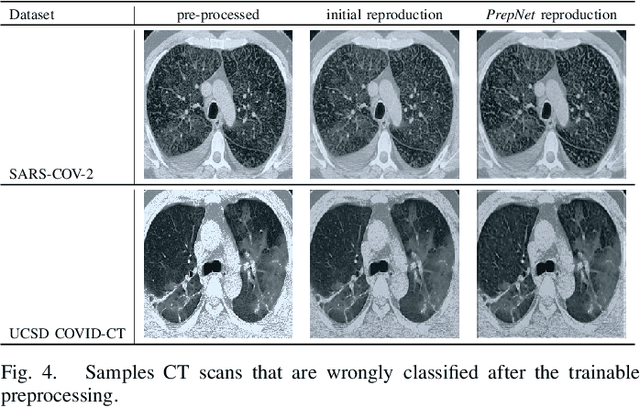
With the spread of COVID-19 over the world, the need arose for fast and precise automatic triage mechanisms to decelerate the spread of the disease by reducing human efforts e.g. for image-based diagnosis. Although the literature has shown promising efforts in this direction, reported results do not consider the variability of CT scans acquired under varying circumstances, thus rendering resulting models unfit for use on data acquired using e.g. different scanner technologies. While COVID-19 diagnosis can now be done efficiently using PCR tests, this use case exemplifies the need for a methodology to overcome data variability issues in order to make medical image analysis models more widely applicable. In this paper, we explicitly address the variability issue using the example of COVID-19 diagnosis and propose a novel generative approach that aims at erasing the differences induced by e.g. the imaging technology while simultaneously introducing minimal changes to the CT scans through leveraging the idea of deep auto-encoders. The proposed prepossessing architecture (PrepNet) (i) is jointly trained on multiple CT scan datasets and (ii) is capable of extracting improved discriminative features for improved diagnosis. Experimental results on three public datasets (SARS-COVID-2, UCSD COVID-CT, MosMed) show that our model improves cross-dataset generalization by up to $11.84$ percentage points despite a minor drop in within dataset performance.
* 7 pages 4 figures peer reviewed and published in IEEE EMBS Regional Conference on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI 2021)
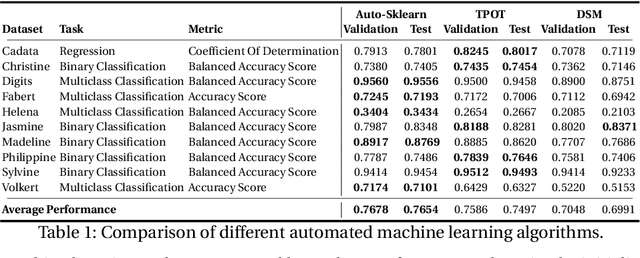
Automated Machine Learning in Practice: State of the Art and Recent Results
Jul 19, 2019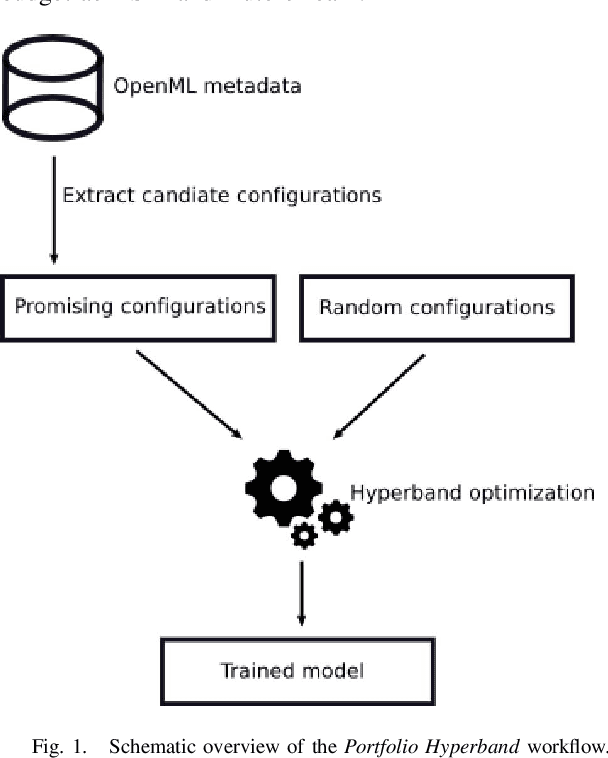
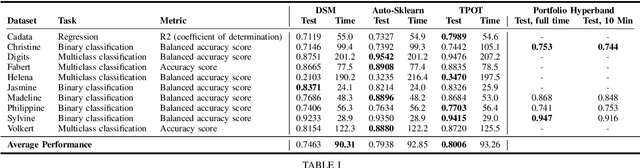
A main driver behind the digitization of industry and society is the belief that data-driven model building and decision making can contribute to higher degrees of automation and more informed decisions. Building such models from data often involves the application of some form of machine learning. Thus, there is an ever growing demand in work force with the necessary skill set to do so. This demand has given rise to a new research topic concerned with fitting machine learning models fully automatically - AutoML. This paper gives an overview of the state of the art in AutoML with a focus on practical applicability in a business context, and provides recent benchmark results on the most important AutoML algorithms.
Deep Learning in the Wild
Jul 13, 2018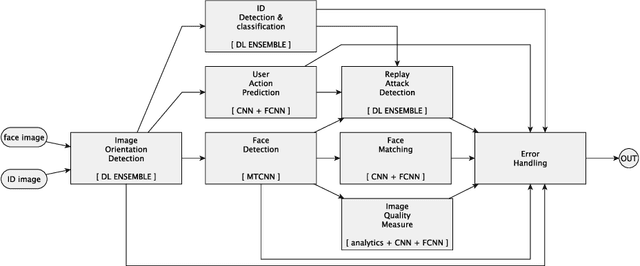


Deep learning with neural networks is applied by an increasing number of people outside of classic research environments, due to the vast success of the methodology on a wide range of machine perception tasks. While this interest is fueled by beautiful success stories, practical work in deep learning on novel tasks without existing baselines remains challenging. This paper explores the specific challenges arising in the realm of real world tasks, based on case studies from research \& development in conjunction with industry, and extracts lessons learned from them. It thus fills a gap between the publication of latest algorithmic and methodical developments, and the usually omitted nitty-gritty of how to make them work. Specifically, we give insight into deep learning projects on face matching, print media monitoring, industrial quality control, music scanning, strategy game playing, and automated machine learning, thereby providing best practices for deep learning in practice.
Learning Neural Models for End-to-End Clustering
Jul 11, 2018
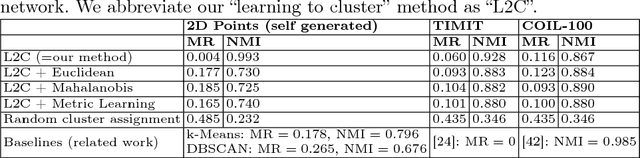
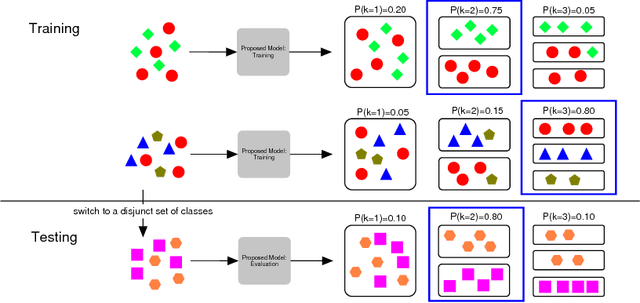
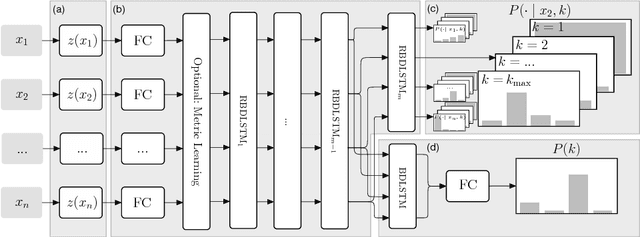
We propose a novel end-to-end neural network architecture that, once trained, directly outputs a probabilistic clustering of a batch of input examples in one pass. It estimates a distribution over the number of clusters $k$, and for each $1 \leq k \leq k_\mathrm{max}$, a distribution over the individual cluster assignment for each data point. The network is trained in advance in a supervised fashion on separate data to learn grouping by any perceptual similarity criterion based on pairwise labels (same/different group). It can then be applied to different data containing different groups. We demonstrate promising performance on high-dimensional data like images (COIL-100) and speech (TIMIT). We call this ``learning to cluster'' and show its conceptual difference to deep metric learning, semi-supervise clustering and other related approaches while having the advantage of performing learnable clustering fully end-to-end.