 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncQA: Benchmarking Vision-Language Models on Visual Encodings for Charts
Aug 06, 2025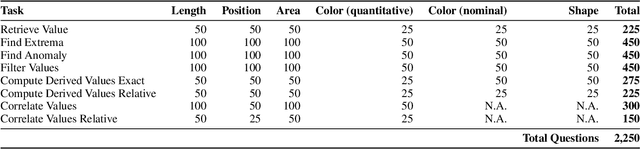


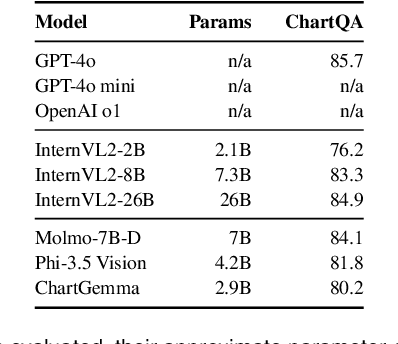
Multimodal vision-language models (VLMs) continue to achieve ever-improving scores on chart understanding benchmarks. Yet, we find that this progress does not fully capture the breadth of visual reasoning capabilities essential for interpreting charts. We introduce EncQA, a novel benchmark informed by the visualization literature, designed to provide systematic coverage of visual encodings and analytic tasks that are crucial for chart understanding. EncQA provides 2,076 synthetic question-answer pairs, enabling balanced coverage of six visual encoding channels (position, length, area, color quantitative, color nominal, and shape) and eight tasks (find extrema, retrieve value, find anomaly, filter values, compute derived value exact, compute derived value relative, correlate values, and correlate values relative). Our evaluation of 9 state-of-the-art VLMs reveals that performance varies significantly across encodings within the same task, as well as across tasks. Contrary to expectations, we observe that performance does not improve with model size for many task-encoding pairs. Our results suggest that advancing chart understanding requires targeted strategies addressing specific visual reasoning gaps, rather than solely scaling up model or dataset size.
Evaluating Steering Techniques using Human Similarity Judgments
May 25, 2025



Current evaluations of Large Language Model (LLM) steering techniques focus on task-specific performance, overlooking how well steered representations align with human cognition. Using a well-established triadic similarity judgment task, we assessed steered LLMs on their ability to flexibly judge similarity between concepts based on size or kind. We found that prompt-based steering methods outperformed other methods both in terms of steering accuracy and model-to-human alignment. We also found LLMs were biased towards 'kind' similarity and struggled with 'size' alignment. This evaluation approach, grounded in human cognition, adds further support to the efficacy of prompt-based steering and reveals privileged representational axes in LLMs prior to steering.
CHART-6: Human-Centered Evaluation of Data Visualization Understanding in Vision-Language Models
May 22, 2025



Data visualizations are powerful tools for communicating patterns in quantitative data. Yet understanding any data visualization is no small feat -- succeeding requires jointly making sense of visual, numerical, and linguistic inputs arranged in a conventionalized format one has previously learned to parse. Recently developed vision-language models are, in principle, promising candidates for developing computational models of these cognitive operations. However, it is currently unclear to what degree these models emulate human behavior on tasks that involve reasoning about data visualizations. This gap reflects limitations in prior work that has evaluated data visualization understanding in artificial systems using measures that differ from those typically used to assess these abilities in humans. Here we evaluated eight vision-language models on six data visualization literacy assessments designed for humans and compared model responses to those of human participants. We found that these models performed worse than human participants on average, and this performance gap persisted even when using relatively lenient criteria to assess model performance. Moreover, while relative performance across items was somewhat correlated between models and humans, all models produced patterns of errors that were reliably distinct from those produced by human participants. Taken together, these findings suggest significant opportunities for further development of artificial systems that might serve as useful models of how humans reason about data visualizations. All code and data needed to reproduce these results are available at: https://osf.io/e25mu/?view_only=399daff5a14d4b16b09473cf19043f18.
AI-enhanced semantic feature norms for 786 concepts
May 15, 2025Semantic feature norms have been foundational in the study of human conceptual knowledge, yet traditional methods face trade-offs between concept/feature coverage and verifiability of quality due to the labor-intensive nature of norming studies. Here, we introduce a novel approach that augments a dataset of human-generated feature norms with responses from large language models (LLMs) while verifying the quality of norms against reliable human judgments. We find that our AI-enhanced feature norm dataset, NOVA: Norms Optimized Via AI, shows much higher feature density and overlap among concepts while outperforming a comparable human-only norm dataset and word-embedding models in predicting people's semantic similarity judgments. Taken together, we demonstrate that human conceptual knowledge is richer than captured in previous norm datasets and show that, with proper validation, LLMs can serve as powerful tools for cognitive science research.
SEVA: Leveraging sketches to evaluate alignment between human and machine visual abstraction
Dec 05, 2023
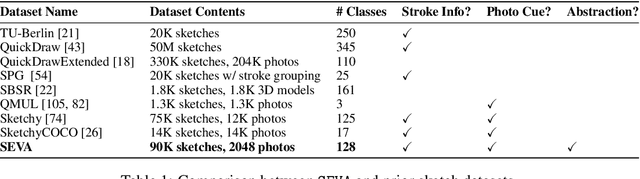
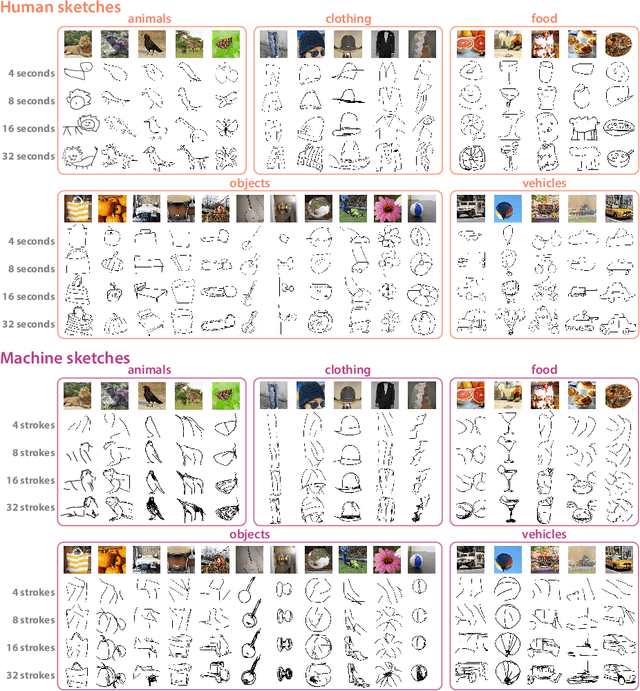
Sketching is a powerful tool for creating abstract images that are sparse but meaningful. Sketch understanding poses fundamental challenges for general-purpose vision algorithms because it requires robustness to the sparsity of sketches relative to natural visual inputs and because it demands tolerance for semantic ambiguity, as sketches can reliably evoke multiple meanings. While current vision algorithms have achieved high performance on a variety of visual tasks, it remains unclear to what extent they understand sketches in a human-like way. Here we introduce SEVA, a new benchmark dataset containing approximately 90K human-generated sketches of 128 object concepts produced under different time constraints, and thus systematically varying in sparsity. We evaluated a suite of state-of-the-art vision algorithms on their ability to correctly identify the target concept depicted in these sketches and to generate responses that are strongly aligned with human response patterns on the same sketch recognition task. We found that vision algorithms that better predicted human sketch recognition performance also better approximated human uncertainty about sketch meaning, but there remains a sizable gap between model and human response patterns. To explore the potential of models that emulate human visual abstraction in generative tasks, we conducted further evaluations of a recently developed sketch generation algorithm (Vinker et al., 2022) capable of generating sketches that vary in sparsity. We hope that public release of this dataset and evaluation protocol will catalyze progress towards algorithms with enhanced capacities for human-like visual abstraction.
Semantic Feature Verification in FLAN-T5
Apr 12, 2023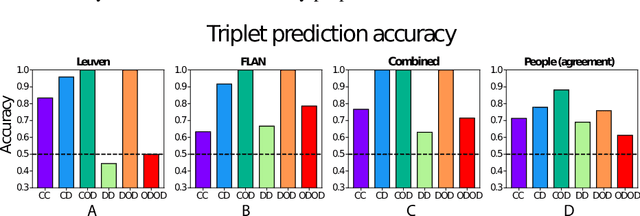
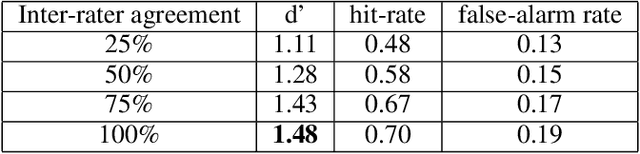

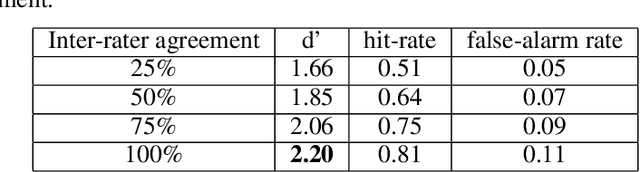
This study evaluates the potential of a large language model for aiding in generation of semantic feature norms - a critical tool for evaluating conceptual structure in cognitive science. Building from an existing human-generated dataset, we show that machine-verified norms capture aspects of conceptual structure beyond what is expressed in human norms alone, and better explain human judgments of semantic similarity amongst items that are distally related. The results suggest that LLMs can greatly enhance traditional methods of semantic feature norm verification, with implications for our understanding of conceptual representation in humans and machines.
Human-machine cooperation for semantic feature listing
Apr 11, 2023


Semantic feature norms, lists of features that concepts do and do not possess, have played a central role in characterizing human conceptual knowledge, but require extensive human labor. Large language models (LLMs) offer a novel avenue for the automatic generation of such feature lists, but are prone to significant error. Here, we present a new method for combining a learned model of human lexical-semantics from limited data with LLM-generated data to efficiently generate high-quality feature norms.
Behavioral estimates of conceptual structure are robust across tasks in humans but not large language models
Apr 05, 2023



Neural network models of language have long been used as a tool for developing hypotheses about conceptual representation in the mind and brain. For many years, such use involved extracting vector-space representations of words and using distances among these to predict or understand human behavior in various semantic tasks. In contemporary language AIs, however, it is possible to interrogate the latent structure of conceptual representations using methods nearly identical to those commonly used with human participants. The current work uses two common techniques borrowed from cognitive psychology to estimate and compare lexical-semantic structure in both humans and a well-known AI, the DaVinci variant of GPT-3. In humans, we show that conceptual structure is robust to differences in culture, language, and method of estimation. Structures estimated from AI behavior, while individually fairly consistent with those estimated from human behavior, depend much more upon the particular task used to generate behavior responses--responses generated by the very same model in the two tasks yield estimates of conceptual structure that cohere less with one another than do human structure estimates. The results suggest one important way that knowledge inhering in contemporary AIs can differ from human cognition.