 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUCo: An Agentic Framework for Compute and Communication Co-design
Mar 02, 2026Custom CUDA kernel development is essential for maximizing GPU utilization in large-scale distributed LLM training and inference, yet manually writing kernels that jointly leverage both computation and communication remains a labor-intensive and error-prone process. Prior work on kernel optimization has focused almost exclusively on computation, leaving communication kernels largely untouched even though they constitute a significant share of total execution time. We introduce CUCo, a training-free agent-driven workflow that automatically generates high-performance CUDA kernels that jointly orchestrate computation and communication. By co-optimizing these traditionally disjoint components, CUCo unlocks new optimization opportunities unavailable to existing approaches, outperforming state-of-the-art baselines and reducing end-to-end latency by up to $1.57\times$.
SuperGen: An Efficient Ultra-high-resolution Video Generation System with Sketching and Tiling
Aug 25, 2025Diffusion models have recently achieved remarkable success in generative tasks (e.g., image and video generation), and the demand for high-quality content (e.g., 2K/4K videos) is rapidly increasing across various domains. However, generating ultra-high-resolution videos on existing standard-resolution (e.g., 720p) platforms remains challenging due to the excessive re-training requirements and prohibitively high computational and memory costs. To this end, we introduce SuperGen, an efficient tile-based framework for ultra-high-resolution video generation. SuperGen features a novel training-free algorithmic innovation with tiling to successfully support a wide range of resolutions without additional training efforts while significantly reducing both memory footprint and computational complexity. Moreover, SuperGen incorporates a tile-tailored, adaptive, region-aware caching strategy that accelerates video generation by exploiting redundancy across denoising steps and spatial regions. SuperGen also integrates cache-guided, communication-minimized tile parallelism for enhanced throughput and minimized latency. Evaluations demonstrate that SuperGen harvests the maximum performance gains while achieving high output quality across various benchmarks.
Tesserae: Scalable Placement Policies for Deep Learning Workloads
Aug 07, 2025Training deep learning (DL) models has become a dominant workload in data-centers and improving resource utilization is a key goal of DL cluster schedulers. In order to do this, schedulers typically incorporate placement policies that govern where jobs are placed on the cluster. Existing placement policies are either designed as ad-hoc heuristics or incorporated as constraints within a complex optimization problem and thus either suffer from suboptimal performance or poor scalability. Our key insight is that many placement constraints can be formulated as graph matching problems and based on that we design novel placement policies for minimizing job migration overheads and job packing. We integrate these policies into Tesserae and describe how our design leads to a scalable and effective GPU cluster scheduler. Our experimental results show that Tesserae improves average JCT by up to 1.62x and the Makespan by up to 1.15x compared with the existing schedulers.
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024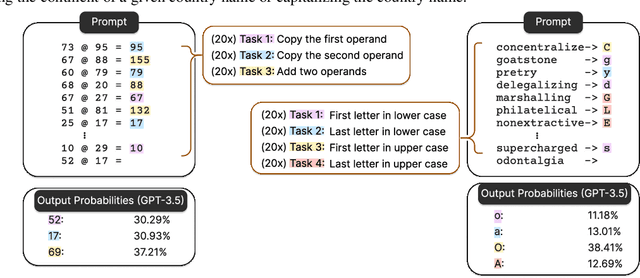

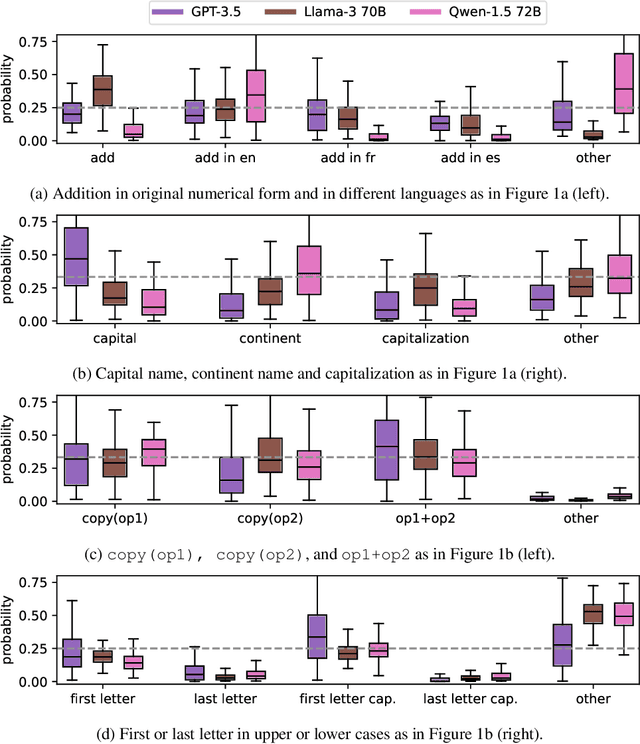
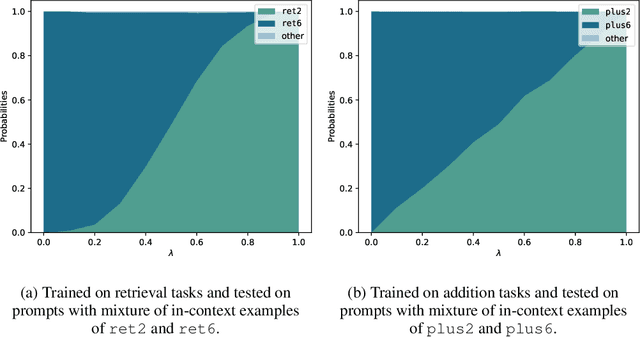
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Apr 29, 2024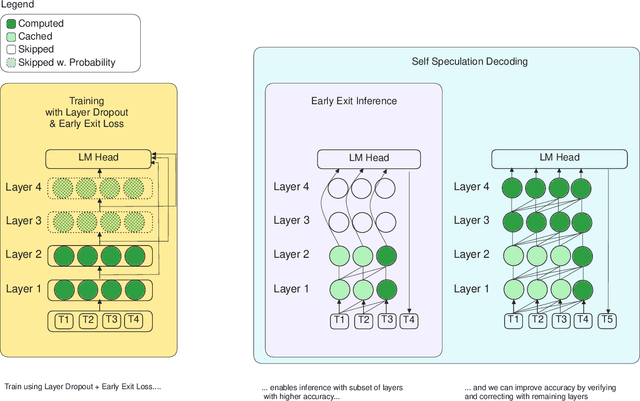
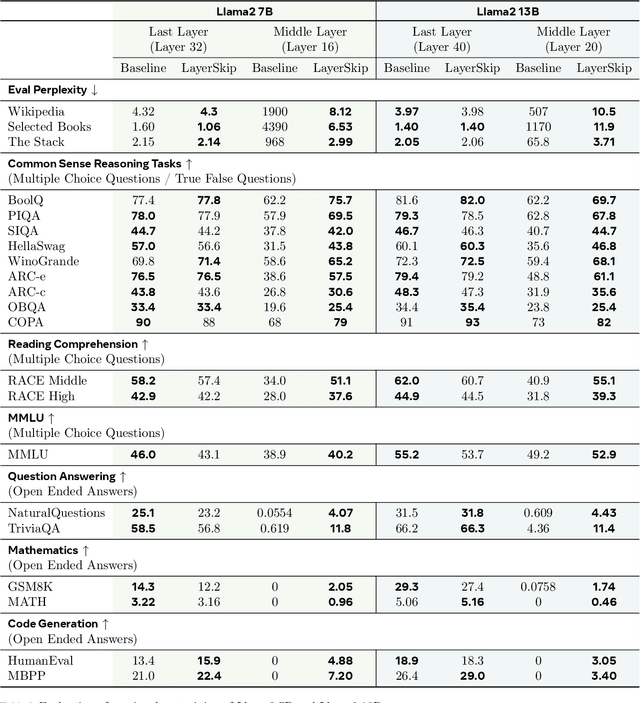
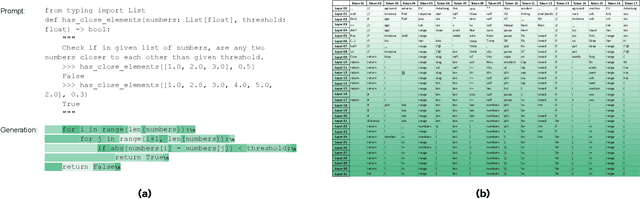
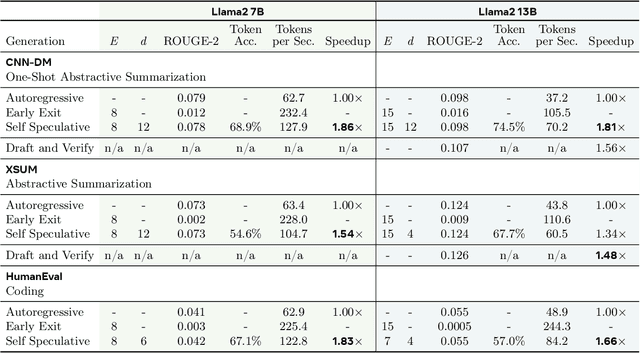
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
CHAI: Clustered Head Attention for Efficient LLM Inference
Mar 12, 2024



Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute. In our experiments, we show that CHAI is able to reduce the memory requirements for storing K,V cache by up to 21.4% and inference time latency by up to 1.73x without any fine-tuning required. CHAI achieves this with a maximum 3.2% deviation in accuracy across 3 different models (i.e. OPT-66B, LLAMA-7B, LLAMA-33B) and 5 different evaluation datasets.
Decoding Speculative Decoding
Feb 02, 2024



Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without modifying its outcome. When performing inference on an LLM, speculative decoding uses a smaller draft model which generates speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. It has been widely suggested to select a draft model that provides a high probability of the generated token being accepted by the LLM to achieve the highest throughput. However, our experiments indicate the contrary with throughput diminishing as the probability of generated tokens to be accepted by the target model increases. To understand this phenomenon, we perform extensive experiments to characterize the different factors that affect speculative decoding and how those factors interact and affect the speedups. Based on our experiments we describe an analytical model which can be used to decide the right draft model for a given workload. Further, using our insights we design a new draft model for LLaMA-65B which can provide 30% higher throughput than existing draft models.
MultiFusionNet: Multilayer Multimodal Fusion of Deep Neural Networks for Chest X-Ray Image Classification
Jan 01, 2024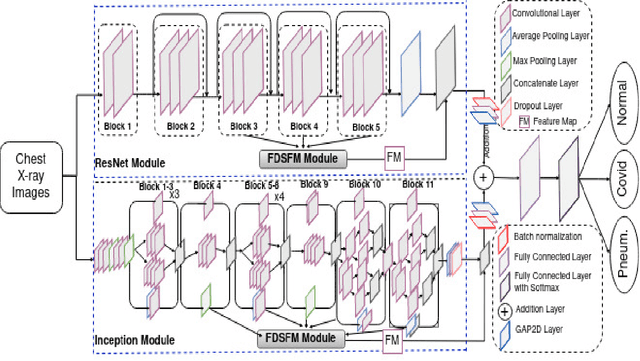
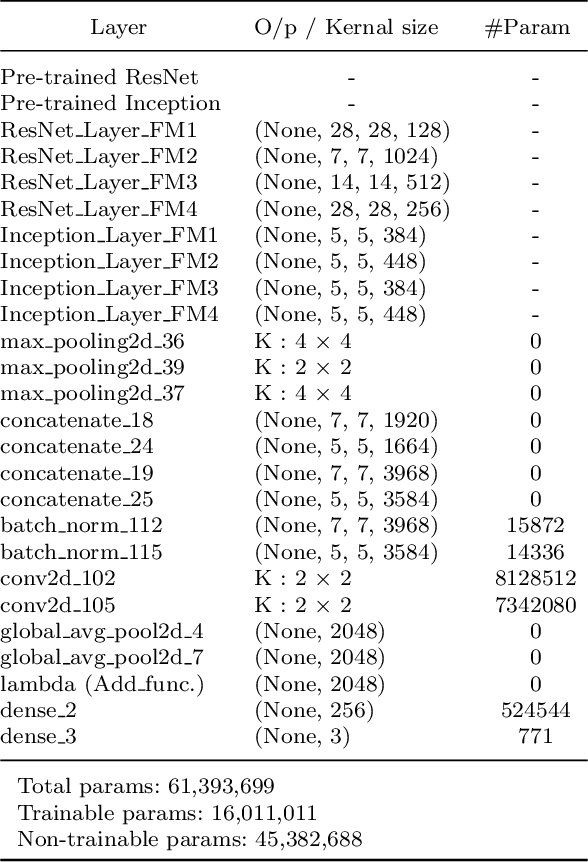
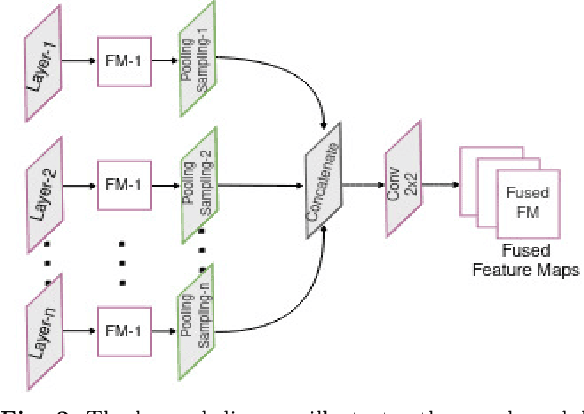
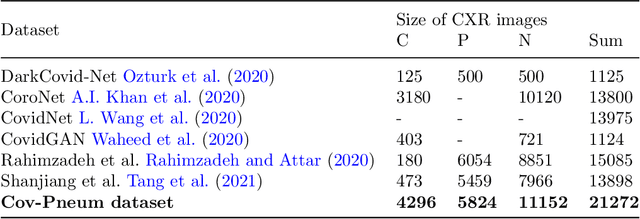
Chest X-ray imaging is a critical diagnostic tool for identifying pulmonary diseases. However, manual interpretation of these images is time-consuming and error-prone. Automated systems utilizing convolutional neural networks (CNNs) have shown promise in improving the accuracy and efficiency of chest X-ray image classification. While previous work has mainly focused on using feature maps from the final convolution layer, there is a need to explore the benefits of leveraging additional layers for improved disease classification. Extracting robust features from limited medical image datasets remains a critical challenge. In this paper, we propose a novel deep learning-based multilayer multimodal fusion model that emphasizes extracting features from different layers and fusing them. Our disease detection model considers the discriminatory information captured by each layer. Furthermore, we propose the fusion of different-sized feature maps (FDSFM) module to effectively merge feature maps from diverse layers. The proposed model achieves a significantly higher accuracy of 97.21% and 99.60% for both three-class and two-class classifications, respectively. The proposed multilayer multimodal fusion model, along with the FDSFM module, holds promise for accurate disease classification and can also be extended to other disease classifications in chest X-ray images.
Cuttlefish: Low-Rank Model Training without All the Tuning
May 05, 2023Recent research has shown that training low-rank neural networks can effectively reduce the total number of trainable parameters without sacrificing predictive accuracy, resulting in end-to-end speedups. However, low-rank model training necessitates adjusting several additional factorization hyperparameters, such as the rank of the factorization at each layer. In this paper, we tackle this challenge by introducing Cuttlefish, an automated low-rank training approach that eliminates the need for tuning factorization hyperparameters. Cuttlefish leverages the observation that after a few epochs of full-rank training, the stable rank (i.e., an approximation of the true rank) of each layer stabilizes at a constant value. Cuttlefish switches from full-rank to low-rank training once the stable ranks of all layers have converged, setting the dimension of each factorization to its corresponding stable rank. Our results show that Cuttlefish generates models up to 5.6 times smaller than full-rank models, and attains up to a 1.2 times faster end-to-end training process while preserving comparable accuracy. Moreover, Cuttlefish outperforms state-of-the-art low-rank model training methods and other prominent baselines. The source code for our implementation can be found at: https://github.com/hwang595/Cuttlefish.
BagPipe: Accelerating Deep Recommendation Model Training
Feb 24, 2022
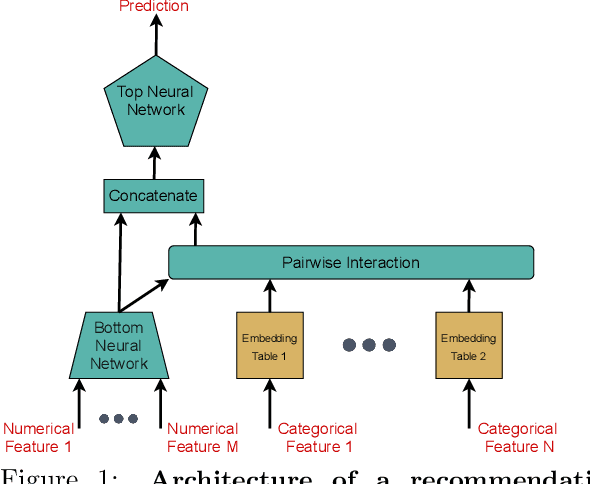
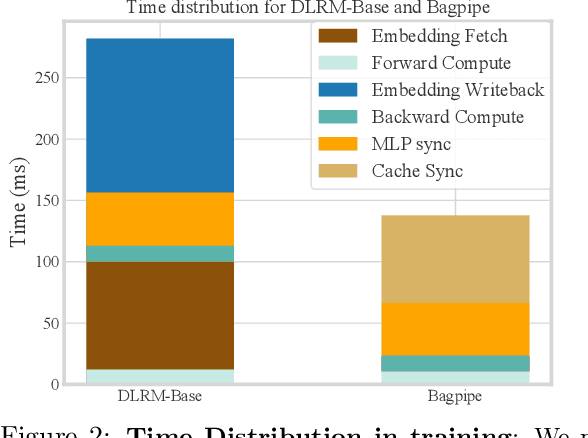
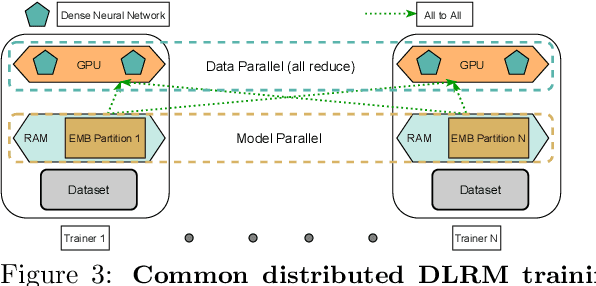
Deep learning based recommendation models (DLRM) are widely used in several business critical applications. Training such recommendation models efficiently is challenging primarily because they consist of billions of embedding-based parameters which are often stored remotely leading to significant overheads from embedding access. By profiling existing DLRM training, we observe that only 8.5% of the iteration time is spent in forward/backward pass while the remaining time is spent on embedding and model synchronization. Our key insight in this paper is that access to embeddings have a specific structure and pattern which can be used to accelerate training. We observe that embedding accesses are heavily skewed, with almost 1% of embeddings represent more than 92% of total accesses. Further, we observe that during training we can lookahead at future batches to determine exactly which embeddings will be needed at what iteration in the future. Based on these insight, we propose Bagpipe, a system for training deep recommendation models that uses caching and prefetching to overlap remote embedding accesses with the computation. We designed an Oracle Cacher, a new system component which uses our lookahead algorithm to generate optimal cache update decisions and provide strong consistency guarantees. Our experiments using three datasets and two models shows that our approach provides a speed up of up to 6.2x compared to state of the art baselines, while providing the same convergence and reproducibility guarantees as synchronous training.