 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Through Clutter: Structured 3D Scene Reconstruction via Iterative Object Removal
Feb 03, 2026We present SeeingThroughClutter, a method for reconstructing structured 3D representations from single images by segmenting and modeling objects individually. Prior approaches rely on intermediate tasks such as semantic segmentation and depth estimation, which often underperform in complex scenes, particularly in the presence of occlusion and clutter. We address this by introducing an iterative object removal and reconstruction pipeline that decomposes complex scenes into a sequence of simpler subtasks. Using VLMs as orchestrators, foreground objects are removed one at a time via detection, segmentation, object removal, and 3D fitting. We show that removing objects allows for cleaner segmentations of subsequent objects, even in highly occluded scenes. Our method requires no task-specific training and benefits directly from ongoing advances in foundation models. We demonstrate stateof-the-art robustness on 3D-Front and ADE20K datasets. Project Page: https://rioak.github.io/seeingthroughclutter/
Residual Primitive Fitting of 3D Shapes with SuperFrusta
Dec 09, 2025We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.
PoissonNet: A Local-Global Approach for Learning on Surfaces
Oct 15, 2025Many network architectures exist for learning on meshes, yet their constructions entail delicate trade-offs between difficulty learning high-frequency features, insufficient receptive field, sensitivity to discretization, and inefficient computational overhead. Drawing from classic local-global approaches in mesh processing, we introduce PoissonNet, a novel neural architecture that overcomes all of these deficiencies by formulating a local-global learning scheme, which uses Poisson's equation as the primary mechanism for feature propagation. Our core network block is simple; we apply learned local feature transformations in the gradient domain of the mesh, then solve a Poisson system to propagate scalar feature updates across the surface globally. Our local-global learning framework preserves the features's full frequency spectrum and provides a truly global receptive field, while remaining agnostic to mesh triangulation. Our construction is efficient, requiring far less compute overhead than comparable methods, which enables scalability -- both in the size of our datasets, and the size of individual training samples. These qualities are validated on various experiments where, compared to previous intrinsic architectures, we attain state-of-the-art performance on semantic segmentation and parameterizing highly-detailed animated surfaces. Finally, as a central application of PoissonNet, we show its ability to learn deformations, significantly outperforming state-of-the-art architectures that learn on surfaces.
Reusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets
Aug 28, 2025Text-to-image diffusion models enable high-quality image generation but are computationally expensive. While prior work optimizes per-inference efficiency, we explore an orthogonal approach: reducing redundancy across correlated prompts. Our method leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared structures among similar prompts. We propose a training-free approach that clusters prompts based on semantic similarity and shares computation in early diffusion steps. Experiments show that for models trained conditioned on image embeddings, our approach significantly reduces compute cost while improving image quality. By leveraging UnClip's text-to-image prior, we enhance diffusion step allocation for greater efficiency. Our method seamlessly integrates with existing pipelines, scales with prompt sets, and reduces the environmental and financial burden of large-scale text-to-image generation. Project page: https://ddecatur.github.io/hierarchical-diffusion/
Splat and Replace: 3D Reconstruction with Repetitive Elements
Jun 06, 2025We leverage repetitive elements in 3D scenes to improve novel view synthesis. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly improved novel view synthesis but renderings of unseen and occluded parts remain low-quality if the training views are not exhaustive enough. Our key observation is that our environment is often full of repetitive elements. We propose to leverage those repetitions to improve the reconstruction of low-quality parts of the scene due to poor coverage and occlusions. We propose a method that segments each repeated instance in a 3DGS reconstruction, registers them together, and allows information to be shared among instances. Our method improves the geometry while also accounting for appearance variations across instances. We demonstrate our method on a variety of synthetic and real scenes with typical repetitive elements, leading to a substantial improvement in the quality of novel view synthesis.
Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy
Dec 17, 2024Pattern images are everywhere in the digital and physical worlds, and tools to edit them are valuable. But editing pattern images is tricky: desired edits are often programmatic: structure-aware edits that alter the underlying program which generates the pattern. One could attempt to infer this underlying program, but current methods for doing so struggle with complex images and produce unorganized programs that make editing tedious. In this work, we introduce a novel approach to perform programmatic edits on pattern images. By using a pattern analogy -- a pair of simple patterns to demonstrate the intended edit -- and a learning-based generative model to execute these edits, our method allows users to intuitively edit patterns. To enable this paradigm, we introduce SplitWeave, a domain-specific language that, combined with a framework for sampling synthetic pattern analogies, enables the creation of a large, high-quality synthetic training dataset. We also present TriFuser, a Latent Diffusion Model (LDM) designed to overcome critical issues that arise when naively deploying LDMs to this task. Extensive experiments on real-world, artist-sourced patterns reveals that our method faithfully performs the demonstrated edit while also generalizing to related pattern styles beyond its training distribution.
Instant3dit: Multiview Inpainting for Fast Editing of 3D Objects
Nov 30, 2024We propose a generative technique to edit 3D shapes, represented as meshes, NeRFs, or Gaussian Splats, in approximately 3 seconds, without the need for running an SDS type of optimization. Our key insight is to cast 3D editing as a multiview image inpainting problem, as this representation is generic and can be mapped back to any 3D representation using the bank of available Large Reconstruction Models. We explore different fine-tuning strategies to obtain both multiview generation and inpainting capabilities within the same diffusion model. In particular, the design of the inpainting mask is an important factor of training an inpainting model, and we propose several masking strategies to mimic the types of edits a user would perform on a 3D shape. Our approach takes 3D generative editing from hours to seconds and produces higher-quality results compared to previous works.
SAMa: Material-aware 3D Selection and Segmentation
Nov 28, 2024
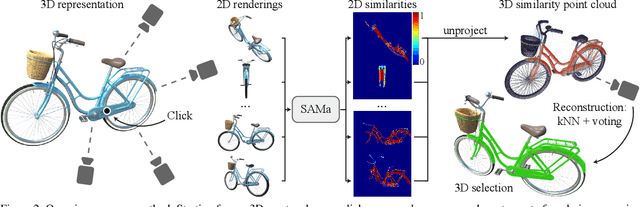
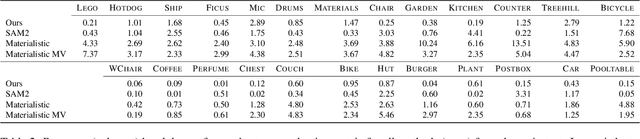
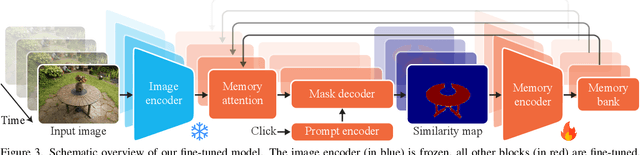
Decomposing 3D assets into material parts is a common task for artists and creators, yet remains a highly manual process. In this work, we introduce Select Any Material (SAMa), a material selection approach for various 3D representations. Building on the recently introduced SAM2 video selection model, we extend its capabilities to the material domain. We leverage the model's cross-view consistency to create a 3D-consistent intermediate material-similarity representation in the form of a point cloud from a sparse set of views. Nearest-neighbour lookups in this similarity cloud allow us to efficiently reconstruct accurate continuous selection masks over objects' surfaces that can be inspected from any view. Our method is multiview-consistent by design, alleviating the need for contrastive learning or feature-field pre-processing, and performs optimization-free selection in seconds. Our approach works on arbitrary 3D representations and outperforms several strong baselines in terms of selection accuracy and multiview consistency. It enables several compelling applications, such as replacing the diffuse-textured materials on a text-to-3D output, or selecting and editing materials on NeRFs and 3D-Gaussians.
MeshUp: Multi-Target Mesh Deformation via Blended Score Distillation
Aug 27, 2024We propose MeshUp, a technique that deforms a 3D mesh towards multiple target concepts, and intuitively controls the region where each concept is expressed. Conveniently, the concepts can be defined as either text queries, e.g., "a dog" and "a turtle," or inspirational images, and the local regions can be selected as any number of vertices on the mesh. We can effectively control the influence of the concepts and mix them together using a novel score distillation approach, referred to as the Blended Score Distillation (BSD). BSD operates on each attention layer of the denoising U-Net of a diffusion model as it extracts and injects the per-objective activations into a unified denoising pipeline from which the deformation gradients are calculated. To localize the expression of these activations, we create a probabilistic Region of Interest (ROI) map on the surface of the mesh, and turn it into 3D-consistent masks that we use to control the expression of these activations. We demonstrate the effectiveness of BSD empirically and show that it can deform various meshes towards multiple objectives.
TutteNet: Injective 3D Deformations by Composition of 2D Mesh Deformations
Jun 17, 2024



This work proposes a novel representation of injective deformations of 3D space, which overcomes existing limitations of injective methods: inaccuracy, lack of robustness, and incompatibility with general learning and optimization frameworks. The core idea is to reduce the problem to a deep composition of multiple 2D mesh-based piecewise-linear maps. Namely, we build differentiable layers that produce mesh deformations through Tutte's embedding (guaranteed to be injective in 2D), and compose these layers over different planes to create complex 3D injective deformations of the 3D volume. We show our method provides the ability to efficiently and accurately optimize and learn complex deformations, outperforming other injective approaches. As a main application, we produce complex and artifact-free NeRF and SDF deformations.