 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Real-Time Execution of Action Chunking Flow Policies
Jun 09, 2025Modern AI systems, especially those interacting with the physical world, increasingly require real-time performance. However, the high latency of state-of-the-art generalist models, including recent vision-language action models (VLAs), poses a significant challenge. While action chunking has enabled temporal consistency in high-frequency control tasks, it does not fully address the latency problem, leading to pauses or out-of-distribution jerky movements at chunk boundaries. This paper presents a novel inference-time algorithm that enables smooth asynchronous execution of action chunking policies. Our method, real-time chunking (RTC), is applicable to any diffusion- or flow-based VLA out of the box with no re-training. It generates the next action chunk while executing the current one, "freezing" actions guaranteed to execute and "inpainting" the rest. To test RTC, we introduce a new benchmark of 12 highly dynamic tasks in the Kinetix simulator, as well as evaluate 6 challenging real-world bimanual manipulation tasks. Results demonstrate that RTC is fast, performant, and uniquely robust to inference delay, significantly improving task throughput and enabling high success rates in precise tasks $\unicode{x2013}$ such as lighting a match $\unicode{x2013}$ even in the presence of significant latency. See https://pi.website/research/real_time_chunking for videos.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
$π_0$: A Vision-Language-Action Flow Model for General Robot Control
Oct 31, 2024
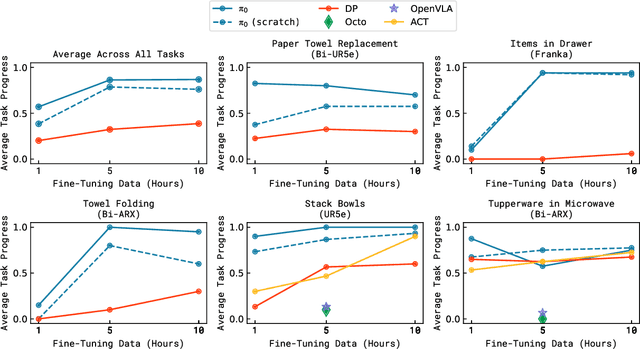

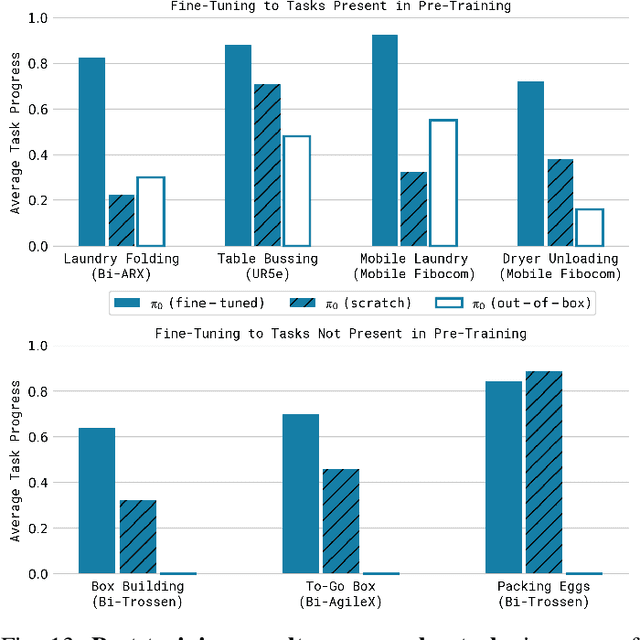
Robot learning holds tremendous promise to unlock the full potential of flexible, general, and dexterous robot systems, as well as to address some of the deepest questions in artificial intelligence. However, bringing robot learning to the level of generality required for effective real-world systems faces major obstacles in terms of data, generalization, and robustness. In this paper, we discuss how generalist robot policies (i.e., robot foundation models) can address these challenges, and how we can design effective generalist robot policies for complex and highly dexterous tasks. We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge. We then discuss how this model can be trained on a large and diverse dataset from multiple dexterous robot platforms, including single-arm robots, dual-arm robots, and mobile manipulators. We evaluate our model in terms of its ability to perform tasks in zero shot after pre-training, follow language instructions from people and from a high-level VLM policy, and its ability to acquire new skills via fine-tuning. Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes.
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
Learning Action-based Representations Using Invariance
Mar 25, 2024Robust reinforcement learning agents using high-dimensional observations must be able to identify relevant state features amidst many exogeneous distractors. A representation that captures controllability identifies these state elements by determining what affects agent control. While methods such as inverse dynamics and mutual information capture controllability for a limited number of timesteps, capturing long-horizon elements remains a challenging problem. Myopic controllability can capture the moment right before an agent crashes into a wall, but not the control-relevance of the wall while the agent is still some distance away. To address this we introduce action-bisimulation encoding, a method inspired by the bisimulation invariance pseudometric, that extends single-step controllability with a recursive invariance constraint. By doing this, action-bisimulation learns a multi-step controllability metric that smoothly discounts distant state features that are relevant for control. We demonstrate that action-bisimulation pretraining on reward-free, uniformly random data improves sample efficiency in several environments, including a photorealistic 3D simulation domain, Habitat. Additionally, we provide theoretical analysis and qualitative results demonstrating the information captured by action-bisimulation.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Fine-Tuning of Continuous-Time Diffusion Models as Entropy-Regularized Control
Feb 28, 2024



Diffusion models excel at capturing complex data distributions, such as those of natural images and proteins. While diffusion models are trained to represent the distribution in the training dataset, we often are more concerned with other properties, such as the aesthetic quality of the generated images or the functional properties of generated proteins. Diffusion models can be finetuned in a goal-directed way by maximizing the value of some reward function (e.g., the aesthetic quality of an image). However, these approaches may lead to reduced sample diversity, significant deviations from the training data distribution, and even poor sample quality due to the exploitation of an imperfect reward function. The last issue often occurs when the reward function is a learned model meant to approximate a ground-truth "genuine" reward, as is the case in many practical applications. These challenges, collectively termed "reward collapse," pose a substantial obstacle. To address this reward collapse, we frame the finetuning problem as entropy-regularized control against the pretrained diffusion model, i.e., directly optimizing entropy-enhanced rewards with neural SDEs. We present theoretical and empirical evidence that demonstrates our framework is capable of efficiently generating diverse samples with high genuine rewards, mitigating the overoptimization of imperfect reward models.
Feedback Efficient Online Fine-Tuning of Diffusion Models
Feb 27, 2024



Diffusion models excel at modeling complex data distributions, including those of images, proteins, and small molecules. However, in many cases, our goal is to model parts of the distribution that maximize certain properties: for example, we may want to generate images with high aesthetic quality, or molecules with high bioactivity. It is natural to frame this as a reinforcement learning (RL) problem, in which the objective is to fine-tune a diffusion model to maximize a reward function that corresponds to some property. Even with access to online queries of the ground-truth reward function, efficiently discovering high-reward samples can be challenging: they might have a low probability in the initial distribution, and there might be many infeasible samples that do not even have a well-defined reward (e.g., unnatural images or physically impossible molecules). In this work, we propose a novel reinforcement learning procedure that efficiently explores on the manifold of feasible samples. We present a theoretical analysis providing a regret guarantee, as well as empirical validation across three domains: images, biological sequences, and molecules.
Zero-Shot Robotic Manipulation with Pretrained Image-Editing Diffusion Models
Oct 16, 2023If generalist robots are to operate in truly unstructured environments, they need to be able to recognize and reason about novel objects and scenarios. Such objects and scenarios might not be present in the robot's own training data. We propose SuSIE, a method that leverages an image-editing diffusion model to act as a high-level planner by proposing intermediate subgoals that a low-level controller can accomplish. Specifically, we finetune InstructPix2Pix on video data, consisting of both human videos and robot rollouts, such that it outputs hypothetical future "subgoal" observations given the robot's current observation and a language command. We also use the robot data to train a low-level goal-conditioned policy to act as the aforementioned low-level controller. We find that the high-level subgoal predictions can utilize Internet-scale pretraining and visual understanding to guide the low-level goal-conditioned policy, achieving significantly better generalization and precision than conventional language-conditioned policies. We achieve state-of-the-art results on the CALVIN benchmark, and also demonstrate robust generalization on real-world manipulation tasks, beating strong baselines that have access to privileged information or that utilize orders of magnitude more compute and training data. The project website can be found at http://rail-berkeley.github.io/susie .