 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Jan 22, 2026Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025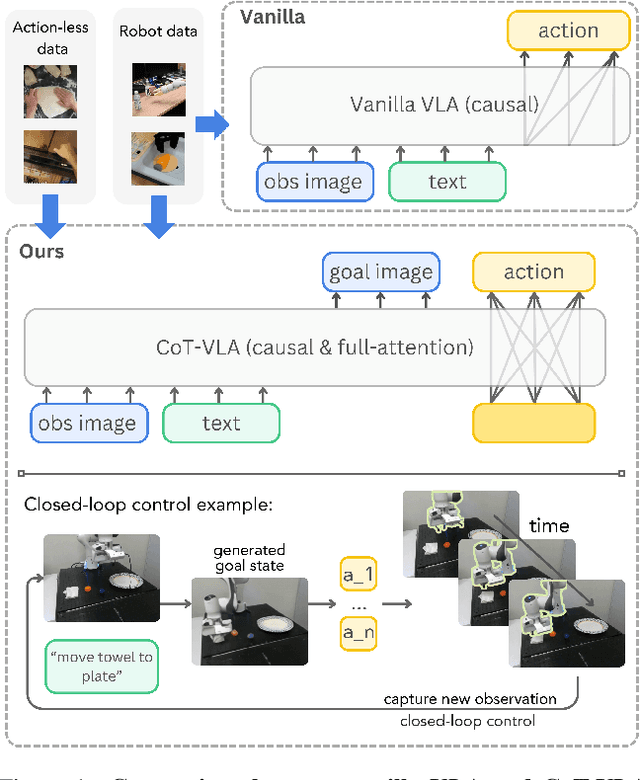

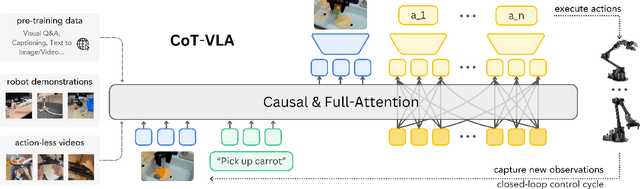
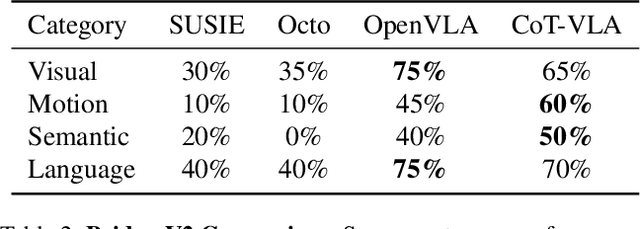
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Feb 27, 2025Recent vision-language-action models (VLAs) build upon pretrained vision-language models and leverage diverse robot datasets to demonstrate strong task execution, language following ability, and semantic generalization. Despite these successes, VLAs struggle with novel robot setups and require fine-tuning to achieve good performance, yet how to most effectively fine-tune them is unclear given many possible strategies. In this work, we study key VLA adaptation design choices such as different action decoding schemes, action representations, and learning objectives for fine-tuning, using OpenVLA as our representative base model. Our empirical analysis informs an Optimized Fine-Tuning (OFT) recipe that integrates parallel decoding, action chunking, a continuous action representation, and a simple L1 regression-based learning objective to altogether improve inference efficiency, policy performance, and flexibility in the model's input-output specifications. We propose OpenVLA-OFT, an instantiation of this recipe, which sets a new state of the art on the LIBERO simulation benchmark, significantly boosting OpenVLA's average success rate across four task suites from 76.5% to 97.1% while increasing action generation throughput by 26$\times$. In real-world evaluations, our fine-tuning recipe enables OpenVLA to successfully execute dexterous, high-frequency control tasks on a bimanual ALOHA robot and outperform other VLAs ($\pi_0$ and RDT-1B) fine-tuned using their default recipes, as well as strong imitation learning policies trained from scratch (Diffusion Policy and ACT) by up to 15% (absolute) in average success rate. We release code for OFT and pretrained model checkpoints at https://openvla-oft.github.io/.
OpenVLA: An Open-Source Vision-Language-Action Model
Jun 13, 2024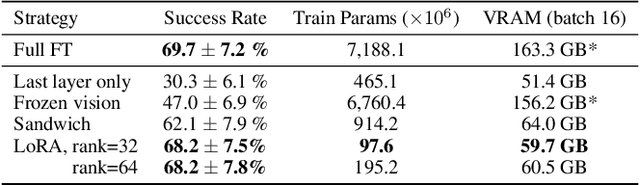
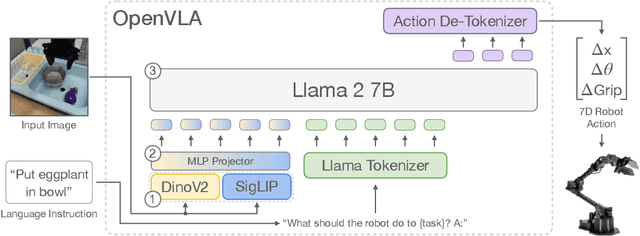
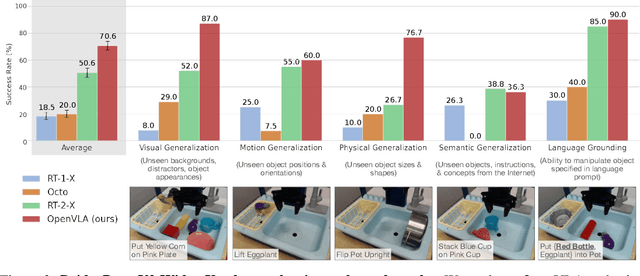
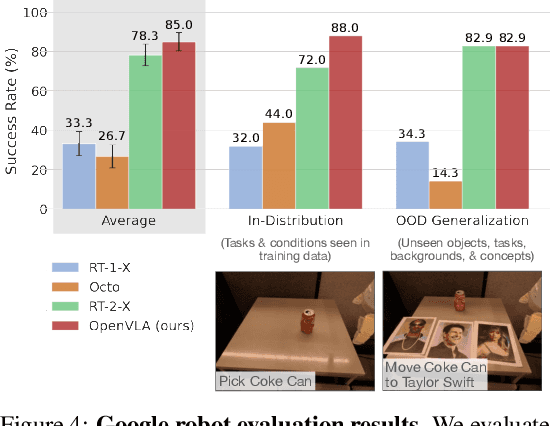
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
BridgeData V2: A Dataset for Robot Learning at Scale
Aug 24, 2023We introduce BridgeData V2, a large and diverse dataset of robotic manipulation behaviors designed to facilitate research on scalable robot learning. BridgeData V2 contains 60,096 trajectories collected across 24 environments on a publicly available low-cost robot. BridgeData V2 provides extensive task and environment variability, leading to skills that can generalize across environments, domains, and institutions, making the dataset a useful resource for a broad range of researchers. Additionally, the dataset is compatible with a wide variety of open-vocabulary, multi-task learning methods conditioned on goal images or natural language instructions. In our experiments, we train 6 state-of-the-art imitation learning and offline reinforcement learning methods on our dataset, and find that they succeed on a suite of tasks requiring varying amounts of generalization. We also demonstrate that the performance of these methods improves with more data and higher capacity models, and that training on a greater variety of skills leads to improved generalization. By publicly sharing BridgeData V2 and our pre-trained models, we aim to accelerate research in scalable robot learning methods. Project page at https://rail-berkeley.github.io/bridgedata
Giving Robots a Hand: Learning Generalizable Manipulation with Eye-in-Hand Human Video Demonstrations
Jul 12, 2023



Eye-in-hand cameras have shown promise in enabling greater sample efficiency and generalization in vision-based robotic manipulation. However, for robotic imitation, it is still expensive to have a human teleoperator collect large amounts of expert demonstrations with a real robot. Videos of humans performing tasks, on the other hand, are much cheaper to collect since they eliminate the need for expertise in robotic teleoperation and can be quickly captured in a wide range of scenarios. Therefore, human video demonstrations are a promising data source for learning generalizable robotic manipulation policies at scale. In this work, we augment narrow robotic imitation datasets with broad unlabeled human video demonstrations to greatly enhance the generalization of eye-in-hand visuomotor policies. Although a clear visual domain gap exists between human and robot data, our framework does not need to employ any explicit domain adaptation method, as we leverage the partial observability of eye-in-hand cameras as well as a simple fixed image masking scheme. On a suite of eight real-world tasks involving both 3-DoF and 6-DoF robot arm control, our method improves the success rates of eye-in-hand manipulation policies by 58% (absolute) on average, enabling robots to generalize to both new environment configurations and new tasks that are unseen in the robot demonstration data. See video results at https://giving-robots-a-hand.github.io/ .
NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis
Jan 18, 2023Expert demonstrations are a rich source of supervision for training visual robotic manipulation policies, but imitation learning methods often require either a large number of demonstrations or expensive online expert supervision to learn reactive closed-loop behaviors. In this work, we introduce SPARTN (Synthetic Perturbations for Augmenting Robot Trajectories via NeRF): a fully-offline data augmentation scheme for improving robot policies that use eye-in-hand cameras. Our approach leverages neural radiance fields (NeRFs) to synthetically inject corrective noise into visual demonstrations, using NeRFs to generate perturbed viewpoints while simultaneously calculating the corrective actions. This requires no additional expert supervision or environment interaction, and distills the geometric information in NeRFs into a real-time reactive RGB-only policy. In a simulated 6-DoF visual grasping benchmark, SPARTN improves success rates by 2.8$\times$ over imitation learning without the corrective augmentations and even outperforms some methods that use online supervision. It additionally closes the gap between RGB-only and RGB-D success rates, eliminating the previous need for depth sensors. In real-world 6-DoF robotic grasping experiments from limited human demonstrations, our method improves absolute success rates by $22.5\%$ on average, including objects that are traditionally challenging for depth-based methods. See video results at \url{https://bland.website/spartn}.
Vision-Based Manipulators Need to Also See from Their Hands
Mar 15, 2022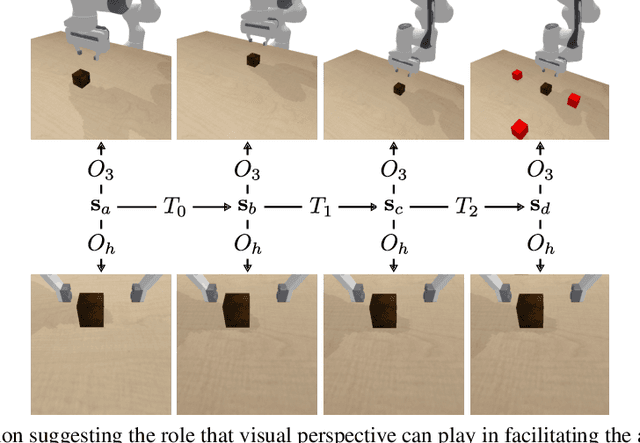


We study how the choice of visual perspective affects learning and generalization in the context of physical manipulation from raw sensor observations. Compared with the more commonly used global third-person perspective, a hand-centric (eye-in-hand) perspective affords reduced observability, but we find that it consistently improves training efficiency and out-of-distribution generalization. These benefits hold across a variety of learning algorithms, experimental settings, and distribution shifts, and for both simulated and real robot apparatuses. However, this is only the case when hand-centric observability is sufficient; otherwise, including a third-person perspective is necessary for learning, but also harms out-of-distribution generalization. To mitigate this, we propose to regularize the third-person information stream via a variational information bottleneck. On six representative manipulation tasks with varying hand-centric observability adapted from the Meta-World benchmark, this results in a state-of-the-art reinforcement learning agent operating from both perspectives improving its out-of-distribution generalization on every task. While some practitioners have long put cameras in the hands of robots, our work systematically analyzes the benefits of doing so and provides simple and broadly applicable insights for improving end-to-end learned vision-based robotic manipulation.