 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trajectory Bundle Method: Unifying Sequential-Convex Programming and Sampling-Based Trajectory Optimization
Sep 30, 2025



We present a unified framework for solving trajectory optimization problems in a derivative-free manner through the use of sequential convex programming. Traditionally, nonconvex optimization problems are solved by forming and solving a sequence of convex optimization problems, where the cost and constraint functions are approximated locally through Taylor series expansions. This presents a challenge for functions where differentiation is expensive or unavailable. In this work, we present a derivative-free approach to form these convex approximations by computing samples of the dynamics, cost, and constraint functions and letting the solver interpolate between them. Our framework includes sample-based trajectory optimization techniques like model-predictive path integral (MPPI) control as a special case and generalizes them to enable features like multiple shooting and general equality and inequality constraints that are traditionally associated with derivative-based sequential convex programming methods. The resulting framework is simple, flexible, and capable of solving a wide variety of practical motion planning and control problems.
A Comparison of Imitation Learning Algorithms for Bimanual Manipulation
Aug 13, 2024



Amidst the wide popularity of imitation learning algorithms in robotics, their properties regarding hyperparameter sensitivity, ease of training, data efficiency, and performance have not been well-studied in high-precision industry-inspired environments. In this work, we demonstrate the limitations and benefits of prominent imitation learning approaches and analyze their capabilities regarding these properties. We evaluate each algorithm on a complex bimanual manipulation task involving an over-constrained dynamics system in a setting involving multiple contacts between the manipulated object and the environment. While we find that imitation learning is well suited to solve such complex tasks, not all algorithms are equal in terms of handling environmental and hyperparameter perturbations, training requirements, performance, and ease of use. We investigate the empirical influence of these key characteristics by employing a carefully designed experimental procedure and learning environment. Paper website: https://bimanual-imitation.github.io/
GenCHiP: Generating Robot Policy Code for High-Precision and Contact-Rich Manipulation Tasks
Apr 09, 2024



Large Language Models (LLMs) have been successful at generating robot policy code, but so far these results have been limited to high-level tasks that do not require precise movement. It is an open question how well such approaches work for tasks that require reasoning over contact forces and working within tight success tolerances. We find that, with the right action space, LLMs are capable of successfully generating policies for a variety of contact-rich and high-precision manipulation tasks, even under noisy conditions, such as perceptual errors or grasping inaccuracies. Specifically, we reparameterize the action space to include compliance with constraints on the interaction forces and stiffnesses involved in reaching a target pose. We validate this approach on subtasks derived from the Functional Manipulation Benchmark (FMB) and NIST Task Board Benchmarks. Exposing this action space alongside methods for estimating object poses improves policy generation with an LLM by greater than 3x and 4x when compared to non-compliant action spaces
RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches
Mar 05, 2024



Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings. For supplementary material and videos, please refer to our website: http://rt-sketch.github.io.
SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning
Feb 01, 2024In recent years, significant progress has been made in the field of robotic reinforcement learning (RL), enabling methods that handle complex image observations, train in the real world, and incorporate auxiliary data, such as demonstrations and prior experience. However, despite these advances, robotic RL remains hard to use. It is acknowledged among practitioners that the particular implementation details of these algorithms are often just as important (if not more so) for performance as the choice of algorithm. We posit that a significant challenge to widespread adoption of robotic RL, as well as further development of robotic RL methods, is the comparative inaccessibility of such methods. To address this challenge, we developed a carefully implemented library containing a sample efficient off-policy deep RL method, together with methods for computing rewards and resetting the environment, a high-quality controller for a widely-adopted robot, and a number of challenging example tasks. We provide this library as a resource for the community, describe its design choices, and present experimental results. Perhaps surprisingly, we find that our implementation can achieve very efficient learning, acquiring policies for PCB board assembly, cable routing, and object relocation between 25 to 50 minutes of training per policy on average, improving over state-of-the-art results reported for similar tasks in the literature. These policies achieve perfect or near-perfect success rates, extreme robustness even under perturbations, and exhibit emergent recovery and correction behaviors. We hope that these promising results and our high-quality open-source implementation will provide a tool for the robotics community to facilitate further developments in robotic RL. Our code, documentation, and videos can be found at https://serl-robot.github.io/
Efficient Online Learning of Contact Force Models for Connector Insertion
Dec 14, 2023Contact-rich manipulation tasks with stiff frictional elements like connector insertion are difficult to model with rigid-body simulators. In this work, we propose a new approach for modeling these environments by learning a quasi-static contact force model instead of a full simulator. Using a feature vector that contains information about the configuration and control, we find a linear mapping adequately captures the relationship between this feature vector and the sensed contact forces. A novel Linear Model Learning (LML) algorithm is used to solve for the globally optimal mapping in real time without any matrix inversions, resulting in an algorithm that runs in nearly constant time on a GPU as the model size increases. We validate the proposed approach for connector insertion both in simulation and hardware experiments, where the learned model is combined with an optimization-based controller to achieve smooth insertions in the presence of misalignments and uncertainty. Our website featuring videos, code, and more materials is available at https://model-based-plugging.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Multi-Stage Cable Routing through Hierarchical Imitation Learning
Jul 23, 2023



We study the problem of learning to perform multi-stage robotic manipulation tasks, with applications to cable routing, where the robot must route a cable through a series of clips. This setting presents challenges representative of complex multi-stage robotic manipulation scenarios: handling deformable objects, closing the loop on visual perception, and handling extended behaviors consisting of multiple steps that must be executed successfully to complete the entire task. In such settings, learning individual primitives for each stage that succeed with a high enough rate to perform a complete temporally extended task is impractical: if each stage must be completed successfully and has a non-negligible probability of failure, the likelihood of successful completion of the entire task becomes negligible. Therefore, successful controllers for such multi-stage tasks must be able to recover from failure and compensate for imperfections in low-level controllers by smartly choosing which controllers to trigger at any given time, retrying, or taking corrective action as needed. To this end, we describe an imitation learning system that uses vision-based policies trained from demonstrations at both the lower (motor control) and the upper (sequencing) level, present a system for instantiating this method to learn the cable routing task, and perform evaluations showing great performance in generalizing to very challenging clip placement variations. Supplementary videos, datasets, and code can be found at https://sites.google.com/view/cablerouting.
Prim-LAfD: A Framework to Learn and Adapt Primitive-Based Skills from Demonstrations for Insertion Tasks
Dec 02, 2022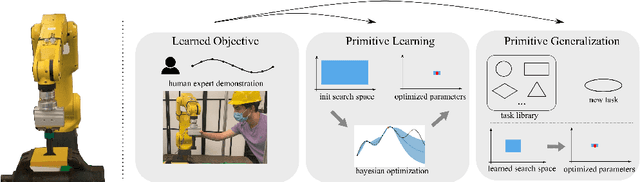

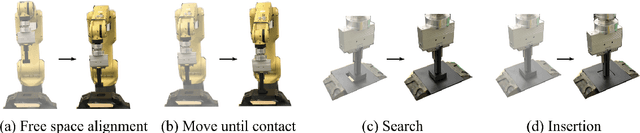

Learning generalizable insertion skills in a data-efficient manner has long been a challenge in the robot learning community. While the current state-of-the-art methods with reinforcement learning (RL) show promising performance in acquiring manipulation skills, the algorithms are data-hungry and hard to generalize. To overcome the issues, in this paper we present Prim-LAfD, a simple yet effective framework to learn and adapt primitive-based insertion skills from demonstrations. Prim-LAfD utilizes black-box function optimization to learn and adapt the primitive parameters leveraging prior experiences. Human demonstrations are modeled as dense rewards guiding parameter learning. We validate the effectiveness of the proposed method on eight peg-hole and connector-socket insertion tasks. The experimental results show that our proposed framework takes less than one hour to acquire the insertion skills and as few as fifteen minutes to adapt to an unseen insertion task on a physical robot.
Zero-Shot Policy Transfer with Disentangled Task Representation of Meta-Reinforcement Learning
Oct 01, 2022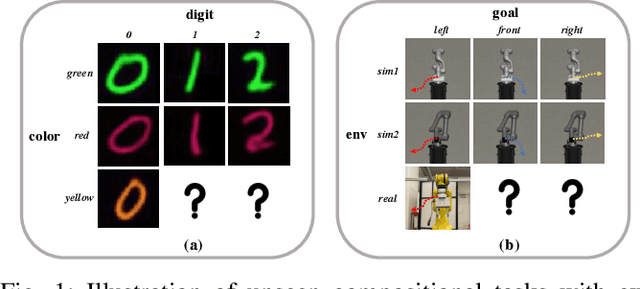
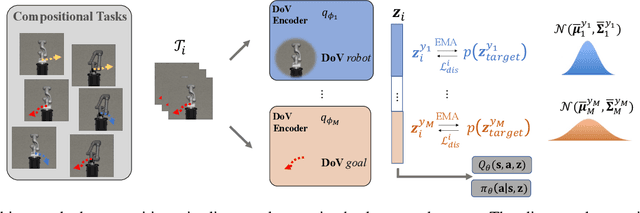

Humans are capable of abstracting various tasks as different combinations of multiple attributes. This perspective of compositionality is vital for human rapid learning and adaption since previous experiences from related tasks can be combined to generalize across novel compositional settings. In this work, we aim to achieve zero-shot policy generalization of Reinforcement Learning (RL) agents by leveraging the task compositionality. Our proposed method is a meta- RL algorithm with disentangled task representation, explicitly encoding different aspects of the tasks. Policy generalization is then performed by inferring unseen compositional task representations via the obtained disentanglement without extra exploration. The evaluation is conducted on three simulated tasks and a challenging real-world robotic insertion task. Experimental results demonstrate that our proposed method achieves policy generalization to unseen compositional tasks in a zero-shot manner.