 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceive, Interact, Reason: Building Tool-Augmented Visual Agents for Spatial Reasoning
Jun 11, 2026While recent vision-language models (VLMs) demonstrate strong multimodal understanding, they remain limited in spatial reasoning tasks that require active evidence acquisition and multi-step visual interaction. This limitation suggests that relying solely on implicit visual representations from vision encoders is insufficient for recovering fine-grained spatial evidence. We introduce PERception-Interaction-reason Agent (PERIA), a tool-augmented visual agent for spatial reasoning tasks across map reasoning, visual probing, and vision reconstruction. PERIA uses two lightweight tool families: vision perception tools for exposing textual, symbolic, and spatial evidence, and vision interaction tools for manipulating visual context, tracing paths, and verifying spatial relations. To train PERIA, we develop a unified recipe that combines supervised tool-use trajectory synthesis, composite rewards, and Observation-Relaxed Group-in-Group Policy Optimization (OR-GIGPO) for effective multi-tool behavior. Experiments on 13 benchmarks from 8 datasets show that PERIA-8B improves over the Qwen3-8B backbone by 10.0% on in-distribution benchmarks and 4.4% on out-of-distribution benchmarks, while outperforming previous state-of-the-art baselines of similar size by 7.0%-14.8%. It also achieves performance comparable to much larger models such as Qwen3-VL-235B-A22B-Thinking and GPT-5, demonstrating the effectiveness of PERIA in enhancing spatial reasoning capabilities.
Grounded 3D-Aware Spatial Vision-Language Modeling
May 28, 2026We present GR3D, a spatial vision language model equipped with three complementary grounding capabilities--explicit 2D grounding, implicit 2D grounding, and monocular 3D grounding--within a single framework. GR3D introduces an implicit grounding mechanism that identifies entity mentions during generation and inserts the corresponding region tokens into the text stream, allowing the model to reference visual evidence on the fly when producing spatial chain-of-thought responses. In parallel, a region-prompted monocular 3D grounding design predicts 3D bounding boxes in the camera view from grounded region queries, supported by intrinsic-aware normalization and dense geometric supervision. Together, these grounding capabilities enable GR3D to decompose complex spatial understanding problems into grounded 2D perception followed by 3D inference. GR3D achieves consistent improvements across grounded and non-grounded spatial benchmarks, demonstrating grounding as an effective inductive bias for strengthening spatial understanding in VLMs. These grounding capabilities collectively enhance general spatial understanding beyond the grounding task itself.
QCalEval: Benchmarking Vision-Language Models for Quantum Calibration Plot Understanding
Apr 28, 2026Quantum computing calibration depends on interpreting experimental data, and calibration plots provide the most universal human-readable representation for this task, yet no systematic evaluation exists of how well vision-language models (VLMs) interpret them. We introduce QCalEval, the first VLM benchmark for quantum calibration plots: 243 samples across 87 scenario types from 22 experiment families, spanning superconducting qubits and neutral atoms, evaluated on six question types in both zero-shot and in-context learning settings. The best general-purpose zero-shot model reaches a mean score of 72.3, and many open-weight models degrade under multi-image in-context learning, whereas frontier closed models improve substantially. A supervised fine-tuning ablation at the 9-billion-parameter scale shows that SFT improves zero-shot performance but cannot close the multimodal in-context learning gap. As a reference case study, we release NVIDIA Ising Calibration 1, an open-weight model based on Qwen3.5-35B-A3B that reaches 74.7 zero-shot average score.
Fast-dVLM: Efficient Block-Diffusion VLM via Direct Conversion from Autoregressive VLM
Apr 08, 2026Vision-language models (VLMs) predominantly rely on autoregressive decoding, which generates tokens one at a time and fundamentally limits inference throughput. This limitation is especially acute in physical AI scenarios such as robotics and autonomous driving, where VLMs are deployed on edge devices at batch size one, making AR decoding memory-bandwidth-bound and leaving hardware parallelism underutilized. While block-wise discrete diffusion has shown promise for parallel text generation, extending it to VLMs remains challenging due to the need to jointly handle continuous visual representations and discrete text tokens while preserving pretrained multimodal capabilities. We present Fast-dVLM, a block-diffusion-based VLM that enables KV-cache-compatible parallel decoding and speculative block decoding for inference acceleration. We systematically compare two AR-to-diffusion conversion strategies: a two-stage approach that first adapts the LLM backbone with text-only diffusion fine-tuning before multimodal training, and a direct approach that converts the full AR VLM in one stage. Under comparable training budgets, direct conversion proves substantially more efficient by leveraging the already multimodally aligned VLM; we therefore adopt it as our recommended recipe. We introduce a suite of multimodal diffusion adaptations, block size annealing, causal context attention, auto-truncation masking, and vision efficient concatenation, that collectively enable effective block diffusion in the VLM setting. Extensive experiments across 11 multimodal benchmarks show Fast-dVLM matches its autoregressive counterpart in generation quality. With SGLang integration and FP8 quantization, Fast-dVLM achieves over 6x end-to-end inference speedup over the AR baseline.
Jet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow
Jan 20, 2026Reinforcement learning (RL) is essential for enhancing the complex reasoning capabilities of large language models (LLMs). However, existing RL training pipelines are computationally inefficient and resource-intensive, with the rollout phase accounting for over 70% of total training time. Quantized RL training, particularly using FP8 precision, offers a promising approach to mitigating this bottleneck. A commonly adopted strategy applies FP8 precision during rollout while retaining BF16 precision for training. In this work, we present the first comprehensive study of FP8 RL training and demonstrate that the widely used BF16-training + FP8-rollout strategy suffers from severe training instability and catastrophic accuracy collapse under long-horizon rollouts and challenging tasks. Our analysis shows that these failures stem from the off-policy nature of the approach, which introduces substantial numerical mismatch between training and inference. Motivated by these observations, we propose Jet-RL, an FP8 RL training framework that enables robust and stable RL optimization. The key idea is to adopt a unified FP8 precision flow for both training and rollout, thereby minimizing numerical discrepancies and eliminating the need for inefficient inter-step calibration. Extensive experiments validate the effectiveness of Jet-RL: our method achieves up to 33% speedup in the rollout phase, up to 41% speedup in the training phase, and a 16% end-to-end speedup over BF16 training, while maintaining stable convergence across all settings and incurring negligible accuracy degradation.
Scaling Test-time Inference for Visual Grounding
Jan 20, 2026Visual grounding is an essential capability of Visual Language Models (VLMs) to understand the real physical world. Previous state-of-the-art grounding visual language models usually have large model sizes, making them heavy for deployment and slow for inference. However, we notice that the sizes of visual encoders are nearly the same for small and large VLMs and the major difference is the sizes of the language models. Small VLMs fall behind larger VLMs in grounding because of the difference in language understanding capability rather than visual information handling. To mitigate the gap, we introduce 'Efficient visual Grounding language Models' (EGM): a method to scale the test-time computation (#generated tokens). Scaling the test-time computation of a small model is deployment-friendly, and yields better end-to-end latency as the cost of each token is much cheaper compared to directly running a large model. On the RefCOCO benchmark, our EGM-Qwen3-VL-8B demonstrates 91.4 IoU with an average of 737ms (5.9x faster) latency while Qwen3-VL-235B demands 4,320ms to achieve 90.5 IoU. To validate our approach's generality, we further set up a new amodal grounding setting that requires the model to predict both the visible and occluded parts of the objects. Experiments show our method can consistently and significantly improve the vanilla grounding and amodal grounding capabilities of small models to be on par with or outperform the larger models, thereby improving the efficiency for visual grounding.
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025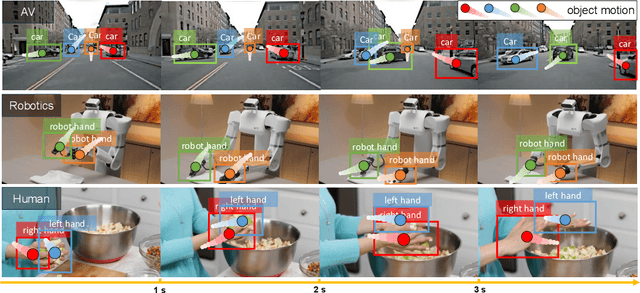
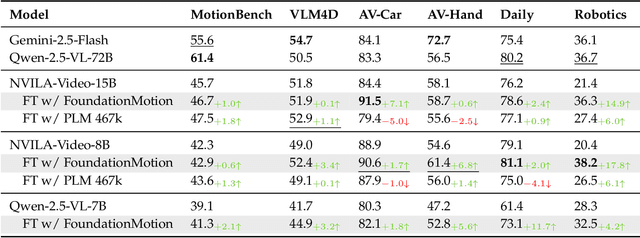
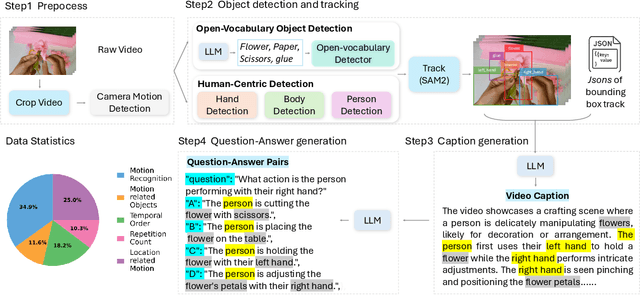

Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.
OckBench: Measuring the Efficiency of LLM Reasoning
Nov 07, 2025Large language models such as GPT-4, Claude 3, and the Gemini series have improved automated reasoning and code generation. However, existing benchmarks mainly focus on accuracy and output quality, and they ignore an important factor: decoding token efficiency. In real systems, generating 10,000 tokens versus 100,000 tokens leads to large differences in latency, cost, and energy. In this work, we introduce OckBench, a model-agnostic and hardware-agnostic benchmark that evaluates both accuracy and token count for reasoning and coding tasks. Through experiments comparing multiple open- and closed-source models, we uncover that many models with comparable accuracy differ wildly in token consumption, revealing that efficiency variance is a neglected but significant axis of differentiation. We further demonstrate Pareto frontiers over the accuracy-efficiency plane and argue for an evaluation paradigm shift: we should no longer treat tokens as "free" to multiply. OckBench provides a unified platform for measuring, comparing, and guiding research in token-efficient reasoning. Our benchmarks are available at https://ockbench.github.io/ .
Scaling RL to Long Videos
Jul 10, 2025We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 52K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In experiments, LongVILA-R1-7B achieves strong performance on long video QA benchmarks such as VideoMME. It also outperforms Video-R1-7B and even matches Gemini-1.5-Pro across temporal reasoning, goal and purpose reasoning, spatial reasoning, and plot reasoning on our LongVideo-Reason-eval benchmark. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. LongVILA-R1 demonstrates consistent performance gains as the number of input video frames scales. LongVILA-R1 marks a firm step towards long video reasoning in VLMs. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames / around 256k tokens).
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
May 28, 2025Diffusion-based large language models (Diffusion LLMs) have shown promise for non-autoregressive text generation with parallel decoding capabilities. However, the practical inference speed of open-sourced Diffusion LLMs often lags behind autoregressive models due to the lack of Key-Value (KV) Cache and quality degradation when decoding multiple tokens simultaneously. To bridge this gap, we introduce a novel block-wise approximate KV Cache mechanism tailored for bidirectional diffusion models, enabling cache reuse with negligible performance drop. Additionally, we identify the root cause of generation quality degradation in parallel decoding as the disruption of token dependencies under the conditional independence assumption. To address this, we propose a confidence-aware parallel decoding strategy that selectively decodes tokens exceeding a confidence threshold, mitigating dependency violations and maintaining generation quality. Experimental results on LLaDA and Dream models across multiple LLM benchmarks demonstrate up to \textbf{27.6$\times$ throughput} improvement with minimal accuracy loss, closing the performance gap with autoregressive models and paving the way for practical deployment of Diffusion LLMs.