 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs complicated ethical dilemma analyzers?
May 12, 2025
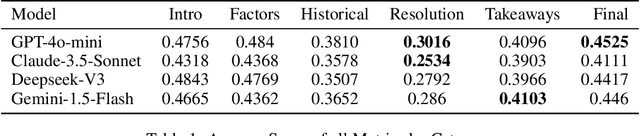
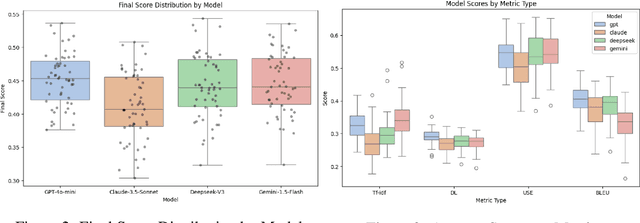
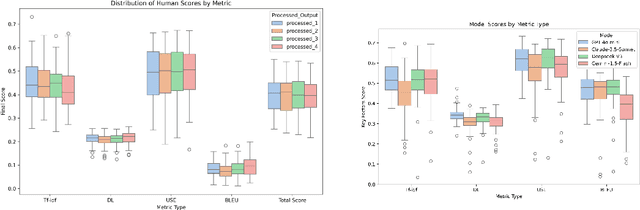
One open question in the study of Large Language Models (LLMs) is whether they can emulate human ethical reasoning and act as believable proxies for human judgment. To investigate this, we introduce a benchmark dataset comprising 196 real-world ethical dilemmas and expert opinions, each segmented into five structured components: Introduction, Key Factors, Historical Theoretical Perspectives, Resolution Strategies, and Key Takeaways. We also collect non-expert human responses for comparison, limited to the Key Factors section due to their brevity. We evaluate multiple frontier LLMs (GPT-4o-mini, Claude-3.5-Sonnet, Deepseek-V3, Gemini-1.5-Flash) using a composite metric framework based on BLEU, Damerau-Levenshtein distance, TF-IDF cosine similarity, and Universal Sentence Encoder similarity. Metric weights are computed through an inversion-based ranking alignment and pairwise AHP analysis, enabling fine-grained comparison of model outputs to expert responses. Our results show that LLMs generally outperform non-expert humans in lexical and structural alignment, with GPT-4o-mini performing most consistently across all sections. However, all models struggle with historical grounding and proposing nuanced resolution strategies, which require contextual abstraction. Human responses, while less structured, occasionally achieve comparable semantic similarity, suggesting intuitive moral reasoning. These findings highlight both the strengths and current limitations of LLMs in ethical decision-making.
SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
Jan 30, 2025



This paper presents SANA-1.5, a linear Diffusion Transformer for efficient scaling in text-to-image generation. Building upon SANA-1.0, we introduce three key innovations: (1) Efficient Training Scaling: A depth-growth paradigm that enables scaling from 1.6B to 4.8B parameters with significantly reduced computational resources, combined with a memory-efficient 8-bit optimizer. (2) Model Depth Pruning: A block importance analysis technique for efficient model compression to arbitrary sizes with minimal quality loss. (3) Inference-time Scaling: A repeated sampling strategy that trades computation for model capacity, enabling smaller models to match larger model quality at inference time. Through these strategies, SANA-1.5 achieves a text-image alignment score of 0.72 on GenEval, which can be further improved to 0.80 through inference scaling, establishing a new SoTA on GenEval benchmark. These innovations enable efficient model scaling across different compute budgets while maintaining high quality, making high-quality image generation more accessible.
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
Nov 07, 2024



Diffusion models have been proven highly effective at generating high-quality images. However, as these models grow larger, they require significantly more memory and suffer from higher latency, posing substantial challenges for deployment. In this work, we aim to accelerate diffusion models by quantizing their weights and activations to 4 bits. At such an aggressive level, both weights and activations are highly sensitive, where conventional post-training quantization methods for large language models like smoothing become insufficient. To overcome this limitation, we propose SVDQuant, a new 4-bit quantization paradigm. Different from smoothing which redistributes outliers between weights and activations, our approach absorbs these outliers using a low-rank branch. We first consolidate the outliers by shifting them from activations to weights, then employ a high-precision low-rank branch to take in the weight outliers with Singular Value Decomposition (SVD). This process eases the quantization on both sides. However, na\"{\i}vely running the low-rank branch independently incurs significant overhead due to extra data movement of activations, negating the quantization speedup. To address this, we co-design an inference engine Nunchaku that fuses the kernels of the low-rank branch into those of the low-bit branch to cut off redundant memory access. It can also seamlessly support off-the-shelf low-rank adapters (LoRAs) without the need for re-quantization. Extensive experiments on SDXL, PixArt-$\Sigma$, and FLUX.1 validate the effectiveness of SVDQuant in preserving image quality. We reduce the memory usage for the 12B FLUX.1 models by 3.5$\times$, achieving 3.0$\times$ speedup over the 4-bit weight-only quantized baseline on the 16GB laptop 4090 GPU, paving the way for more interactive applications on PCs. Our quantization library and inference engine are open-sourced.
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Oct 15, 2024



We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096$\times$4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8$\times$, we trained an AE that can compress images 32$\times$, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024$\times$1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
May 07, 2024
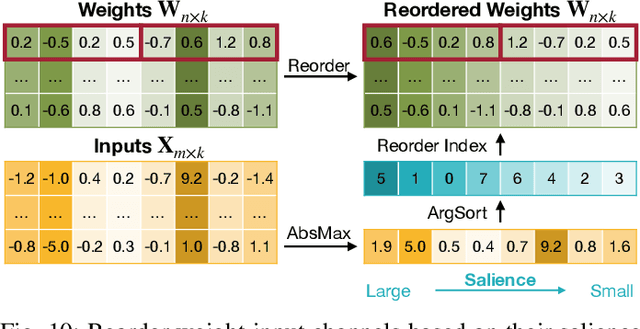
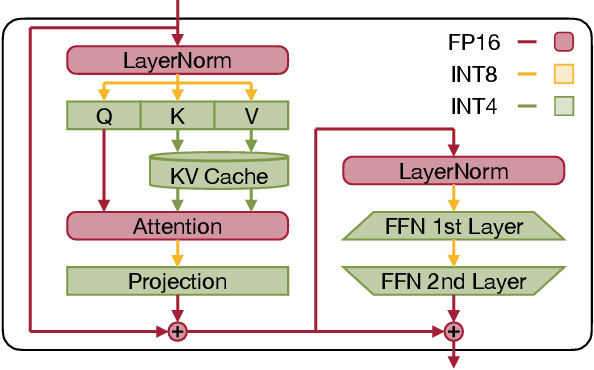
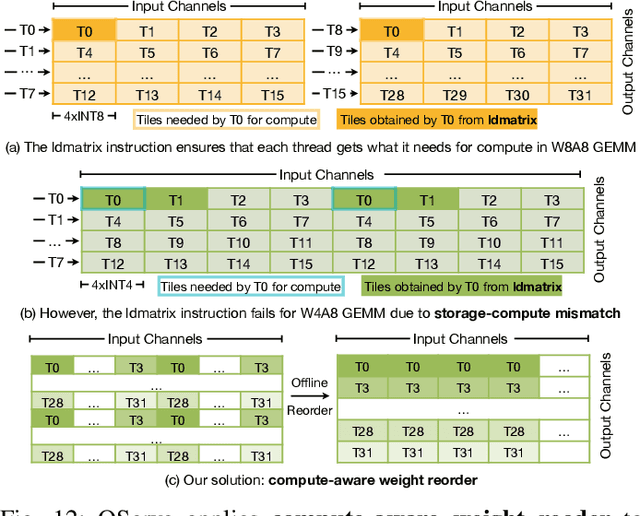
Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of-the-art INT4 quantization techniques only accelerate low-batch, edge LLM inference, failing to deliver performance gains in large-batch, cloud-based LLM serving. We uncover a critical issue: existing INT4 quantization methods suffer from significant runtime overhead (20-90%) when dequantizing either weights or partial sums on GPUs. To address this challenge, we introduce QoQ, a W4A8KV4 quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache. QoQ stands for quattuor-octo-quattuor, which represents 4-8-4 in Latin. QoQ is implemented by the QServe inference library that achieves measured speedup. The key insight driving QServe is that the efficiency of LLM serving on GPUs is critically influenced by operations on low-throughput CUDA cores. Building upon this insight, in QoQ algorithm, we introduce progressive quantization that can allow low dequantization overhead in W4A8 GEMM. Additionally, we develop SmoothAttention to effectively mitigate the accuracy degradation incurred by 4-bit KV quantization. In the QServe system, we perform compute-aware weight reordering and take advantage of register-level parallelism to reduce dequantization latency. We also make fused attention memory-bound, harnessing the performance gain brought by KV4 quantization. As a result, QServe improves the maximum achievable serving throughput of Llama-3-8B by 1.2x on A100, 1.4x on L40S; and Qwen1.5-72B by 2.4x on A100, 3.5x on L40S, compared to TensorRT-LLM. Remarkably, QServe on L40S GPU can achieve even higher throughput than TensorRT-LLM on A100. Thus, QServe effectively reduces the dollar cost of LLM serving by 3x. Code is available at https://github.com/mit-han-lab/qserve.
SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning
Jan 04, 2021

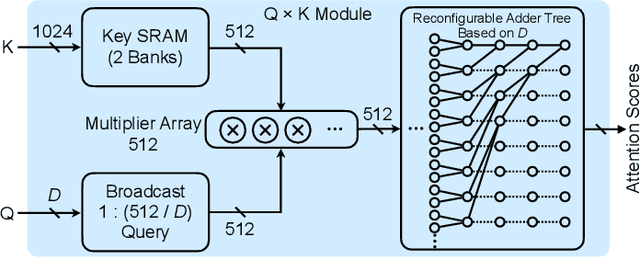
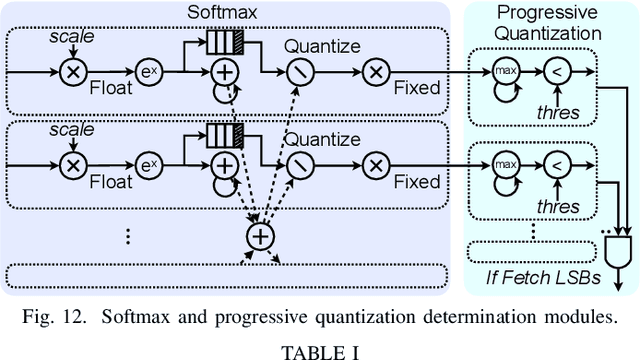
The attention mechanism is becoming increasingly popular in Natural Language Processing (NLP) applications, showing superior performance than convolutional and recurrent architectures. However, general-purpose platforms such as CPUs and GPUs are inefficient when performing attention inference due to complicated data movement and low arithmetic intensity. Moreover, existing NN accelerators mainly focus on optimizing convolutional or recurrent models, and cannot efficiently support attention. In this paper, we present SpAtten, an efficient algorithm-architecture co-design that leverages token sparsity, head sparsity, and quantization opportunities to reduce the attention computation and memory access. Inspired by the high redundancy of human languages, we propose the novel cascade token pruning to prune away unimportant tokens in the sentence. We also propose cascade head pruning to remove unessential heads. Cascade pruning is fundamentally different from weight pruning since there is no trainable weight in the attention mechanism, and the pruned tokens and heads are selected on the fly. To efficiently support them on hardware, we design a novel top-k engine to rank token and head importance scores with high throughput. Furthermore, we propose progressive quantization that first fetches MSBs only and performs the computation; if the confidence is low, it fetches LSBs and recomputes the attention outputs, trading computation for memory reduction. Extensive experiments on 30 benchmarks show that, on average, SpAtten reduces DRAM access by 10.0x with no accuracy loss, and achieves 1.6x, 3.0x, 162x, 347x speedup, and 1,4x, 3.2x, 1193x, 4059x energy savings over A3 accelerator, MNNFast accelerator, TITAN Xp GPU, Xeon CPU, respectively.
Benchmark Visual Question Answer Models by using Focus Map
Jan 13, 2018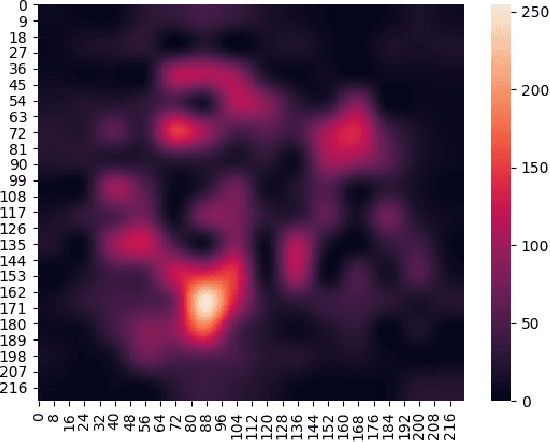

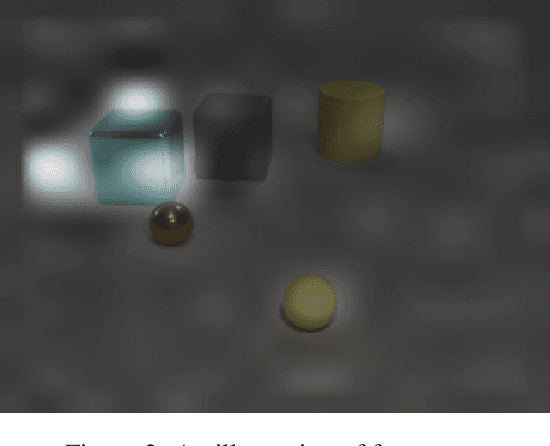
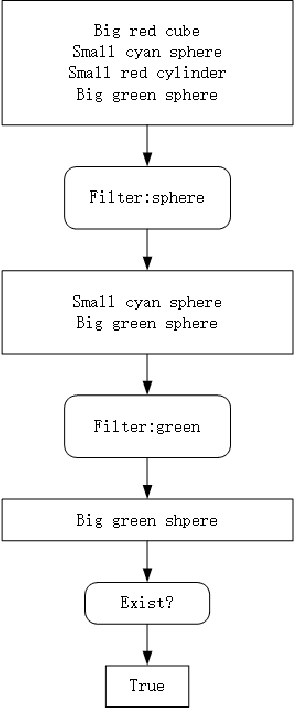
Inferring and Executing Programs for Visual Reasoning proposes a model for visual reasoning that consists of a program generator and an execution engine to avoid end-to-end models. To show that the model actually learns which objects to focus on to answer the questions, the authors give a visualization of the norm of the gradient of the sum of the predicted answer scores with respect to the final feature map. However, the authors do not evaluate the efficiency of focus map. This paper purposed a method for evaluating it. We generate several kinds of questions to test different keywords. We infer focus maps from the model by asking these questions and evaluate them by comparing with the segmentation graph. Furthermore, this method can be applied to any model if focus maps can be inferred from it. By evaluating focus map of different models on the CLEVR dataset, we will show that CLEVR-iep model has learned where to focus more than end-to-end models.