 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Motion-Action Modeling for Heterogeneous Robot Learning
Jun 16, 2026We present Unified Motion-Action (UMA) Model, an approach that uses 3D object motion trajectories as a shared interface to bridge visuomotor control and dynamics modeling. UMA treats object motion and robot actions as co-evolving variables under a masked generative objective, in which the mask pattern determines both the supervision regime during pretraining and the inference mode at deployment. Using hindsight-relabeled motion contexts and a contrastive objective that disentangles task intent from scene geometry, UMA enables multi-task pretraining across heterogeneous data sources without requiring manually annotated task instructions. At deployment, the same pretrained parameters support motion-conditioned visuomotor control, motion-based dynamics modeling, and task adaptation from few-shot demonstrations. Pretrained on a mixture of robot demonstrations, human videos, and simulated data, UMA consistently outperforms state-of-the-art baselines specialized for each inference mode.
SEVA: Leveraging sketches to evaluate alignment between human and machine visual abstraction
Dec 05, 2023
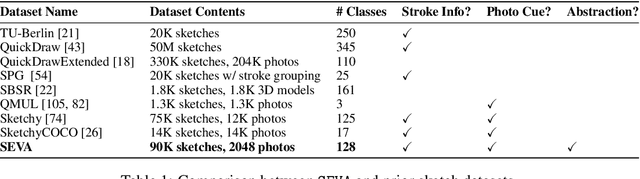
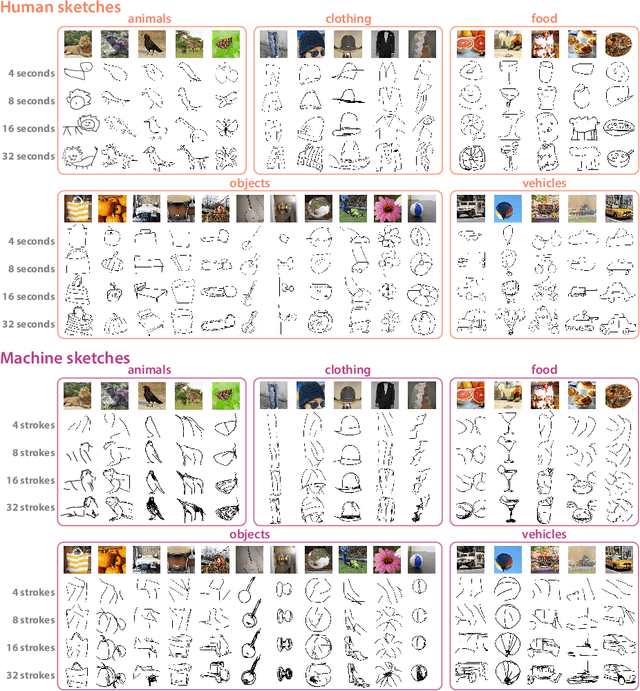
Sketching is a powerful tool for creating abstract images that are sparse but meaningful. Sketch understanding poses fundamental challenges for general-purpose vision algorithms because it requires robustness to the sparsity of sketches relative to natural visual inputs and because it demands tolerance for semantic ambiguity, as sketches can reliably evoke multiple meanings. While current vision algorithms have achieved high performance on a variety of visual tasks, it remains unclear to what extent they understand sketches in a human-like way. Here we introduce SEVA, a new benchmark dataset containing approximately 90K human-generated sketches of 128 object concepts produced under different time constraints, and thus systematically varying in sparsity. We evaluated a suite of state-of-the-art vision algorithms on their ability to correctly identify the target concept depicted in these sketches and to generate responses that are strongly aligned with human response patterns on the same sketch recognition task. We found that vision algorithms that better predicted human sketch recognition performance also better approximated human uncertainty about sketch meaning, but there remains a sizable gap between model and human response patterns. To explore the potential of models that emulate human visual abstraction in generative tasks, we conducted further evaluations of a recently developed sketch generation algorithm (Vinker et al., 2022) capable of generating sketches that vary in sparsity. We hope that public release of this dataset and evaluation protocol will catalyze progress towards algorithms with enhanced capacities for human-like visual abstraction.
Learning Dense Correspondences between Photos and Sketches
Jul 24, 2023Humans effortlessly grasp the connection between sketches and real-world objects, even when these sketches are far from realistic. Moreover, human sketch understanding goes beyond categorization -- critically, it also entails understanding how individual elements within a sketch correspond to parts of the physical world it represents. What are the computational ingredients needed to support this ability? Towards answering this question, we make two contributions: first, we introduce a new sketch-photo correspondence benchmark, $\textit{PSC6k}$, containing 150K annotations of 6250 sketch-photo pairs across 125 object categories, augmenting the existing Sketchy dataset with fine-grained correspondence metadata. Second, we propose a self-supervised method for learning dense correspondences between sketch-photo pairs, building upon recent advances in correspondence learning for pairs of photos. Our model uses a spatial transformer network to estimate the warp flow between latent representations of a sketch and photo extracted by a contrastive learning-based ConvNet backbone. We found that this approach outperformed several strong baselines and produced predictions that were quantitatively consistent with other warp-based methods. However, our benchmark also revealed systematic differences between predictions of the suite of models we tested and those of humans. Taken together, our work suggests a promising path towards developing artificial systems that achieve more human-like understanding of visual images at different levels of abstraction. Project page: https://photo-sketch-correspondence.github.io