 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025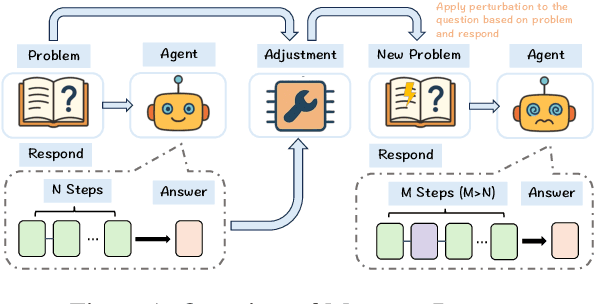

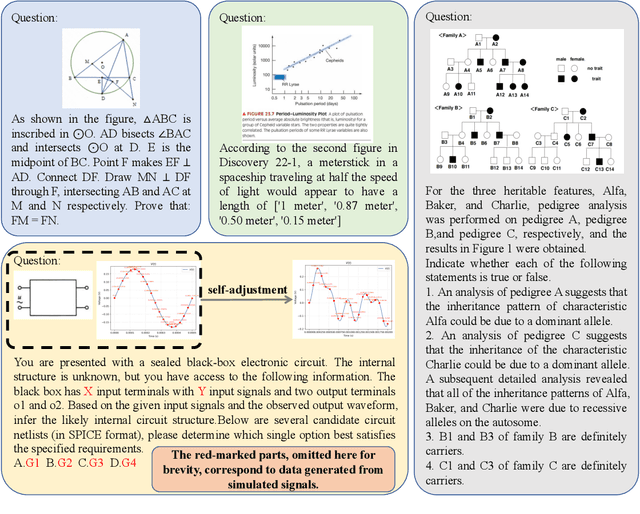
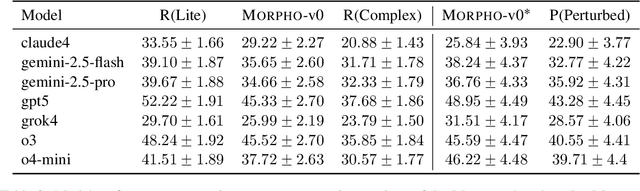
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
SALM: Spatial Audio Language Model with Structured Embeddings for Understanding and Editing
Jul 22, 2025Spatial audio understanding is essential for accurately perceiving and interpreting acoustic environments. However, existing audio-language models struggle with processing spatial audio and perceiving spatial acoustic scenes. We introduce the Spatial Audio Language Model (SALM), a novel framework that bridges spatial audio and language via multi-modal contrastive learning. SALM consists of a text encoder and a dual-branch audio encoder, decomposing spatial sound into semantic and spatial components through structured audio embeddings. Key features of SALM include seamless alignment of spatial and text representations, separate and joint extraction of spatial and semantic information, zero-shot direction classification and robust support for spatial audio editing. Experimental results demonstrate that SALM effectively captures and aligns cross-modal representations. Furthermore, it supports advanced editing capabilities, such as altering directional audio using text-based embeddings.
Radial Attention: $O(n\log n)$ Sparse Attention with Energy Decay for Long Video Generation
Jun 24, 2025Recent advances in diffusion models have enabled high-quality video generation, but the additional temporal dimension significantly increases computational costs, making training and inference on long videos prohibitively expensive. In this paper, we identify a phenomenon we term Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature. Motivated by this, we propose Radial Attention, a scalable sparse attention mechanism with $O(n \log n)$ complexity that translates energy decay into exponentially decaying compute density, which is significantly more efficient than standard $O(n^2)$ dense attention and more expressive than linear attention. Specifically, Radial Attention employs a simple, static attention mask where each token attends to spatially nearby tokens, with the attention window size shrinking with temporal distance. Moreover, it allows pre-trained video diffusion models to extend their generation length with efficient LoRA-based fine-tuning. Extensive experiments show that Radial Attention maintains video quality across Wan2.1-14B, HunyuanVideo, and Mochi 1, achieving up to a 1.9$\times$ speedup over the original dense attention. With minimal tuning, it enables video generation up to 4$\times$ longer while reducing training costs by up to 4.4$\times$ compared to direct fine-tuning and accelerating inference by up to 3.7$\times$ compared to dense attention inference.
PSELDNets: Pre-trained Neural Networks on Large-scale Synthetic Datasets for Sound Event Localization and Detection
Nov 10, 2024



Sound event localization and detection (SELD) has seen substantial advancements through learning-based methods. These systems, typically trained from scratch on specific datasets, have shown considerable generalization capabilities. Recently, deep neural networks trained on large-scale datasets have achieved remarkable success in the sound event classification (SEC) field, prompting an open question of whether these advancements can be extended to develop general-purpose SELD models. In this paper, leveraging the power of pre-trained SEC models, we propose pre-trained SELD networks (PSELDNets) on large-scale synthetic datasets. These synthetic datasets, generated by convolving sound events with simulated spatial room impulse responses (SRIRs), contain 1,167 hours of audio clips with an ontology of 170 sound classes. These PSELDNets are transferred to downstream SELD tasks. When we adapt PSELDNets to specific scenarios, particularly in low-resource data cases, we introduce a data-efficient fine-tuning method, AdapterBit. PSELDNets are evaluated on a synthetic-test-set using collected SRIRs from TAU Spatial Room Impulse Response Database (TAU-SRIR DB) and achieve satisfactory performance. We also conduct our experiments to validate the transferability of PSELDNets to three publicly available datasets and our own collected audio recordings. Results demonstrate that PSELDNets surpass state-of-the-art systems across all publicly available datasets. Given the need for direction-of-arrival estimation, SELD generally relies on sufficient multi-channel audio clips. However, incorporating the AdapterBit, PSELDNets show more efficient adaptability to various tasks using minimal multi-channel or even just monophonic audio clips, outperforming the traditional fine-tuning approaches.
Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection
Dec 27, 2023



Environment shifts and conflicts present significant challenges for learning-based sound event localization and detection (SELD) methods. SELD systems, when trained in particular acoustic settings, often show restricted generalization capabilities for diverse acoustic environments. Furthermore, it is notably costly to obtain annotated samples for spatial sound events. Deploying a SELD system in a new environment requires extensive time for re-training and fine-tuning. To overcome these challenges, we propose environment-adaptive Meta-SELD, designed for efficient adaptation to new environments using minimal data. Our method specifically utilizes computationally synthesized spatial data and employs Model-Agnostic Meta-Learning (MAML) on a pre-trained, environment-independent model. The method then utilizes fast adaptation to unseen real-world environments using limited samples from the respective environments. Inspired by the Learning-to-Forget approach, we introduce the concept of selective memory as a strategy for resolving conflicts across environments. This approach involves selectively memorizing target-environment-relevant information and adapting to the new environments through the selective attenuation of model parameters. In addition, we introduce environment representations to characterize different acoustic settings, enhancing the adaptability of our attenuation approach to various environments. We evaluate our proposed method on the development set of the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSS23) dataset and computationally synthesized scenes. Experimental results demonstrate the superior performance of the proposed method compared to conventional supervised learning methods, particularly in localization.
META-SELD: Meta-Learning for Fast Adaptation to the new environment in Sound Event Localization and Detection
Aug 17, 2023


For learning-based sound event localization and detection (SELD) methods, different acoustic environments in the training and test sets may result in large performance differences in the validation and evaluation stages. Different environments, such as different sizes of rooms, different reverberation times, and different background noise, may be reasons for a learning-based system to fail. On the other hand, acquiring annotated spatial sound event samples, which include onset and offset time stamps, class types of sound events, and direction-of-arrival (DOA) of sound sources is very expensive. In addition, deploying a SELD system in a new environment often poses challenges due to time-consuming training and fine-tuning processes. To address these issues, we propose Meta-SELD, which applies meta-learning methods to achieve fast adaptation to new environments. More specifically, based on Model Agnostic Meta-Learning (MAML), the proposed Meta-SELD aims to find good meta-initialized parameters to adapt to new environments with only a small number of samples and parameter updating iterations. We can then quickly adapt the meta-trained SELD model to unseen environments. Our experiments compare fine-tuning methods from pre-trained SELD models with our Meta-SELD on the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSSS23) dataset. The evaluation results demonstrate the effectiveness of Meta-SELD when adapting to new environments.
Sound Event Localization and Detection for Real Spatial Sound Scenes: Event-Independent Network and Data Augmentation Chains
Sep 09, 2022

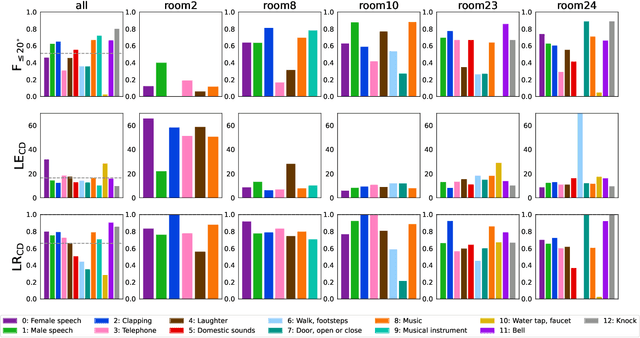
Sound event localization and detection (SELD) is a joint task of sound event detection and direction-of-arrival estimation. In DCASE 2022 Task 3, types of data transform from computationally generated spatial recordings to recordings of real-sound scenes. Our system submitted to the DCASE 2022 Task 3 is based on our previous proposed Event-Independent Network V2 (EINV2) with a novel data augmentation method. Our method employs EINV2 with a track-wise output format, permutation-invariant training, and a soft parameter-sharing strategy, to detect different sound events of the same class but in different locations. The Conformer structure is used for extending EINV2 to learn local and global features. A data augmentation method, which contains several data augmentation chains composed of stochastic combinations of several different data augmentation operations, is utilized to generalize the model. To mitigate the lack of real-scene recordings in the development dataset and the presence of sound events being unbalanced, we exploit FSD50K, AudioSet, and TAU Spatial Room Impulse Response Database (TAU-SRIR DB) to generate simulated datasets for training. We present results on the validation set of Sony-TAu Realistic Spatial Soundscapes 2022 (STARSS22) in detail. Experimental results indicate that the ability to generalize to different environments and unbalanced performance among different classes are two main challenges. We evaluate our proposed method in Task 3 of the DCASE 2022 challenge and obtain the second rank in the teams ranking. Source code is released.
A Track-Wise Ensemble Event Independent Network for Polyphonic Sound Event Localization and Detection
Mar 19, 2022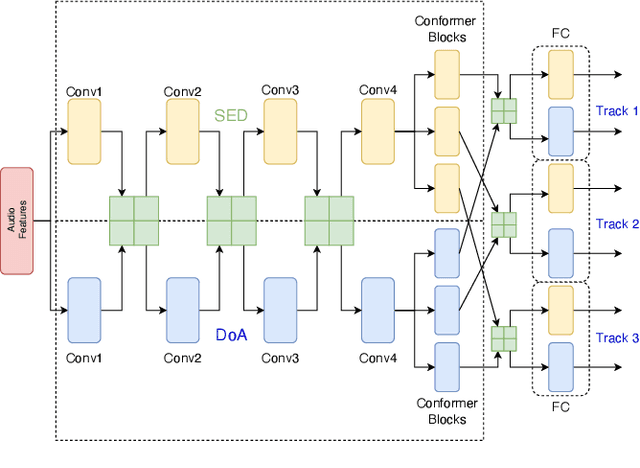


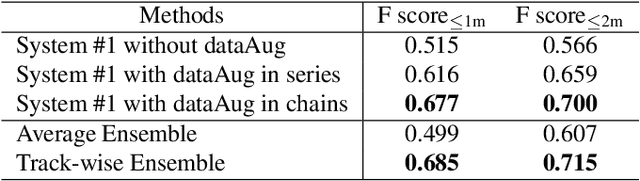
Polyphonic sound event localization and detection (SELD) aims at detecting types of sound events with corresponding temporal activities and spatial locations. In this paper, a track-wise ensemble event independent network with a novel data augmentation method is proposed. The proposed model is based on our previous proposed Event-Independent Network V2 and is extended by conformer blocks and dense blocks. The track-wise ensemble model with track-wise output format is proposed to solve an ensemble model problem for track-wise output format that track permutation may occur among different models. The data augmentation approach contains several data augmentation chains, which are composed of random combinations of several data augmentation operations. The method also utilizes log-mel spectrograms, intensity vectors, and Spatial Cues-Augmented Log-Spectrogram (SALSA) for different models. We evaluate our proposed method in the Task of the L3DAS22 challenge and obtain the top ranking solution with a location-dependent F-score to be 0.699. Source code is released.