 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Feb 03, 2026Despite rapid progress in autoregressive video diffusion, an emerging system algorithm bottleneck limits both deployability and generation capability: KV cache memory. In autoregressive video generation models, the KV cache grows with generation history and quickly dominates GPU memory, often exceeding 30 GB, preventing deployment on widely available hardware. More critically, constrained KV cache budgets restrict the effective working memory, directly degrading long horizon consistency in identity, layout, and motion. To address this challenge, we present Quant VideoGen (QVG), a training free KV cache quantization framework for autoregressive video diffusion models. QVG leverages video spatiotemporal redundancy through Semantic Aware Smoothing, producing low magnitude, quantization friendly residuals. It further introduces Progressive Residual Quantization, a coarse to fine multi stage scheme that reduces quantization error while enabling a smooth quality memory trade off. Across LongCat Video, HY WorldPlay, and Self Forcing benchmarks, QVG establishes a new Pareto frontier between quality and memory efficiency, reducing KV cache memory by up to 7.0 times with less than 4% end to end latency overhead while consistently outperforming existing baselines in generation quality.
Locality-aware Parallel Decoding for Efficient Autoregressive Image Generation
Jul 02, 2025We present Locality-aware Parallel Decoding (LPD) to accelerate autoregressive image generation. Traditional autoregressive image generation relies on next-patch prediction, a memory-bound process that leads to high latency. Existing works have tried to parallelize next-patch prediction by shifting to multi-patch prediction to accelerate the process, but only achieved limited parallelization. To achieve high parallelization while maintaining generation quality, we introduce two key techniques: (1) Flexible Parallelized Autoregressive Modeling, a novel architecture that enables arbitrary generation ordering and degrees of parallelization. It uses learnable position query tokens to guide generation at target positions while ensuring mutual visibility among concurrently generated tokens for consistent parallel decoding. (2) Locality-aware Generation Ordering, a novel schedule that forms groups to minimize intra-group dependencies and maximize contextual support, enhancing generation quality. With these designs, we reduce the generation steps from 256 to 20 (256$\times$256 res.) and 1024 to 48 (512$\times$512 res.) without compromising quality on the ImageNet class-conditional generation, and achieving at least 3.4$\times$ lower latency than previous parallelized autoregressive models.
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025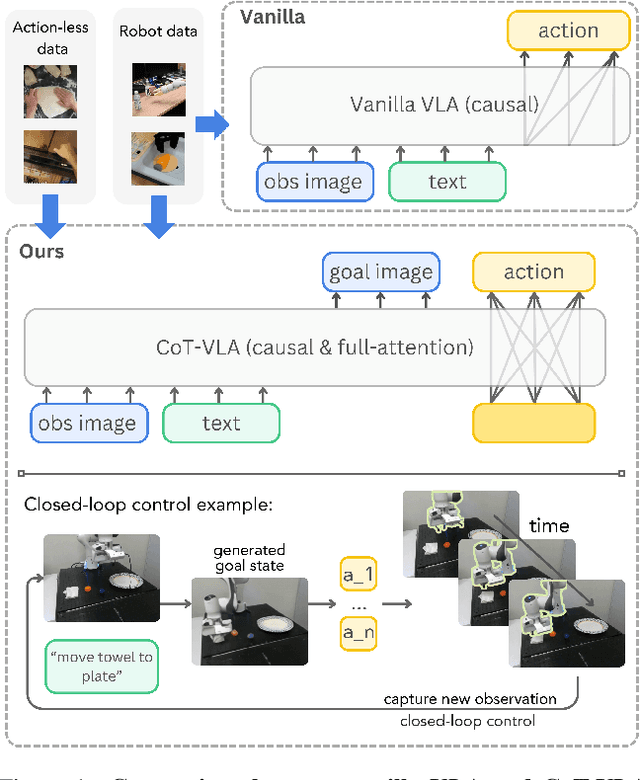

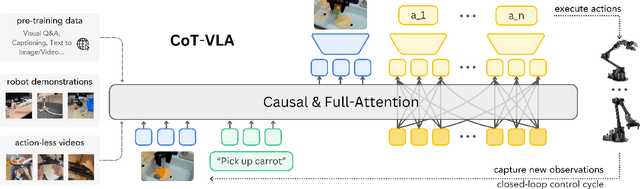
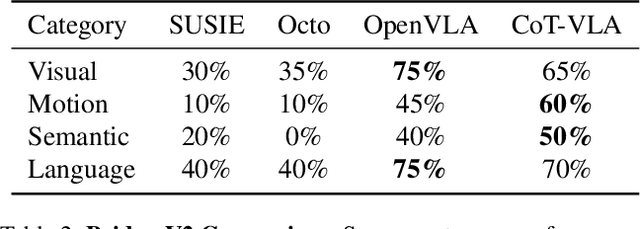
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
NVILA: Efficient Frontier Visual Language Models
Dec 05, 2024
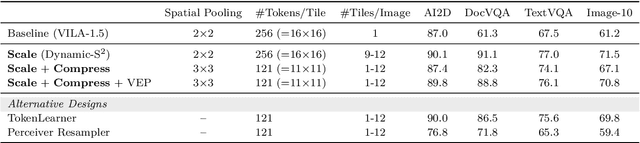

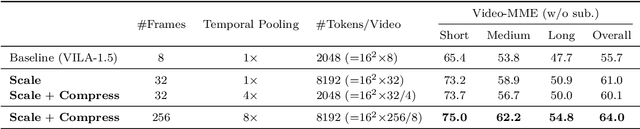
Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention. This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X. We will soon make our code and models available to facilitate reproducibility.
HART: Efficient Visual Generation with Hybrid Autoregressive Transformer
Oct 14, 2024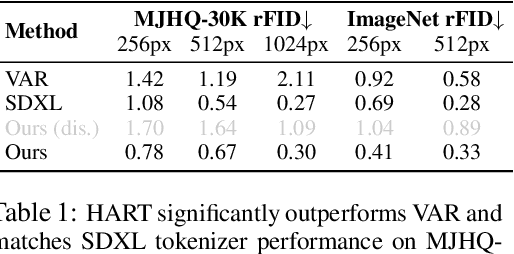

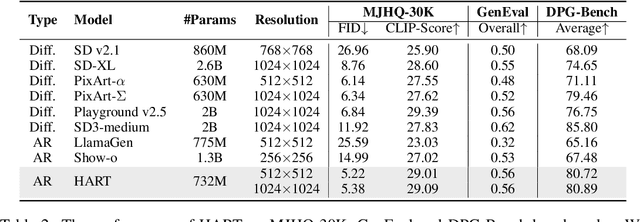

We introduce Hybrid Autoregressive Transformer (HART), an autoregressive (AR) visual generation model capable of directly generating 1024x1024 images, rivaling diffusion models in image generation quality. Existing AR models face limitations due to the poor image reconstruction quality of their discrete tokenizers and the prohibitive training costs associated with generating 1024px images. To address these challenges, we present the hybrid tokenizer, which decomposes the continuous latents from the autoencoder into two components: discrete tokens representing the big picture and continuous tokens representing the residual components that cannot be represented by the discrete tokens. The discrete component is modeled by a scalable-resolution discrete AR model, while the continuous component is learned with a lightweight residual diffusion module with only 37M parameters. Compared with the discrete-only VAR tokenizer, our hybrid approach improves reconstruction FID from 2.11 to 0.30 on MJHQ-30K, leading to a 31% generation FID improvement from 7.85 to 5.38. HART also outperforms state-of-the-art diffusion models in both FID and CLIP score, with 4.5-7.7x higher throughput and 6.9-13.4x lower MACs. Our code is open sourced at https://github.com/mit-han-lab/hart.
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Sep 06, 2024


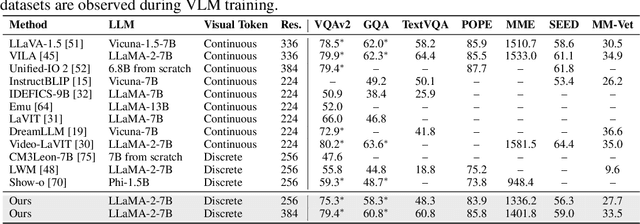
VILA-U is a Unified foundation model that integrates Video, Image, Language understanding and generation. Traditional visual language models (VLMs) use separate modules for understanding and generating visual content, which can lead to misalignment and increased complexity. In contrast, VILA-U employs a single autoregressive next-token prediction framework for both tasks, eliminating the need for additional components like diffusion models. This approach not only simplifies the model but also achieves near state-of-the-art performance in visual language understanding and generation. The success of VILA-U is attributed to two main factors: the unified vision tower that aligns discrete visual tokens with textual inputs during pretraining, which enhances visual perception, and autoregressive image generation can achieve similar quality as diffusion models with high-quality dataset. This allows VILA-U to perform comparably to more complex models using a fully token-based autoregressive framework.
Sparse Refinement for Efficient High-Resolution Semantic Segmentation
Jul 26, 2024Semantic segmentation empowers numerous real-world applications, such as autonomous driving and augmented/mixed reality. These applications often operate on high-resolution images (e.g., 8 megapixels) to capture the fine details. However, this comes at the cost of considerable computational complexity, hindering the deployment in latency-sensitive scenarios. In this paper, we introduce SparseRefine, a novel approach that enhances dense low-resolution predictions with sparse high-resolution refinements. Based on coarse low-resolution outputs, SparseRefine first uses an entropy selector to identify a sparse set of pixels with high entropy. It then employs a sparse feature extractor to efficiently generate the refinements for those pixels of interest. Finally, it leverages a gated ensembler to apply these sparse refinements to the initial coarse predictions. SparseRefine can be seamlessly integrated into any existing semantic segmentation model, regardless of CNN- or ViT-based. SparseRefine achieves significant speedup: 1.5 to 3.7 times when applied to HRNet-W48, SegFormer-B5, Mask2Former-T/L and SegNeXt-L on Cityscapes, with negligible to no loss of accuracy. Our "dense+sparse" paradigm paves the way for efficient high-resolution visual computing.
Condition-Aware Neural Network for Controlled Image Generation
Apr 01, 2024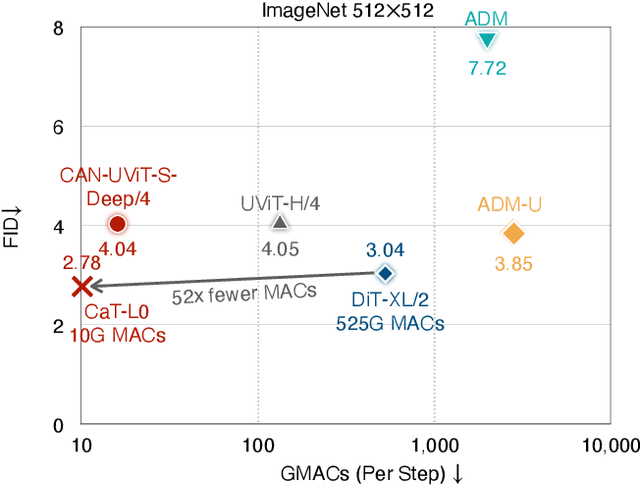



We present Condition-Aware Neural Network (CAN), a new method for adding control to image generative models. In parallel to prior conditional control methods, CAN controls the image generation process by dynamically manipulating the weight of the neural network. This is achieved by introducing a condition-aware weight generation module that generates conditional weight for convolution/linear layers based on the input condition. We test CAN on class-conditional image generation on ImageNet and text-to-image generation on COCO. CAN consistently delivers significant improvements for diffusion transformer models, including DiT and UViT. In particular, CAN combined with EfficientViT (CaT) achieves 2.78 FID on ImageNet 512x512, surpassing DiT-XL/2 while requiring 52x fewer MACs per sampling step.
EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss
Feb 07, 2024We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT's efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance. Our code and pre-trained models are released at https://github.com/mit-han-lab/efficientvit.
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023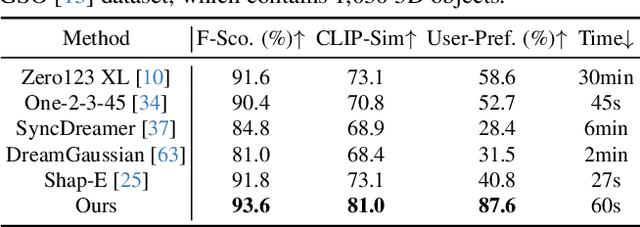
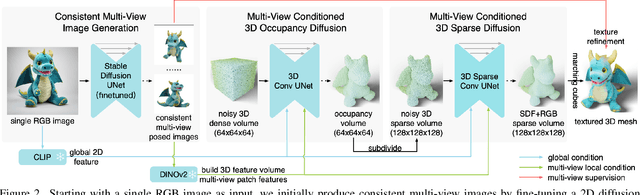
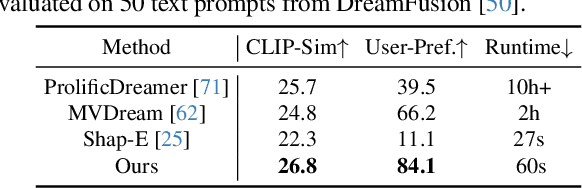
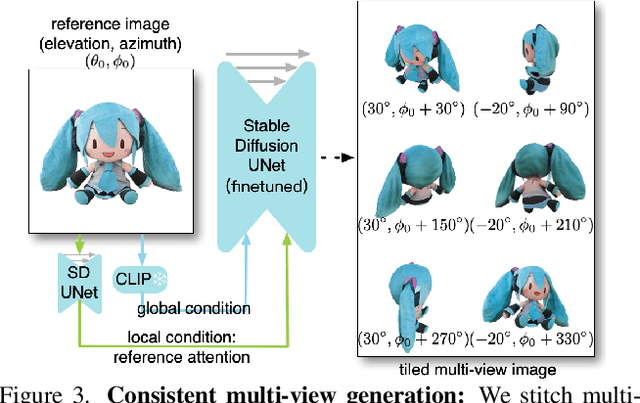
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.