 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Guided Geometric Stylization of 3D Meshes
Apr 09, 2026Recent generative models can create visually plausible 3D representations of objects. However, the generation process often allows for implicit control signals, such as contextual descriptions, and rarely supports bold geometric distortions beyond existing data distributions. We propose a geometric stylization framework that deforms a 3D mesh, allowing it to express the style of an image. While style is inherently ambiguous, we utilize pre-trained diffusion models to extract an abstract representation of the provided image. Our coarse-to-fine stylization pipeline can drastically deform the input 3D model to express a diverse range of geometric variations while retaining the valid topology of the original mesh and part-level semantics. We also propose an approximate VAE encoder that provides efficient and reliable gradients from mesh renderings. Extensive experiments demonstrate that our method can create stylized 3D meshes that reflect unique geometric features of the pictured assets, such as expressive poses and silhouettes, thereby supporting the creation of distinctive artistic 3D creations. Project page: https://changwoonchoi.github.io/GeoStyle
Teaching an Agent to Sketch One Part at a Time
Mar 19, 2026We develop a method for producing vector sketches one part at a time. To do this, we train a multi-modal language model-based agent using a novel multi-turn process-reward reinforcement learning following supervised fine-tuning. Our approach is enabled by a new dataset we call ControlSketch-Part, containing rich part-level annotations for sketches, obtained using a novel, generic automatic annotation pipeline that segments vector sketches into semantic parts and assigns paths to parts with a structured multi-stage labeling process. Our results indicate that incorporating structured part-level data and providing agent with the visual feedback through the process enables interpretable, controllable, and locally editable text-to-vector sketch generation.
VideoSketcher: Video Models Prior Enable Versatile Sequential Sketch Generation
Feb 17, 2026Sketching is inherently a sequential process, in which strokes are drawn in a meaningful order to explore and refine ideas. However, most generative models treat sketches as static images, overlooking the temporal structure that underlies creative drawing. We present a data-efficient approach for sequential sketch generation that adapts pretrained text-to-video diffusion models to generate sketching processes. Our key insight is that large language models and video diffusion models offer complementary strengths for this task: LLMs provide semantic planning and stroke ordering, while video diffusion models serve as strong renderers that produce high-quality, temporally coherent visuals. We leverage this by representing sketches as short videos in which strokes are progressively drawn on a blank canvas, guided by text-specified ordering instructions. We introduce a two-stage fine-tuning strategy that decouples the learning of stroke ordering from the learning of sketch appearance. Stroke ordering is learned using synthetic shape compositions with controlled temporal structure, while visual appearance is distilled from as few as seven manually authored sketching processes that capture both global drawing order and the continuous formation of individual strokes. Despite the extremely limited amount of human-drawn sketch data, our method generates high-quality sequential sketches that closely follow text-specified orderings while exhibiting rich visual detail. We further demonstrate the flexibility of our approach through extensions such as brush style conditioning and autoregressive sketch generation, enabling additional controllability and interactive, collaborative drawing.
Inspiration Seeds: Learning Non-Literal Visual Combinations for Generative Exploration
Feb 09, 2026While generative models have become powerful tools for image synthesis, they are typically optimized for executing carefully crafted textual prompts, offering limited support for the open-ended visual exploration that often precedes idea formation. In contrast, designers frequently draw inspiration from loosely connected visual references, seeking emergent connections that spark new ideas. We propose Inspiration Seeds, a generative framework that shifts image generation from final execution to exploratory ideation. Given two input images, our model produces diverse, visually coherent compositions that reveal latent relationships between inputs, without relying on user-specified text prompts. Our approach is feed-forward, trained on synthetic triplets of decomposed visual aspects derived entirely through visual means: we use CLIP Sparse Autoencoders to extract editing directions in CLIP latent space and isolate concept pairs. By removing the reliance on language and enabling fast, intuitive recombination, our method supports visual ideation at the early and ambiguous stages of creative work.
Instance Segmentation of Scene Sketches Using Natural Image Priors
Feb 13, 2025
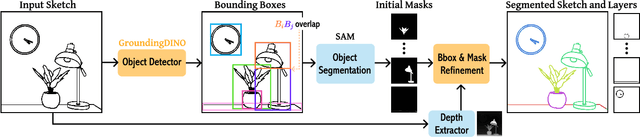
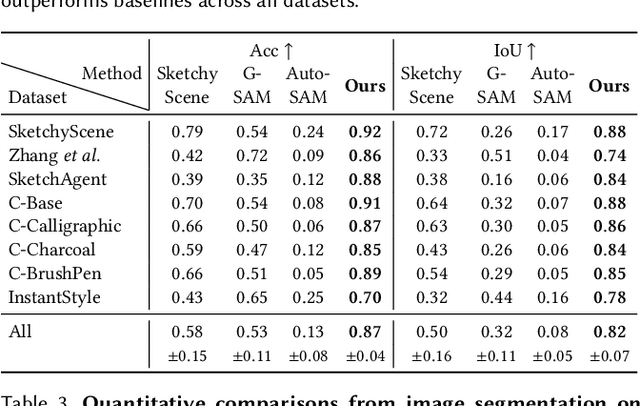
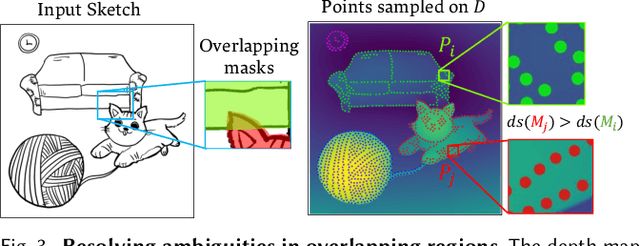
Sketch segmentation involves grouping pixels within a sketch that belong to the same object or instance. It serves as a valuable tool for sketch editing tasks, such as moving, scaling, or removing specific components. While image segmentation models have demonstrated remarkable capabilities in recent years, sketches present unique challenges for these models due to their sparse nature and wide variation in styles. We introduce SketchSeg, a method for instance segmentation of raster scene sketches. Our approach adapts state-of-the-art image segmentation and object detection models to the sketch domain by employing class-agnostic fine-tuning and refining segmentation masks using depth cues. Furthermore, our method organizes sketches into sorted layers, where occluded instances are inpainted, enabling advanced sketch editing applications. As existing datasets in this domain lack variation in sketch styles, we construct a synthetic scene sketch segmentation dataset featuring sketches with diverse brush strokes and varying levels of detail. We use this dataset to demonstrate the robustness of our approach and will release it to promote further research in the field. Project webpage: https://sketchseg.github.io/sketch-seg/
SwiftSketch: A Diffusion Model for Image-to-Vector Sketch Generation
Feb 12, 2025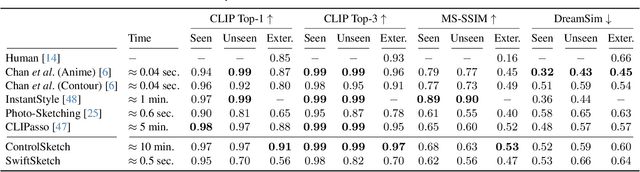
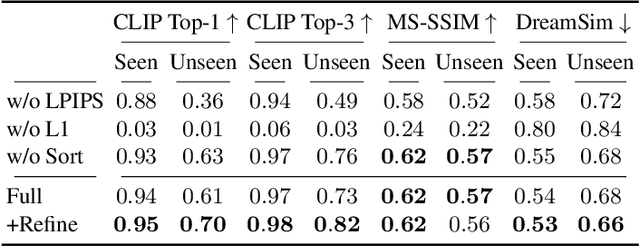
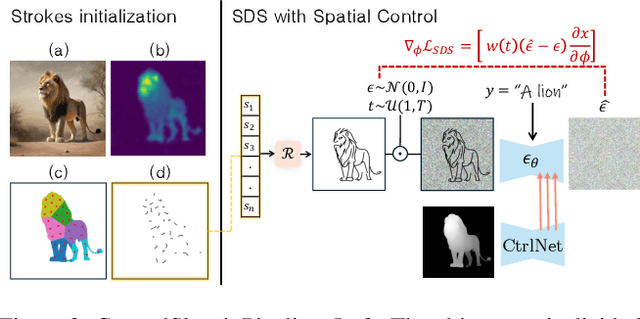
Recent advancements in large vision-language models have enabled highly expressive and diverse vector sketch generation. However, state-of-the-art methods rely on a time-consuming optimization process involving repeated feedback from a pretrained model to determine stroke placement. Consequently, despite producing impressive sketches, these methods are limited in practical applications. In this work, we introduce SwiftSketch, a diffusion model for image-conditioned vector sketch generation that can produce high-quality sketches in less than a second. SwiftSketch operates by progressively denoising stroke control points sampled from a Gaussian distribution. Its transformer-decoder architecture is designed to effectively handle the discrete nature of vector representation and capture the inherent global dependencies between strokes. To train SwiftSketch, we construct a synthetic dataset of image-sketch pairs, addressing the limitations of existing sketch datasets, which are often created by non-artists and lack professional quality. For generating these synthetic sketches, we introduce ControlSketch, a method that enhances SDS-based techniques by incorporating precise spatial control through a depth-aware ControlNet. We demonstrate that SwiftSketch generalizes across diverse concepts, efficiently producing sketches that combine high fidelity with a natural and visually appealing style.
NeuralSVG: An Implicit Representation for Text-to-Vector Generation
Jan 07, 2025



Vector graphics are essential in design, providing artists with a versatile medium for creating resolution-independent and highly editable visual content. Recent advancements in vision-language and diffusion models have fueled interest in text-to-vector graphics generation. However, existing approaches often suffer from over-parameterized outputs or treat the layered structure - a core feature of vector graphics - as a secondary goal, diminishing their practical use. Recognizing the importance of layered SVG representations, we propose NeuralSVG, an implicit neural representation for generating vector graphics from text prompts. Inspired by Neural Radiance Fields (NeRFs), NeuralSVG encodes the entire scene into the weights of a small MLP network, optimized using Score Distillation Sampling (SDS). To encourage a layered structure in the generated SVG, we introduce a dropout-based regularization technique that strengthens the standalone meaning of each shape. We additionally demonstrate that utilizing a neural representation provides an added benefit of inference-time control, enabling users to dynamically adapt the generated SVG based on user-provided inputs, all with a single learned representation. Through extensive qualitative and quantitative evaluations, we demonstrate that NeuralSVG outperforms existing methods in generating structured and flexible SVG.
Generative Visual Communication in the Era of Vision-Language Models
Nov 27, 2024



Visual communication, dating back to prehistoric cave paintings, is the use of visual elements to convey ideas and information. In today's visually saturated world, effective design demands an understanding of graphic design principles, visual storytelling, human psychology, and the ability to distill complex information into clear visuals. This dissertation explores how recent advancements in vision-language models (VLMs) can be leveraged to automate the creation of effective visual communication designs. Although generative models have made great progress in generating images from text, they still struggle to simplify complex ideas into clear, abstract visuals and are constrained by pixel-based outputs, which lack flexibility for many design tasks. To address these challenges, we constrain the models' operational space and introduce task-specific regularizations. We explore various aspects of visual communication, namely, sketches and visual abstraction, typography, animation, and visual inspiration.
SketchAgent: Language-Driven Sequential Sketch Generation
Nov 26, 2024Sketching serves as a versatile tool for externalizing ideas, enabling rapid exploration and visual communication that spans various disciplines. While artificial systems have driven substantial advances in content creation and human-computer interaction, capturing the dynamic and abstract nature of human sketching remains challenging. In this work, we introduce SketchAgent, a language-driven, sequential sketch generation method that enables users to create, modify, and refine sketches through dynamic, conversational interactions. Our approach requires no training or fine-tuning. Instead, we leverage the sequential nature and rich prior knowledge of off-the-shelf multimodal large language models (LLMs). We present an intuitive sketching language, introduced to the model through in-context examples, enabling it to "draw" using string-based actions. These are processed into vector graphics and then rendered to create a sketch on a pixel canvas, which can be accessed again for further tasks. By drawing stroke by stroke, our agent captures the evolving, dynamic qualities intrinsic to sketching. We demonstrate that SketchAgent can generate sketches from diverse prompts, engage in dialogue-driven drawing, and collaborate meaningfully with human users.
Implicit Style-Content Separation using B-LoRA
Mar 21, 2024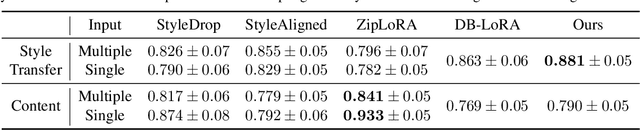

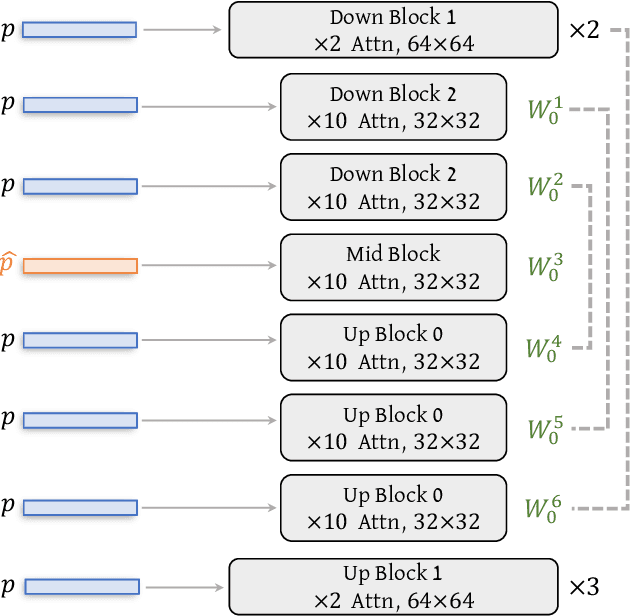

Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.