 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Curvatures Estimation with Applications to Single Cell Data
Feb 06, 2025



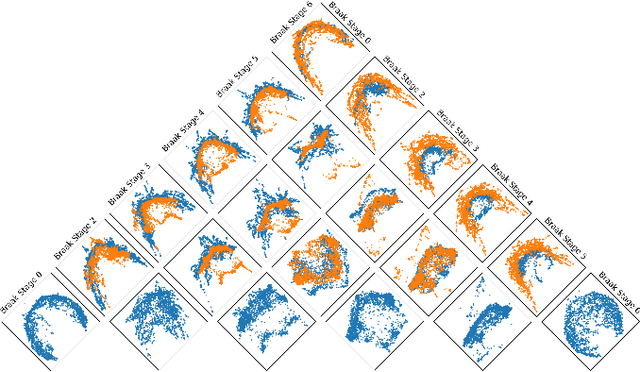
The rapidly growing field of single-cell transcriptomic sequencing (scRNAseq) presents challenges for data analysis due to its massive datasets. A common method in manifold learning consists in hypothesizing that datasets lie on a lower dimensional manifold. This allows to study the geometry of point clouds by extracting meaningful descriptors like curvature. In this work, we will present Adaptive Local PCA (AdaL-PCA), a data-driven method for accurately estimating various notions of intrinsic curvature on data manifolds, in particular principal curvatures for surfaces. The model relies on local PCA to estimate the tangent spaces. The evaluation of AdaL-PCA on sampled surfaces shows state-of-the-art results. Combined with a PHATE embedding, the model applied to single-cell RNA sequencing data allows us to identify key variations in the cellular differentiation.
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
Dec 13, 2024Recent advances in robotic foundation models have enabled the development of generalist policies that can adapt to diverse tasks. While these models show impressive flexibility, their performance heavily depends on the quality of their training data. In this work, we propose Reinforcement Learning Distilled Generalists (RLDG), a method that leverages reinforcement learning to generate high-quality training data for finetuning generalist policies. Through extensive real-world experiments on precise manipulation tasks like connector insertion and assembly, we demonstrate that generalist policies trained with RL-generated data consistently outperform those trained with human demonstrations, achieving up to 40% higher success rates while generalizing better to new tasks. We also provide a detailed analysis that reveals this performance gain stems from both optimized action distributions and improved state coverage. Our results suggest that combining task-specific RL with generalist policy distillation offers a promising approach for developing more capable and efficient robotic manipulation systems that maintain the flexibility of foundation models while achieving the performance of specialized controllers. Videos and code can be found on our project website https://generalist-distillation.github.io
Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning
Oct 29, 2024Reinforcement learning (RL) holds great promise for enabling autonomous acquisition of complex robotic manipulation skills, but realizing this potential in real-world settings has been challenging. We present a human-in-the-loop vision-based RL system that demonstrates impressive performance on a diverse set of dexterous manipulation tasks, including dynamic manipulation, precision assembly, and dual-arm coordination. Our approach integrates demonstrations and human corrections, efficient RL algorithms, and other system-level design choices to learn policies that achieve near-perfect success rates and fast cycle times within just 1 to 2.5 hours of training. We show that our method significantly outperforms imitation learning baselines and prior RL approaches, with an average 2x improvement in success rate and 1.8x faster execution. Through extensive experiments and analysis, we provide insights into the effectiveness of our approach, demonstrating how it learns robust, adaptive policies for both reactive and predictive control strategies. Our results suggest that RL can indeed learn a wide range of complex vision-based manipulation policies directly in the real world within practical training times. We hope this work will inspire a new generation of learned robotic manipulation techniques, benefiting both industrial applications and research advancements. Videos and code are available at our project website https://hil-serl.github.io/.
Hyperedge Representations with Hypergraph Wavelets: Applications to Spatial Transcriptomics
Sep 14, 2024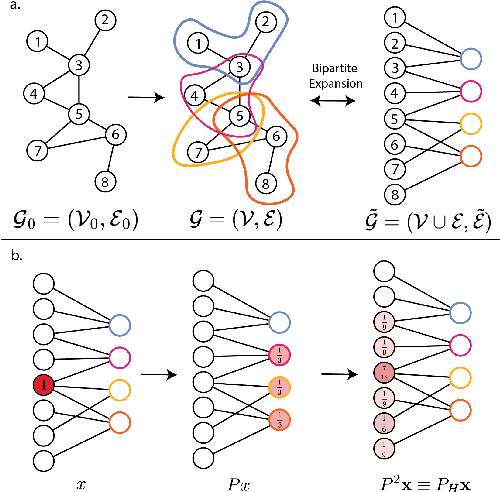
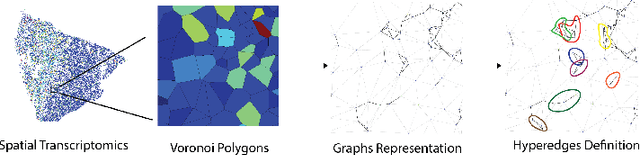
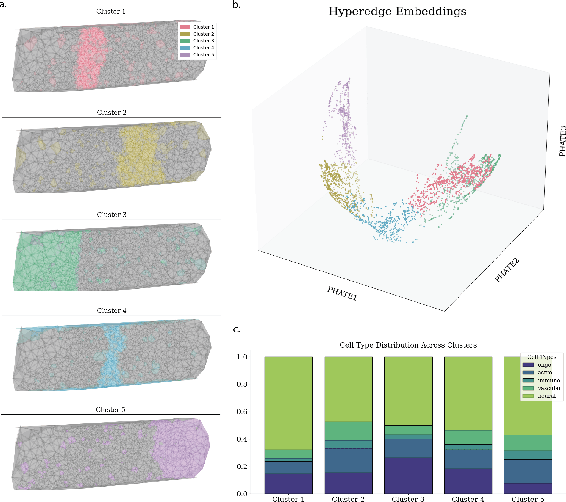
In many data-driven applications, higher-order relationships among multiple objects are essential in capturing complex interactions. Hypergraphs, which generalize graphs by allowing edges to connect any number of nodes, provide a flexible and powerful framework for modeling such higher-order relationships. In this work, we introduce hypergraph diffusion wavelets and describe their favorable spectral and spatial properties. We demonstrate their utility for biomedical discovery in spatially resolved transcriptomics by applying the method to represent disease-relevant cellular niches for Alzheimer's disease.
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
SERL: A Software Suite for Sample-Efficient Robotic Reinforcement Learning
Feb 01, 2024In recent years, significant progress has been made in the field of robotic reinforcement learning (RL), enabling methods that handle complex image observations, train in the real world, and incorporate auxiliary data, such as demonstrations and prior experience. However, despite these advances, robotic RL remains hard to use. It is acknowledged among practitioners that the particular implementation details of these algorithms are often just as important (if not more so) for performance as the choice of algorithm. We posit that a significant challenge to widespread adoption of robotic RL, as well as further development of robotic RL methods, is the comparative inaccessibility of such methods. To address this challenge, we developed a carefully implemented library containing a sample efficient off-policy deep RL method, together with methods for computing rewards and resetting the environment, a high-quality controller for a widely-adopted robot, and a number of challenging example tasks. We provide this library as a resource for the community, describe its design choices, and present experimental results. Perhaps surprisingly, we find that our implementation can achieve very efficient learning, acquiring policies for PCB board assembly, cable routing, and object relocation between 25 to 50 minutes of training per policy on average, improving over state-of-the-art results reported for similar tasks in the literature. These policies achieve perfect or near-perfect success rates, extreme robustness even under perturbations, and exhibit emergent recovery and correction behaviors. We hope that these promising results and our high-quality open-source implementation will provide a tool for the robotics community to facilitate further developments in robotic RL. Our code, documentation, and videos can be found at https://serl-robot.github.io/
FMB: a Functional Manipulation Benchmark for Generalizable Robotic Learning
Jan 16, 2024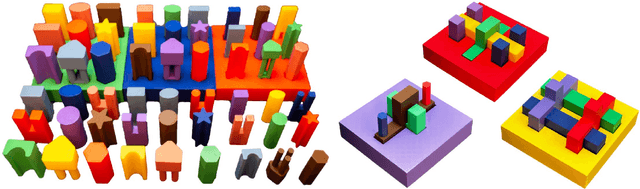


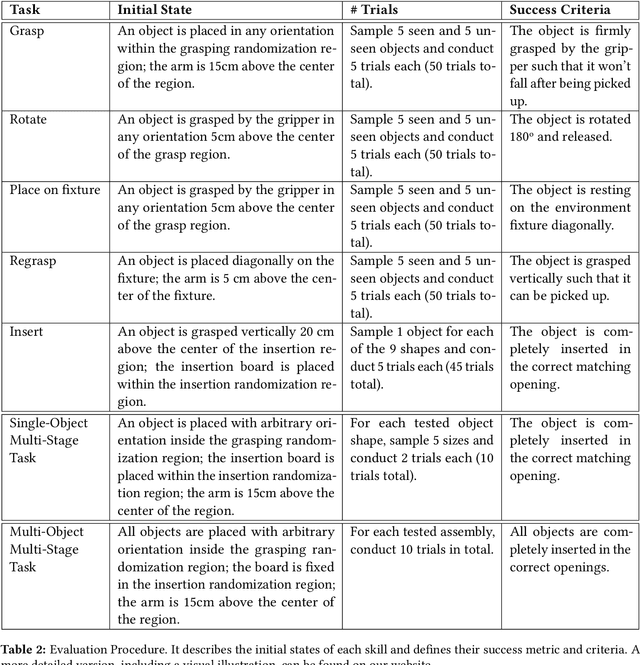
In this paper, we propose a real-world benchmark for studying robotic learning in the context of functional manipulation: a robot needs to accomplish complex long-horizon behaviors by composing individual manipulation skills in functionally relevant ways. The core design principles of our Functional Manipulation Benchmark (FMB) emphasize a harmonious balance between complexity and accessibility. Tasks are deliberately scoped to be narrow, ensuring that models and datasets of manageable scale can be utilized effectively to track progress. Simultaneously, they are diverse enough to pose a significant generalization challenge. Furthermore, the benchmark is designed to be easily replicable, encompassing all essential hardware and software components. To achieve this goal, FMB consists of a variety of 3D-printed objects designed for easy and accurate replication by other researchers. The objects are procedurally generated, providing a principled framework to study generalization in a controlled fashion. We focus on fundamental manipulation skills, including grasping, repositioning, and a range of assembly behaviors. The FMB can be used to evaluate methods for acquiring individual skills, as well as methods for combining and ordering such skills to solve complex, multi-stage manipulation tasks. We also offer an imitation learning framework that includes a suite of policies trained to solve the proposed tasks. This enables researchers to utilize our tasks as a versatile toolkit for examining various parts of the pipeline. For example, researchers could propose a better design for a grasping controller and evaluate it in combination with our baseline reorientation and assembly policies as part of a pipeline for solving multi-stage tasks. Our dataset, object CAD files, code, and evaluation videos can be found on our project website: https://functional-manipulation-benchmark.github.io
BLIS-Net: Classifying and Analyzing Signals on Graphs
Oct 26, 2023Graph neural networks (GNNs) have emerged as a powerful tool for tasks such as node classification and graph classification. However, much less work has been done on signal classification, where the data consists of many functions (referred to as signals) defined on the vertices of a single graph. These tasks require networks designed differently from those designed for traditional GNN tasks. Indeed, traditional GNNs rely on localized low-pass filters, and signals of interest may have intricate multi-frequency behavior and exhibit long range interactions. This motivates us to introduce the BLIS-Net (Bi-Lipschitz Scattering Net), a novel GNN that builds on the previously introduced geometric scattering transform. Our network is able to capture both local and global signal structure and is able to capture both low-frequency and high-frequency information. We make several crucial changes to the original geometric scattering architecture which we prove increase the ability of our network to capture information about the input signal and show that BLIS-Net achieves superior performance on both synthetic and real-world data sets based on traffic flow and fMRI data.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Graph topological property recovery with heat and wave dynamics-based features on graphs
Sep 19, 2023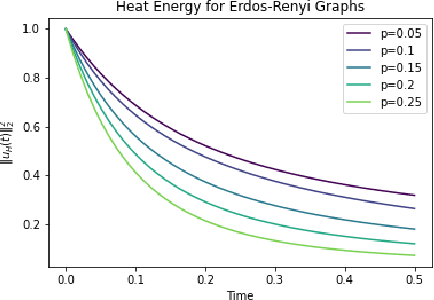
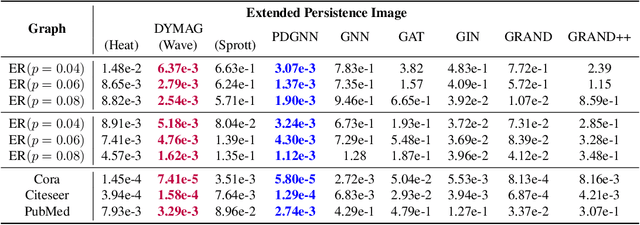
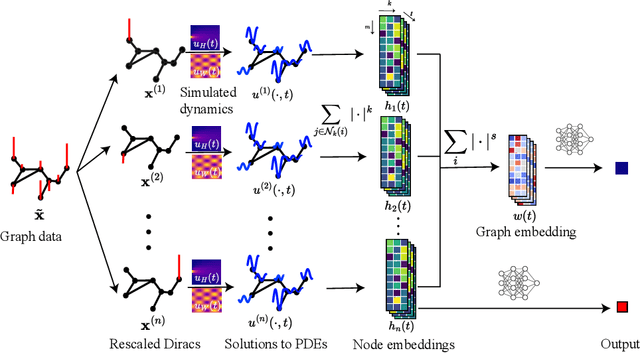
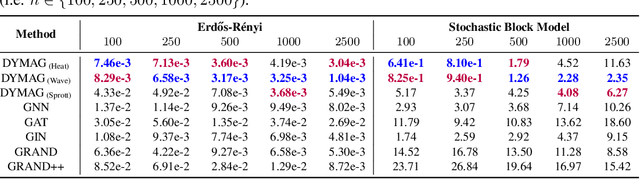
In this paper, we propose Graph Differential Equation Network (GDeNet), an approach that harnesses the expressive power of solutions to PDEs on a graph to obtain continuous node- and graph-level representations for various downstream tasks. We derive theoretical results connecting the dynamics of heat and wave equations to the spectral properties of the graph and to the behavior of continuous-time random walks on graphs. We demonstrate experimentally that these dynamics are able to capture salient aspects of graph geometry and topology by recovering generating parameters of random graphs, Ricci curvature, and persistent homology. Furthermore, we demonstrate the superior performance of GDeNet on real-world datasets including citation graphs, drug-like molecules, and proteins.