 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Feb 03, 2026Despite rapid progress in autoregressive video diffusion, an emerging system algorithm bottleneck limits both deployability and generation capability: KV cache memory. In autoregressive video generation models, the KV cache grows with generation history and quickly dominates GPU memory, often exceeding 30 GB, preventing deployment on widely available hardware. More critically, constrained KV cache budgets restrict the effective working memory, directly degrading long horizon consistency in identity, layout, and motion. To address this challenge, we present Quant VideoGen (QVG), a training free KV cache quantization framework for autoregressive video diffusion models. QVG leverages video spatiotemporal redundancy through Semantic Aware Smoothing, producing low magnitude, quantization friendly residuals. It further introduces Progressive Residual Quantization, a coarse to fine multi stage scheme that reduces quantization error while enabling a smooth quality memory trade off. Across LongCat Video, HY WorldPlay, and Self Forcing benchmarks, QVG establishes a new Pareto frontier between quality and memory efficiency, reducing KV cache memory by up to 7.0 times with less than 4% end to end latency overhead while consistently outperforming existing baselines in generation quality.
Jet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow
Jan 20, 2026Reinforcement learning (RL) is essential for enhancing the complex reasoning capabilities of large language models (LLMs). However, existing RL training pipelines are computationally inefficient and resource-intensive, with the rollout phase accounting for over 70% of total training time. Quantized RL training, particularly using FP8 precision, offers a promising approach to mitigating this bottleneck. A commonly adopted strategy applies FP8 precision during rollout while retaining BF16 precision for training. In this work, we present the first comprehensive study of FP8 RL training and demonstrate that the widely used BF16-training + FP8-rollout strategy suffers from severe training instability and catastrophic accuracy collapse under long-horizon rollouts and challenging tasks. Our analysis shows that these failures stem from the off-policy nature of the approach, which introduces substantial numerical mismatch between training and inference. Motivated by these observations, we propose Jet-RL, an FP8 RL training framework that enables robust and stable RL optimization. The key idea is to adopt a unified FP8 precision flow for both training and rollout, thereby minimizing numerical discrepancies and eliminating the need for inefficient inter-step calibration. Extensive experiments validate the effectiveness of Jet-RL: our method achieves up to 33% speedup in the rollout phase, up to 41% speedup in the training phase, and a 16% end-to-end speedup over BF16 training, while maintaining stable convergence across all settings and incurring negligible accuracy degradation.
Radial Attention: $O(n\log n)$ Sparse Attention with Energy Decay for Long Video Generation
Jun 24, 2025Recent advances in diffusion models have enabled high-quality video generation, but the additional temporal dimension significantly increases computational costs, making training and inference on long videos prohibitively expensive. In this paper, we identify a phenomenon we term Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature. Motivated by this, we propose Radial Attention, a scalable sparse attention mechanism with $O(n \log n)$ complexity that translates energy decay into exponentially decaying compute density, which is significantly more efficient than standard $O(n^2)$ dense attention and more expressive than linear attention. Specifically, Radial Attention employs a simple, static attention mask where each token attends to spatially nearby tokens, with the attention window size shrinking with temporal distance. Moreover, it allows pre-trained video diffusion models to extend their generation length with efficient LoRA-based fine-tuning. Extensive experiments show that Radial Attention maintains video quality across Wan2.1-14B, HunyuanVideo, and Mochi 1, achieving up to a 1.9$\times$ speedup over the original dense attention. With minimal tuning, it enables video generation up to 4$\times$ longer while reducing training costs by up to 4.4$\times$ compared to direct fine-tuning and accelerating inference by up to 3.7$\times$ compared to dense attention inference.
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
May 24, 2025Diffusion Transformers (DiTs) are essential for video generation but suffer from significant latency due to the quadratic complexity of attention. By computing only critical tokens, sparse attention reduces computational costs and offers a promising acceleration approach. However, we identify that existing methods fail to approach optimal generation quality under the same computation budget for two reasons: (1) Inaccurate critical token identification: current methods cluster tokens based on position rather than semantics, leading to imprecise aggregated representations. (2) Excessive computation waste: critical tokens are scattered among non-critical ones, leading to wasted computation on GPUs, which are optimized for processing contiguous tokens. In this paper, we propose SVG2, a training-free framework that maximizes identification accuracy and minimizes computation waste, achieving a Pareto frontier trade-off between generation quality and efficiency. The core of SVG2 is semantic-aware permutation, which clusters and reorders tokens based on semantic similarity using k-means. This approach ensures both a precise cluster representation, improving identification accuracy, and a densified layout of critical tokens, enabling efficient computation without padding. Additionally, SVG2 integrates top-p dynamic budget control and customized kernel implementations, achieving up to 2.30x and 1.89x speedup while maintaining a PSNR of up to 30 and 26 on HunyuanVideo and Wan 2.1, respectively.
LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
Feb 20, 2025Large language models (LLMs) have shown remarkable potential in processing long sequences, yet efficiently serving these long-context models remains challenging due to the quadratic computational complexity of attention in the prefilling stage and the large memory footprint of the KV cache in the decoding stage. To address these issues, we introduce LServe, an efficient system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. LServe demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. This design enables multiplicative speedups by combining these optimizations. Specifically, we convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we find that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. We then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. On average, LServe accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity
Feb 03, 2025



Diffusion Transformers (DiTs) dominate video generation but their high computational cost severely limits real-world applicability, usually requiring tens of minutes to generate a few seconds of video even on high-performance GPUs. This inefficiency primarily arises from the quadratic computational complexity of 3D Full Attention with respect to the context length. In this paper, we propose a training-free framework termed Sparse VideoGen (SVG) that leverages the inherent sparsity in 3D Full Attention to boost inference efficiency. We reveal that the attention heads can be dynamically classified into two groups depending on distinct sparse patterns: (1) Spatial Head, where only spatially-related tokens within each frame dominate the attention output, and (2) Temporal Head, where only temporally-related tokens across different frames dominate. Based on this insight, SVG proposes an online profiling strategy to capture the dynamic sparse patterns and predicts the type of attention head. Combined with a novel hardware-efficient tensor layout transformation and customized kernel implementations, SVG achieves up to 2.28x and 2.33x end-to-end speedup on CogVideoX-v1.5 and HunyuanVideo, respectively, while preserving generation quality.
SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
Jan 30, 2025



This paper presents SANA-1.5, a linear Diffusion Transformer for efficient scaling in text-to-image generation. Building upon SANA-1.0, we introduce three key innovations: (1) Efficient Training Scaling: A depth-growth paradigm that enables scaling from 1.6B to 4.8B parameters with significantly reduced computational resources, combined with a memory-efficient 8-bit optimizer. (2) Model Depth Pruning: A block importance analysis technique for efficient model compression to arbitrary sizes with minimal quality loss. (3) Inference-time Scaling: A repeated sampling strategy that trades computation for model capacity, enabling smaller models to match larger model quality at inference time. Through these strategies, SANA-1.5 achieves a text-image alignment score of 0.72 on GenEval, which can be further improved to 0.80 through inference scaling, establishing a new SoTA on GenEval benchmark. These innovations enable efficient model scaling across different compute budgets while maintaining high quality, making high-quality image generation more accessible.
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
Nov 07, 2024



Diffusion models have been proven highly effective at generating high-quality images. However, as these models grow larger, they require significantly more memory and suffer from higher latency, posing substantial challenges for deployment. In this work, we aim to accelerate diffusion models by quantizing their weights and activations to 4 bits. At such an aggressive level, both weights and activations are highly sensitive, where conventional post-training quantization methods for large language models like smoothing become insufficient. To overcome this limitation, we propose SVDQuant, a new 4-bit quantization paradigm. Different from smoothing which redistributes outliers between weights and activations, our approach absorbs these outliers using a low-rank branch. We first consolidate the outliers by shifting them from activations to weights, then employ a high-precision low-rank branch to take in the weight outliers with Singular Value Decomposition (SVD). This process eases the quantization on both sides. However, na\"{\i}vely running the low-rank branch independently incurs significant overhead due to extra data movement of activations, negating the quantization speedup. To address this, we co-design an inference engine Nunchaku that fuses the kernels of the low-rank branch into those of the low-bit branch to cut off redundant memory access. It can also seamlessly support off-the-shelf low-rank adapters (LoRAs) without the need for re-quantization. Extensive experiments on SDXL, PixArt-$\Sigma$, and FLUX.1 validate the effectiveness of SVDQuant in preserving image quality. We reduce the memory usage for the 12B FLUX.1 models by 3.5$\times$, achieving 3.0$\times$ speedup over the 4-bit weight-only quantized baseline on the 16GB laptop 4090 GPU, paving the way for more interactive applications on PCs. Our quantization library and inference engine are open-sourced.
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Oct 15, 2024



We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096$\times$4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8$\times$, we trained an AE that can compress images 32$\times$, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024$\times$1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
May 07, 2024
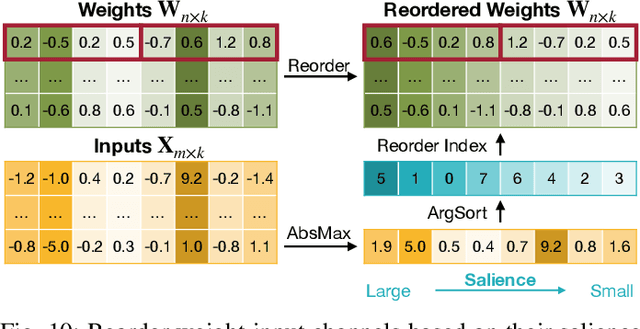
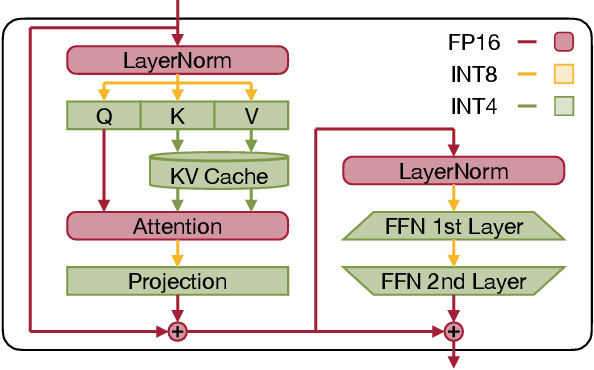
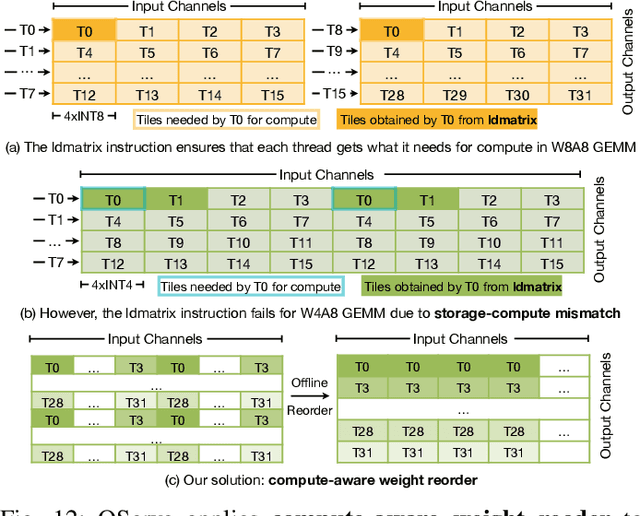
Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of-the-art INT4 quantization techniques only accelerate low-batch, edge LLM inference, failing to deliver performance gains in large-batch, cloud-based LLM serving. We uncover a critical issue: existing INT4 quantization methods suffer from significant runtime overhead (20-90%) when dequantizing either weights or partial sums on GPUs. To address this challenge, we introduce QoQ, a W4A8KV4 quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache. QoQ stands for quattuor-octo-quattuor, which represents 4-8-4 in Latin. QoQ is implemented by the QServe inference library that achieves measured speedup. The key insight driving QServe is that the efficiency of LLM serving on GPUs is critically influenced by operations on low-throughput CUDA cores. Building upon this insight, in QoQ algorithm, we introduce progressive quantization that can allow low dequantization overhead in W4A8 GEMM. Additionally, we develop SmoothAttention to effectively mitigate the accuracy degradation incurred by 4-bit KV quantization. In the QServe system, we perform compute-aware weight reordering and take advantage of register-level parallelism to reduce dequantization latency. We also make fused attention memory-bound, harnessing the performance gain brought by KV4 quantization. As a result, QServe improves the maximum achievable serving throughput of Llama-3-8B by 1.2x on A100, 1.4x on L40S; and Qwen1.5-72B by 2.4x on A100, 3.5x on L40S, compared to TensorRT-LLM. Remarkably, QServe on L40S GPU can achieve even higher throughput than TensorRT-LLM on A100. Thus, QServe effectively reduces the dollar cost of LLM serving by 3x. Code is available at https://github.com/mit-han-lab/qserve.