 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Frame Preservation in Autoregressive Video Memory Compression
Dec 29, 2025We present PFP, a neural network structure to compress long videos into short contexts, with an explicit pretraining objective to preserve the high-frequency details of single frames at arbitrary temporal positions. The baseline model can compress a 20-second video into a context at about 5k length, where random frames can be retrieved with perceptually preserved appearances. Such pretrained models can be directly fine-tuned as memory encoders for autoregressive video models, enabling long history memory with low context cost and relatively low fidelity loss. We evaluate the framework with ablative settings and discuss the trade-offs of possible neural architecture designs.
StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Nov 10, 2025



Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
Taming Flow-based I2V Models for Creative Video Editing
Sep 26, 2025Although image editing techniques have advanced significantly, video editing, which aims to manipulate videos according to user intent, remains an emerging challenge. Most existing image-conditioned video editing methods either require inversion with model-specific design or need extensive optimization, limiting their capability of leveraging up-to-date image-to-video (I2V) models to transfer the editing capability of image editing models to the video domain. To this end, we propose IF-V2V, an Inversion-Free method that can adapt off-the-shelf flow-matching-based I2V models for video editing without significant computational overhead. To circumvent inversion, we devise Vector Field Rectification with Sample Deviation to incorporate information from the source video into the denoising process by introducing a deviation term into the denoising vector field. To further ensure consistency with the source video in a model-agnostic way, we introduce Structure-and-Motion-Preserving Initialization to generate motion-aware temporally correlated noise with structural information embedded. We also present a Deviation Caching mechanism to minimize the additional computational cost for denoising vector rectification without significantly impacting editing quality. Evaluations demonstrate that our method achieves superior editing quality and consistency over existing approaches, offering a lightweight plug-and-play solution to realize visual creativity.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025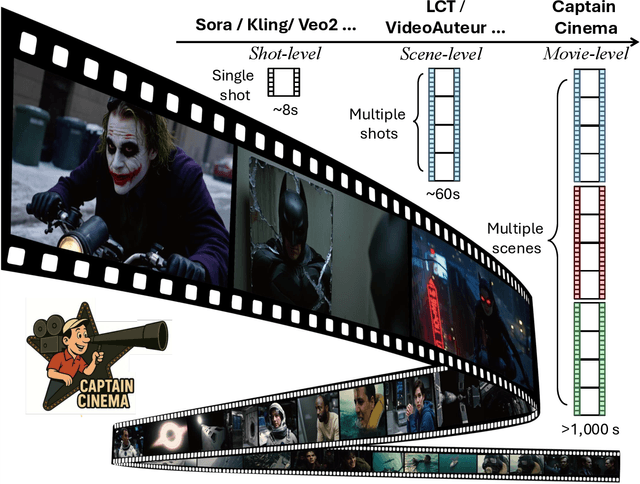
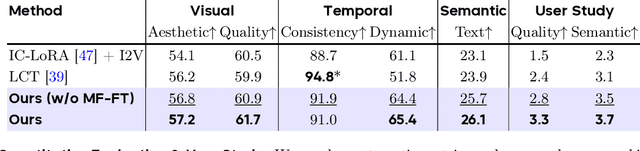

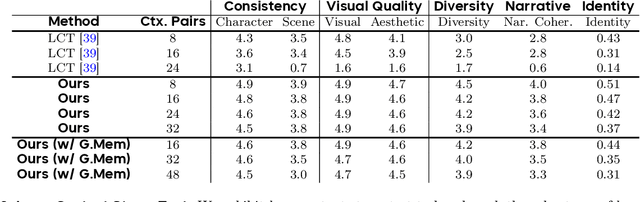
We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai
Radial Attention: $O(n\log n)$ Sparse Attention with Energy Decay for Long Video Generation
Jun 24, 2025Recent advances in diffusion models have enabled high-quality video generation, but the additional temporal dimension significantly increases computational costs, making training and inference on long videos prohibitively expensive. In this paper, we identify a phenomenon we term Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature. Motivated by this, we propose Radial Attention, a scalable sparse attention mechanism with $O(n \log n)$ complexity that translates energy decay into exponentially decaying compute density, which is significantly more efficient than standard $O(n^2)$ dense attention and more expressive than linear attention. Specifically, Radial Attention employs a simple, static attention mask where each token attends to spatially nearby tokens, with the attention window size shrinking with temporal distance. Moreover, it allows pre-trained video diffusion models to extend their generation length with efficient LoRA-based fine-tuning. Extensive experiments show that Radial Attention maintains video quality across Wan2.1-14B, HunyuanVideo, and Mochi 1, achieving up to a 1.9$\times$ speedup over the original dense attention. With minimal tuning, it enables video generation up to 4$\times$ longer while reducing training costs by up to 4.4$\times$ compared to direct fine-tuning and accelerating inference by up to 3.7$\times$ compared to dense attention inference.
Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
Apr 21, 2025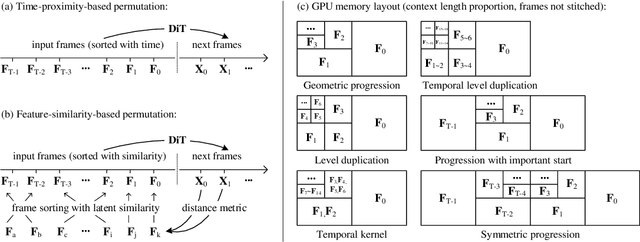
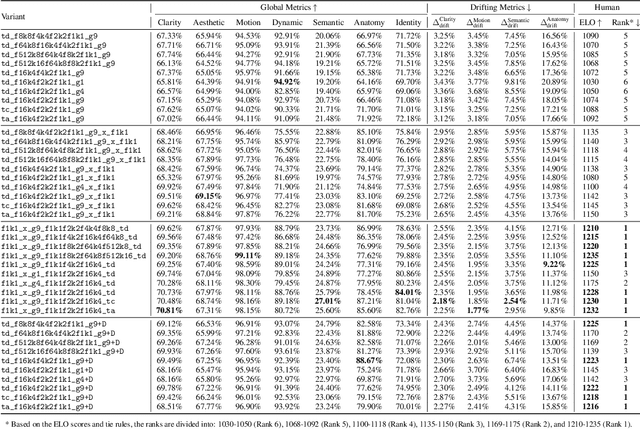
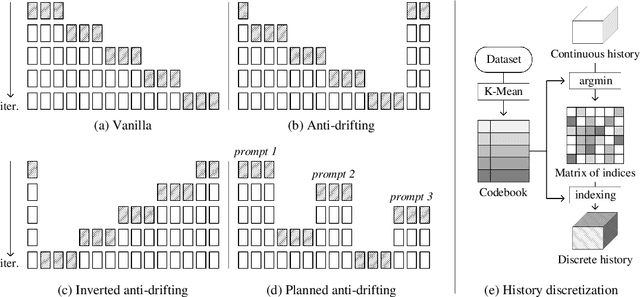
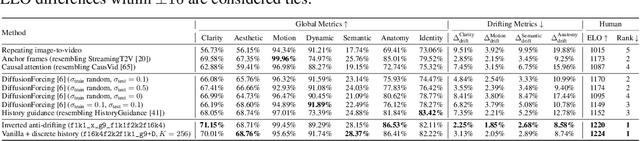
We present a neural network structure, FramePack, to train next-frame (or next-frame-section) prediction models for video generation. The FramePack compresses input frames to make the transformer context length a fixed number regardless of the video length. As a result, we are able to process a large number of frames using video diffusion with computation bottleneck similar to image diffusion. This also makes the training video batch sizes significantly higher (batch sizes become comparable to image diffusion training). We also propose an anti-drifting sampling method that generates frames in inverted temporal order with early-established endpoints to avoid exposure bias (error accumulation over iterations). Finally, we show that existing video diffusion models can be finetuned with FramePack, and their visual quality may be improved because the next-frame prediction supports more balanced diffusion schedulers with less extreme flow shift timesteps.
Instance Segmentation of Scene Sketches Using Natural Image Priors
Feb 13, 2025
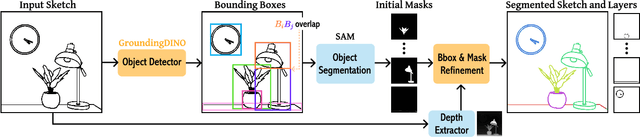
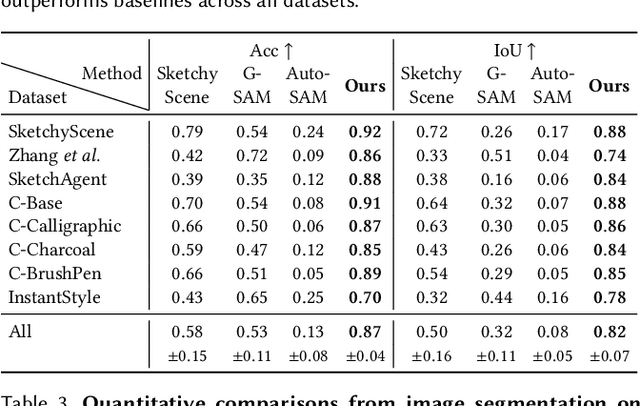
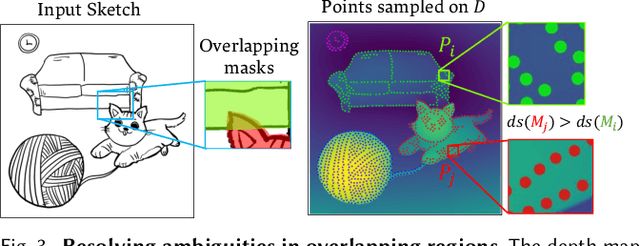
Sketch segmentation involves grouping pixels within a sketch that belong to the same object or instance. It serves as a valuable tool for sketch editing tasks, such as moving, scaling, or removing specific components. While image segmentation models have demonstrated remarkable capabilities in recent years, sketches present unique challenges for these models due to their sparse nature and wide variation in styles. We introduce SketchSeg, a method for instance segmentation of raster scene sketches. Our approach adapts state-of-the-art image segmentation and object detection models to the sketch domain by employing class-agnostic fine-tuning and refining segmentation masks using depth cues. Furthermore, our method organizes sketches into sorted layers, where occluded instances are inpainted, enabling advanced sketch editing applications. As existing datasets in this domain lack variation in sketch styles, we construct a synthetic scene sketch segmentation dataset featuring sketches with diverse brush strokes and varying levels of detail. We use this dataset to demonstrate the robustness of our approach and will release it to promote further research in the field. Project webpage: https://sketchseg.github.io/sketch-seg/
Transparent Image Layer Diffusion using Latent Transparency
Mar 01, 2024We present LayerDiffuse, an approach enabling large-scale pretrained latent diffusion models to generate transparent images. The method allows generation of single transparent images or of multiple transparent layers. The method learns a "latent transparency" that encodes alpha channel transparency into the latent manifold of a pretrained latent diffusion model. It preserves the production-ready quality of the large diffusion model by regulating the added transparency as a latent offset with minimal changes to the original latent distribution of the pretrained model. In this way, any latent diffusion model can be converted into a transparent image generator by finetuning it with the adjusted latent space. We train the model with 1M transparent image layer pairs collected using a human-in-the-loop collection scheme. We show that latent transparency can be applied to different open source image generators, or be adapted to various conditional control systems to achieve applications like foreground/background-conditioned layer generation, joint layer generation, structural control of layer contents, etc. A user study finds that in most cases (97%) users prefer our natively generated transparent content over previous ad-hoc solutions such as generating and then matting. Users also report the quality of our generated transparent images is comparable to real commercial transparent assets like Adobe Stock.
Adding Conditional Control to Text-to-Image Diffusion Models
Feb 10, 2023We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.