 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through Clutter: Structured 3D Scene Reconstruction via Iterative Object Removal
Feb 03, 2026We present SeeingThroughClutter, a method for reconstructing structured 3D representations from single images by segmenting and modeling objects individually. Prior approaches rely on intermediate tasks such as semantic segmentation and depth estimation, which often underperform in complex scenes, particularly in the presence of occlusion and clutter. We address this by introducing an iterative object removal and reconstruction pipeline that decomposes complex scenes into a sequence of simpler subtasks. Using VLMs as orchestrators, foreground objects are removed one at a time via detection, segmentation, object removal, and 3D fitting. We show that removing objects allows for cleaner segmentations of subsequent objects, even in highly occluded scenes. Our method requires no task-specific training and benefits directly from ongoing advances in foundation models. We demonstrate stateof-the-art robustness on 3D-Front and ADE20K datasets. Project Page: https://rioak.github.io/seeingthroughclutter/
SEVA: Leveraging sketches to evaluate alignment between human and machine visual abstraction
Dec 05, 2023
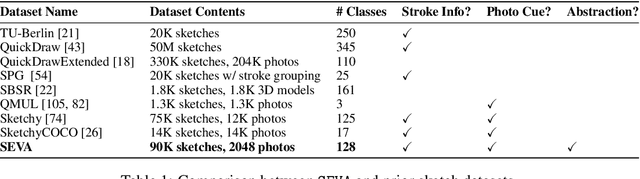
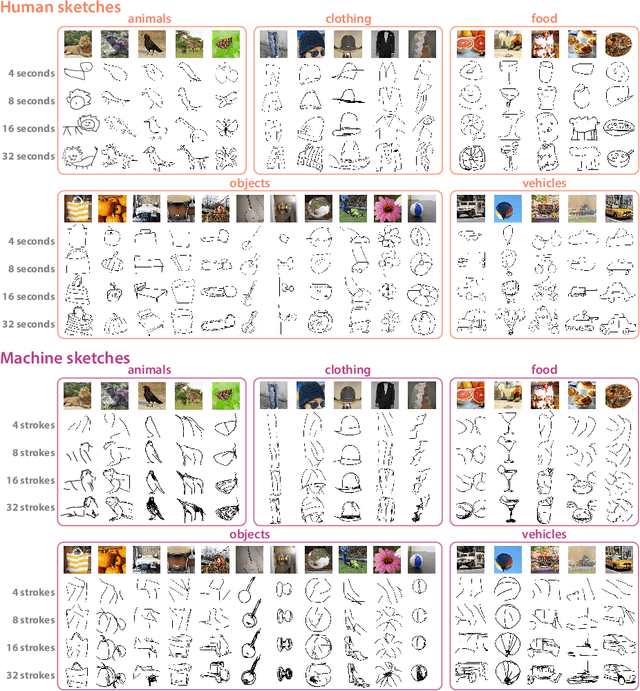
Sketching is a powerful tool for creating abstract images that are sparse but meaningful. Sketch understanding poses fundamental challenges for general-purpose vision algorithms because it requires robustness to the sparsity of sketches relative to natural visual inputs and because it demands tolerance for semantic ambiguity, as sketches can reliably evoke multiple meanings. While current vision algorithms have achieved high performance on a variety of visual tasks, it remains unclear to what extent they understand sketches in a human-like way. Here we introduce SEVA, a new benchmark dataset containing approximately 90K human-generated sketches of 128 object concepts produced under different time constraints, and thus systematically varying in sparsity. We evaluated a suite of state-of-the-art vision algorithms on their ability to correctly identify the target concept depicted in these sketches and to generate responses that are strongly aligned with human response patterns on the same sketch recognition task. We found that vision algorithms that better predicted human sketch recognition performance also better approximated human uncertainty about sketch meaning, but there remains a sizable gap between model and human response patterns. To explore the potential of models that emulate human visual abstraction in generative tasks, we conducted further evaluations of a recently developed sketch generation algorithm (Vinker et al., 2022) capable of generating sketches that vary in sparsity. We hope that public release of this dataset and evaluation protocol will catalyze progress towards algorithms with enhanced capacities for human-like visual abstraction.