 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSeg: Interactive 3D Segmentation via Interactive Attention
Apr 04, 2024We present iSeg, a new interactive technique for segmenting 3D shapes. Previous works have focused mainly on leveraging pre-trained 2D foundation models for 3D segmentation based on text. However, text may be insufficient for accurately describing fine-grained spatial segmentations. Moreover, achieving a consistent 3D segmentation using a 2D model is challenging since occluded areas of the same semantic region may not be visible together from any 2D view. Thus, we design a segmentation method conditioned on fine user clicks, which operates entirely in 3D. Our system accepts user clicks directly on the shape's surface, indicating the inclusion or exclusion of regions from the desired shape partition. To accommodate various click settings, we propose a novel interactive attention module capable of processing different numbers and types of clicks, enabling the training of a single unified interactive segmentation model. We apply iSeg to a myriad of shapes from different domains, demonstrating its versatility and faithfulness to the user's specifications. Our project page is at https://threedle.github.io/iSeg/.
HyperFields: Towards Zero-Shot Generation of NeRFs from Text
Oct 27, 2023
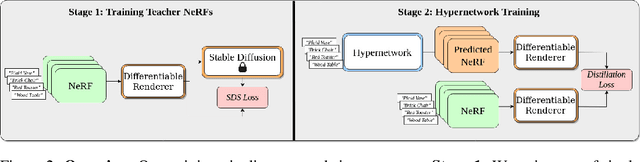

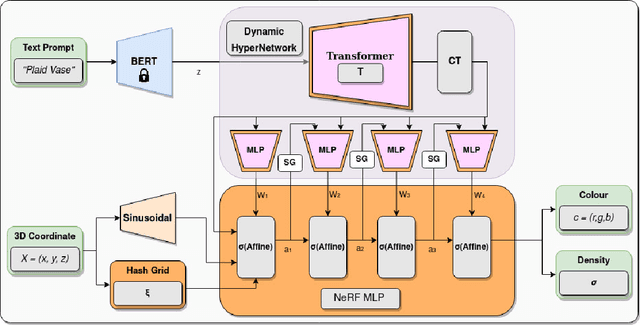
We introduce HyperFields, a method for generating text-conditioned Neural Radiance Fields (NeRFs) with a single forward pass and (optionally) some fine-tuning. Key to our approach are: (i) a dynamic hypernetwork, which learns a smooth mapping from text token embeddings to the space of NeRFs; (ii) NeRF distillation training, which distills scenes encoded in individual NeRFs into one dynamic hypernetwork. These techniques enable a single network to fit over a hundred unique scenes. We further demonstrate that HyperFields learns a more general map between text and NeRFs, and consequently is capable of predicting novel in-distribution and out-of-distribution scenes -- either zero-shot or with a few finetuning steps. Finetuning HyperFields benefits from accelerated convergence thanks to the learned general map, and is capable of synthesizing novel scenes 5 to 10 times faster than existing neural optimization-based methods. Our ablation experiments show that both the dynamic architecture and NeRF distillation are critical to the expressivity of HyperFields.
Domain-independent Dominance of Adaptive Methods
Dec 10, 2019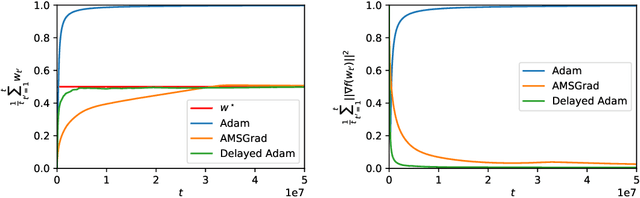
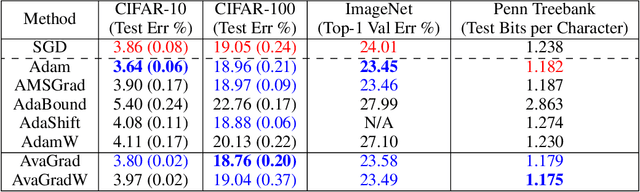
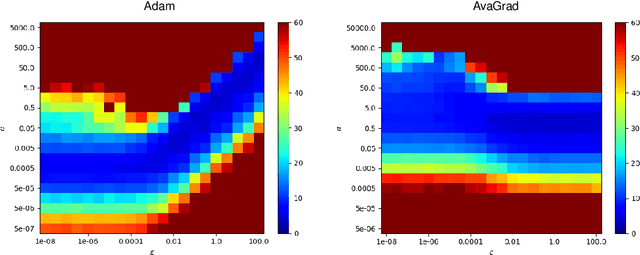
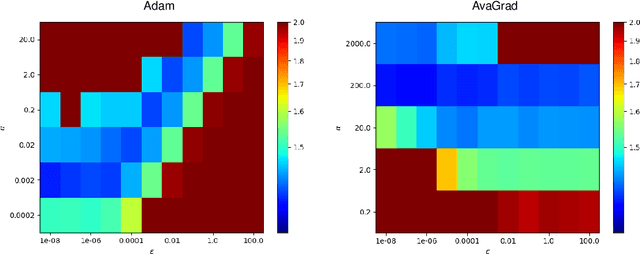
From a simplified analysis of adaptive methods, we derive AvaGrad, a new optimizer which outperforms SGD on vision tasks when its adaptability is properly tuned. We observe that the power of our method is partially explained by a decoupling of learning rate and adaptability, greatly simplifying hyperparameter search. In light of this observation, we demonstrate that, against conventional wisdom, Adam can also outperform SGD on vision tasks, as long as the coupling between its learning rate and adaptability is taken into account. In practice, AvaGrad matches the best results, as measured by generalization accuracy, delivered by any existing optimizer (SGD or adaptive) across image classification (CIFAR, ImageNet) and character-level language modelling (Penn Treebank) tasks. This later observation, alongside of AvaGrad's decoupling of hyperparameters, could make it the preferred optimizer for deep learning, replacing both SGD and Adam.
Scalable K-Medoids via True Error Bound and Familywise Bandits
May 27, 2019
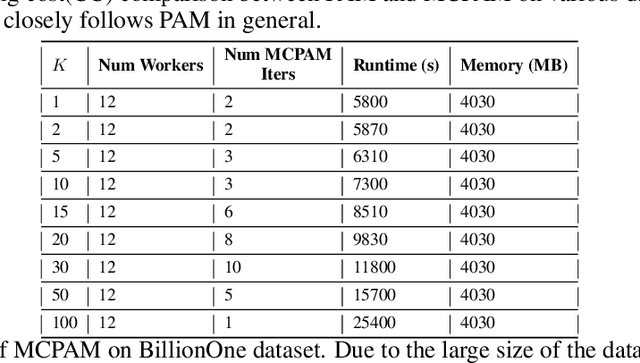
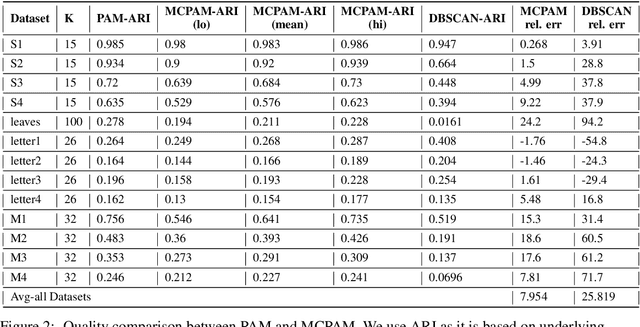
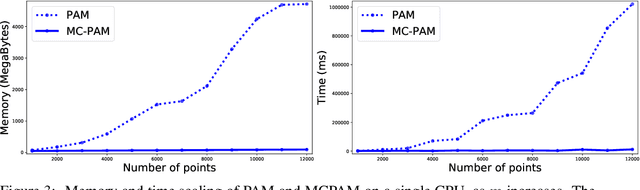
K-Medoids(KM) is a standard clustering method, used extensively on semi-metric data. Error analyses of KM have traditionally used an in-sample notion of error, which can be far from the true error and suffer from generalization error. We formalize the true K-Medoid error based on the underlying data distribution, by decomposing it into fundamental statistical problems of: minimum estimation (ME) and minimum mean estimation (MME). We provide a convergence result for MME and bound the true KM error for iid data. Inspired by this bound, we propose a computationally efficient, distributed KM algorithm namely MCPAM. MCPAM has expected runtime $\mathcal{O}(km)$ and provides massive computational savings for a small tradeoff in accuracy. We verify the quality and scaling properties of MCPAM on various datasets. And achieve the hitherto unachieved feat of calculating the KM of 1 billion points on semi-metric spaces.