 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Both Ways Before You Cross: Lifting Cross Fields From 2D Visual Priors
May 25, 2026We present CrossLift, a technique for computing cross fields on meshes guided by visual features in images. We leverage powerful text-to-image priors that are capable of synthesizing images of feature-aligned quad meshes in 2D. We extract this signal as explicit per-pixel directions in the 2D images, which we then back-project to the mesh surface. We aggregate these candidate surface directions by performing two smooth interpolations on the mesh surface (first within each view and second across multiple views). We propose custom confidence-based weights for the candidate directions in each interpolation that allow us to resolve conflicts between candidates on the same face and smoothly interpolate our field to occluded faces. Our method is modular and can be used with many different 2D visual priors. We show additional applications to texture-aligned quad meshing as well as interactive cross-field design using coarse, user-drawn lines as signal. We demonstrate the effectiveness of CrossLift on a diverse set of both organic and mechanical shapes and produce quad meshes that exhibit superior semantic alignment as compared to existing methods. Project page at: https://crosslift.github.io/
Best Segmentation Buddies for Image-Shape Correspondence
May 18, 2026Finding correspondences is a fundamental and extensively researched problem in computer vision and graphics. In this work, we examine the underexplored task of estimating segmentation-to-segmentation correspondence between images in the wild and untextured 3D shapes. This task is highly challenging due to substantial differences in appearance, geometry, and viewpoint. Our approach bridges the cross-modality gap by linking pixels in the image segment to vertices in the corresponding semantic part of the 3D shape. To achieve this, we first distill deep visual features from a 2D vision model onto the 3D shape surface, allowing for the computation of feature similarity between image pixels and shape vertices. Then, we identify Best Segmentation Buddies, vertices whose most similar image pixel lies within the image segmentation region, enabling the reliable discovery of vertices in semantically corresponding shape parts. Finally, we leverage distilled 3D features from the 2D image segmentation model to segment the shape directly in 3D, bootstrapping the correspondence process. We demonstrate the generality and robustness of our approach across a wide range of image-shape pairs, showcasing accurate and semantically meaningful correspondences. Our project page is at https://threedle.github.io/bsb/.
MeshOn: Intersection-Free Mesh-to-Mesh Composition
Apr 09, 2026We propose MeshOn, a method that finds physically and semantically realistic compositions of two input meshes. Given an accessory, a base mesh with a user-defined target region, and optional text strings for both meshes, MeshOn uses a multi-step optimization framework to realistically fit the meshes onto each other while preventing intersections. We initialize the shapes' rigid configuration via a structured alignment scheme using Vision-to-Language Models, which we then optimize using a combination of attractive geometric losses, and a physics-inspired barrier loss that prevents surface intersections. We then obtain a final deformation of the object, assisted by a diffusion prior. Our method successfully fits accessories of various materials over a breadth of target regions, and is designed to fit directly into existing digital artist workflows. We demonstrate the robustness and accuracy of our pipeline by comparing it with generative approaches and traditional registration algorithms.
Deep Feature Deformation Weights
Jan 18, 2026Handle-based mesh deformation has been a long-standing paradigm in computer graphics, enabling intuitive shape edits from sparse controls. Classic techniques offer precise and rapid deformation control. However, they solve an optimization problem with constraints defined by control handle placement, requiring a user to know apriori the ideal distribution of handles on the shape to accomplish the desired edit. The mapping from handle set to deformation behavior is often unintuitive and, importantly, non-semantic. Modern data-driven methods, on the other hand, leverage a data prior to obtain semantic edits, but are slow and imprecise. We propose a technique that fuses the semantic prior of data with the precise control and speed of traditional frameworks. Our approach is surprisingly simple yet effective: deep feature proximity makes for smooth and semantic deformation weights, with no need for additional regularization. The weights can be computed in real-time for any surface point, whereas prior methods require optimization for new handles. Moreover, the semantic prior from deep features enables co-deformation of semantic parts. We introduce an improved feature distillation pipeline, barycentric feature distillation, which efficiently uses the visual signal from shape renders to minimize distillation cost. This allows our weights to be computed for high resolution meshes in under a minute, in contrast to potentially hours for both classical and neural methods. We preserve and extend properties of classical methods through feature space constraints and locality weighting. Our field representation allows for automatic detection of semantic symmetries, which we use to produce symmetry-preserving deformations. We show a proof-of-concept application which can produce deformations for meshes up to 1 million faces in real-time on a consumer-grade machine.
Reusing Computation in Text-to-Image Diffusion for Efficient Generation of Image Sets
Aug 28, 2025Text-to-image diffusion models enable high-quality image generation but are computationally expensive. While prior work optimizes per-inference efficiency, we explore an orthogonal approach: reducing redundancy across correlated prompts. Our method leverages the coarse-to-fine nature of diffusion models, where early denoising steps capture shared structures among similar prompts. We propose a training-free approach that clusters prompts based on semantic similarity and shares computation in early diffusion steps. Experiments show that for models trained conditioned on image embeddings, our approach significantly reduces compute cost while improving image quality. By leveraging UnClip's text-to-image prior, we enhance diffusion step allocation for greater efficiency. Our method seamlessly integrates with existing pipelines, scales with prompt sets, and reduces the environmental and financial burden of large-scale text-to-image generation. Project page: https://ddecatur.github.io/hierarchical-diffusion/
LL3M: Large Language 3D Modelers
Aug 11, 2025

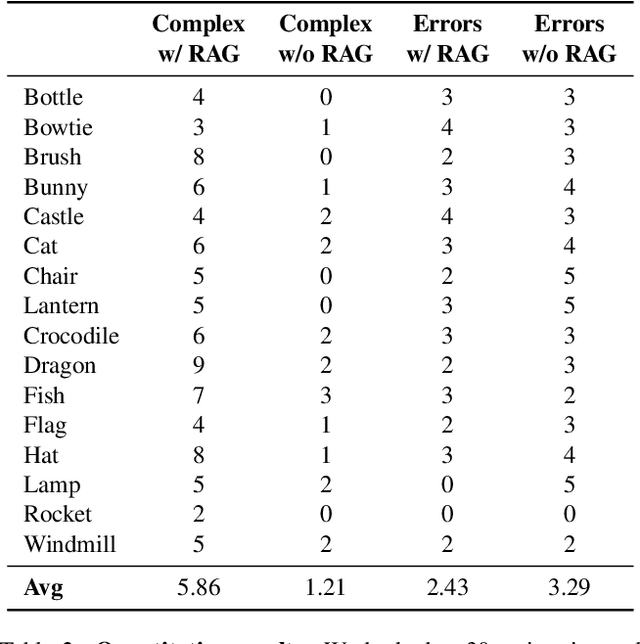

We present LL3M, a multi-agent system that leverages pretrained large language models (LLMs) to generate 3D assets by writing interpretable Python code in Blender. We break away from the typical generative approach that learns from a collection of 3D data. Instead, we reformulate shape generation as a code-writing task, enabling greater modularity, editability, and integration with artist workflows. Given a text prompt, LL3M coordinates a team of specialized LLM agents to plan, retrieve, write, debug, and refine Blender scripts that generate and edit geometry and appearance. The generated code works as a high-level, interpretable, human-readable, well-documented representation of scenes and objects, making full use of sophisticated Blender constructs (e.g. B-meshes, geometry modifiers, shader nodes) for diverse, unconstrained shapes, materials, and scenes. This code presents many avenues for further agent and human editing and experimentation via code tweaks or procedural parameters. This medium naturally enables a co-creative loop in our system: agents can automatically self-critique using code and visuals, while iterative user instructions provide an intuitive way to refine assets. A shared code context across agents enables awareness of previous attempts, and a retrieval-augmented generation knowledge base built from Blender API documentation, BlenderRAG, equips agents with examples, types, and functions empowering advanced modeling operations and code correctness. We demonstrate the effectiveness of LL3M across diverse shape categories, style and material edits, and user-driven refinements. Our experiments showcase the power of code as a generative and interpretable medium for 3D asset creation. Our project page is at https://threedle.github.io/ll3m.
WIR3D: Visually-Informed and Geometry-Aware 3D Shape Abstraction
May 07, 2025

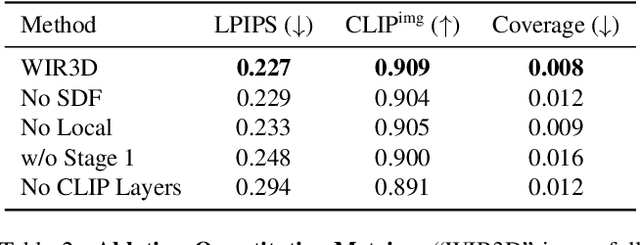
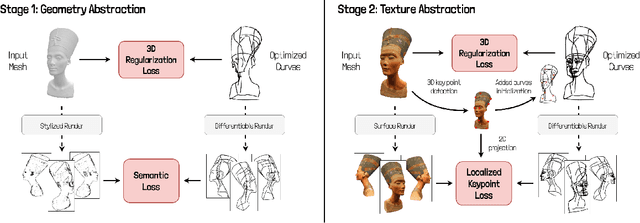
We present WIR3D, a technique for abstracting 3D shapes through a sparse set of visually meaningful curves in 3D. We optimize the parameters of Bezier curves such that they faithfully represent both the geometry and salient visual features (e.g. texture) of the shape from arbitrary viewpoints. We leverage the intermediate activations of a pre-trained foundation model (CLIP) to guide our optimization process. We divide our optimization into two phases: one for capturing the coarse geometry of the shape, and the other for representing fine-grained features. Our second phase supervision is spatially guided by a novel localized keypoint loss. This spatial guidance enables user control over abstracted features. We ensure fidelity to the original surface through a neural SDF loss, which allows the curves to be used as intuitive deformation handles. We successfully apply our method for shape abstraction over a broad dataset of shapes with varying complexity, geometric structure, and texture, and demonstrate downstream applications for feature control and shape deformation.
Geometry in Style: 3D Stylization via Surface Normal Deformation
Mar 29, 2025We present Geometry in Style, a new method for identity-preserving mesh stylization. Existing techniques either adhere to the original shape through overly restrictive deformations such as bump maps or significantly modify the input shape using expressive deformations that may introduce artifacts or alter the identity of the source shape. In contrast, we represent a deformation of a triangle mesh as a target normal vector for each vertex neighborhood. The deformations we recover from target normals are expressive enough to enable detailed stylizations yet restrictive enough to preserve the shape's identity. We achieve such deformations using our novel differentiable As-Rigid-As-Possible (dARAP) layer, a neural-network-ready adaptation of the classical ARAP algorithm which we use to solve for per-vertex rotations and deformed vertices. As a differentiable layer, dARAP is paired with a visual loss from a text-to-image model to drive deformations toward style prompts, altogether giving us Geometry in Style. Our project page is at https://threedle.github.io/geometry-in-style.
MeshUp: Multi-Target Mesh Deformation via Blended Score Distillation
Aug 27, 2024We propose MeshUp, a technique that deforms a 3D mesh towards multiple target concepts, and intuitively controls the region where each concept is expressed. Conveniently, the concepts can be defined as either text queries, e.g., "a dog" and "a turtle," or inspirational images, and the local regions can be selected as any number of vertices on the mesh. We can effectively control the influence of the concepts and mix them together using a novel score distillation approach, referred to as the Blended Score Distillation (BSD). BSD operates on each attention layer of the denoising U-Net of a diffusion model as it extracts and injects the per-objective activations into a unified denoising pipeline from which the deformation gradients are calculated. To localize the expression of these activations, we create a probabilistic Region of Interest (ROI) map on the surface of the mesh, and turn it into 3D-consistent masks that we use to control the expression of these activations. We demonstrate the effectiveness of BSD empirically and show that it can deform various meshes towards multiple objectives.
Generative Lifting of Multiview to 3D from Unknown Pose: Wrapping NeRF inside Diffusion
Jun 11, 2024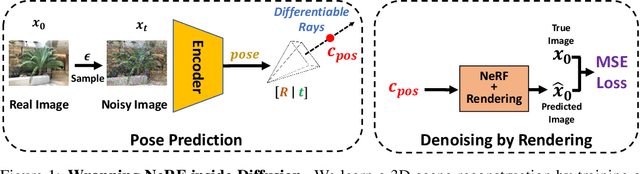
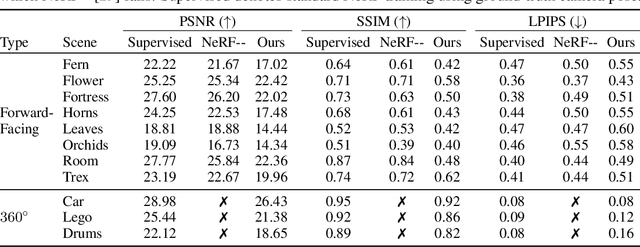
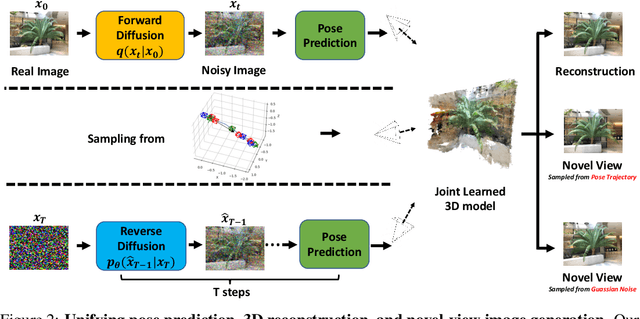
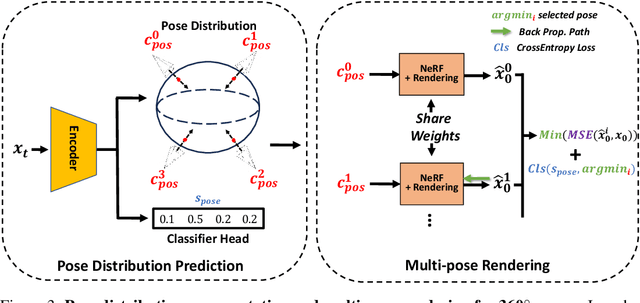
We cast multiview reconstruction from unknown pose as a generative modeling problem. From a collection of unannotated 2D images of a scene, our approach simultaneously learns both a network to predict camera pose from 2D image input, as well as the parameters of a Neural Radiance Field (NeRF) for the 3D scene. To drive learning, we wrap both the pose prediction network and NeRF inside a Denoising Diffusion Probabilistic Model (DDPM) and train the system via the standard denoising objective. Our framework requires the system accomplish the task of denoising an input 2D image by predicting its pose and rendering the NeRF from that pose. Learning to denoise thus forces the system to concurrently learn the underlying 3D NeRF representation and a mapping from images to camera extrinsic parameters. To facilitate the latter, we design a custom network architecture to represent pose as a distribution, granting implicit capacity for discovering view correspondences when trained end-to-end for denoising alone. This technique allows our system to successfully build NeRFs, without pose knowledge, for challenging scenes where competing methods fail. At the conclusion of training, our learned NeRF can be extracted and used as a 3D scene model; our full system can be used to sample novel camera poses and generate novel-view images.