 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathNet: A Data-Centric Approach for Printed Mathematical Expression Recognition
Paper and Code
Apr 21, 2024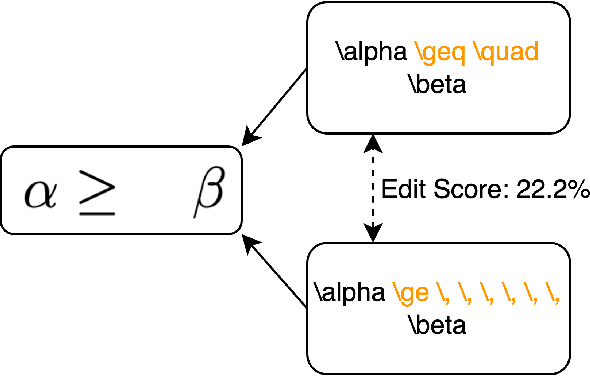
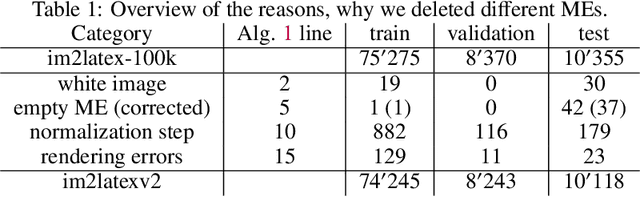
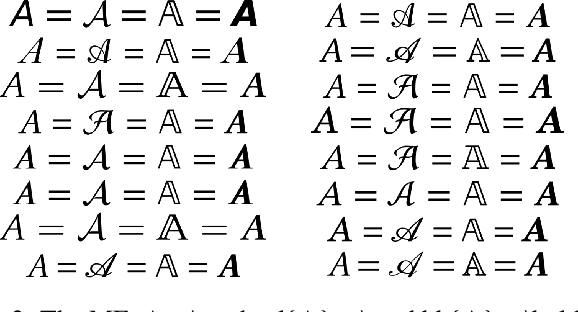
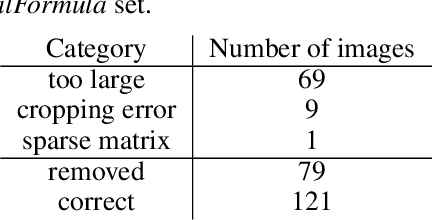
Printed mathematical expression recognition (MER) models are usually trained and tested using LaTeX-generated mathematical expressions (MEs) as input and the LaTeX source code as ground truth. As the same ME can be generated by various different LaTeX source codes, this leads to unwanted variations in the ground truth data that bias test performance results and hinder efficient learning. In addition, the use of only one font to generate the MEs heavily limits the generalization of the reported results to realistic scenarios. We propose a data-centric approach to overcome this problem, and present convincing experimental results: Our main contribution is an enhanced LaTeX normalization to map any LaTeX ME to a canonical form. Based on this process, we developed an improved version of the benchmark dataset im2latex-100k, featuring 30 fonts instead of one. Second, we introduce the real-world dataset realFormula, with MEs extracted from papers. Third, we developed a MER model, MathNet, based on a convolutional vision transformer, with superior results on all four test sets (im2latex-100k, im2latexv2, realFormula, and InftyMDB-1), outperforming the previous state of the art by up to 88.3%.