 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Flash Attention Stable?
May 05, 2024



Training large-scale machine learning models poses distinct system challenges, given both the size and complexity of today's workloads. Recently, many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often taking the form of loss spikes. Numeric deviation has emerged as a potential cause of this training instability, although quantifying this is especially challenging given the costly nature of training runs. In this work, we develop a principled approach to understanding the effects of numeric deviation, and construct proxies to put observations into context when downstream effects are difficult to quantify. As a case study, we apply this framework to analyze the widely-adopted Flash Attention optimization. We find that Flash Attention sees roughly an order of magnitude more numeric deviation as compared to Baseline Attention at BF16 when measured during an isolated forward pass. We then use a data-driven analysis based on the Wasserstein Distance to provide upper bounds on how this numeric deviation impacts model weights during training, finding that the numerical deviation present in Flash Attention is 2-5 times less significant than low-precision training.
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Apr 29, 2024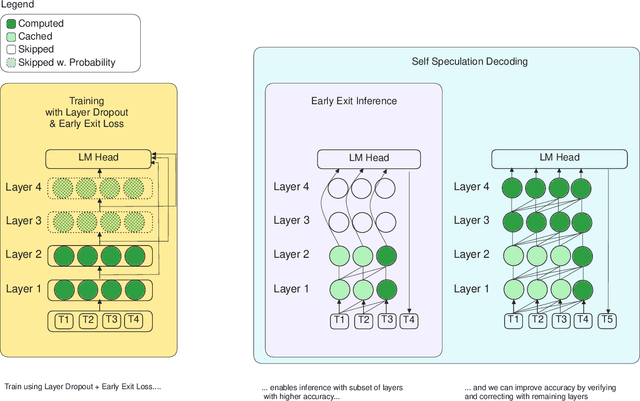
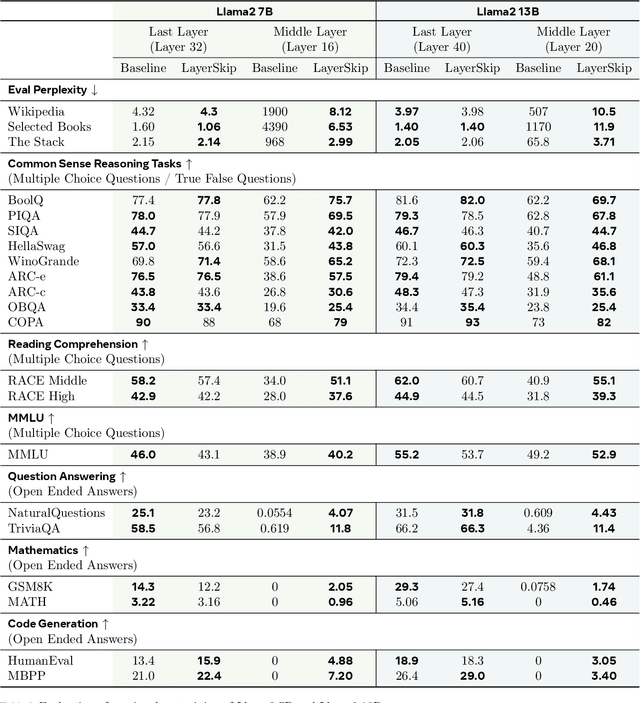
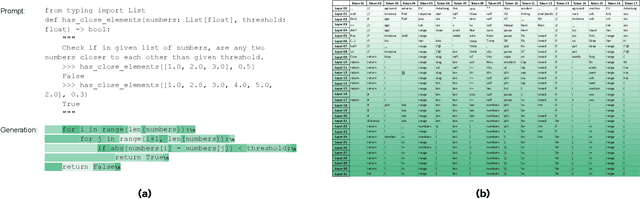
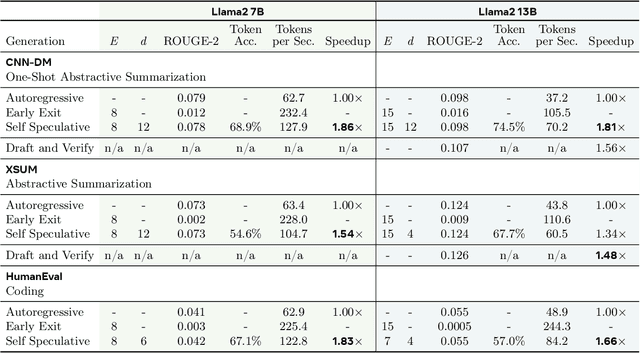
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023



As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
Gradient Descent: The Ultimate Optimizer
Sep 29, 2019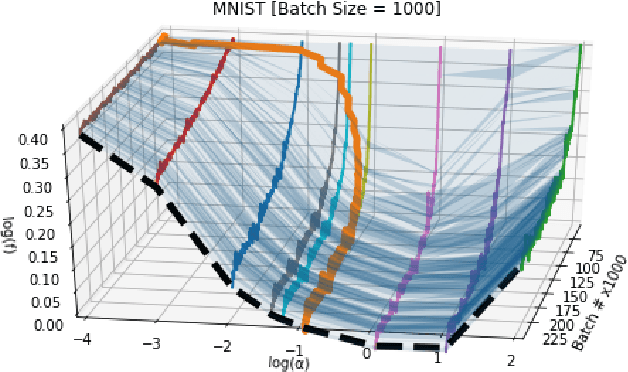
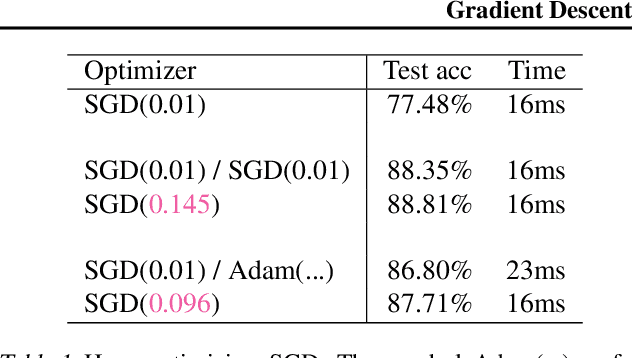
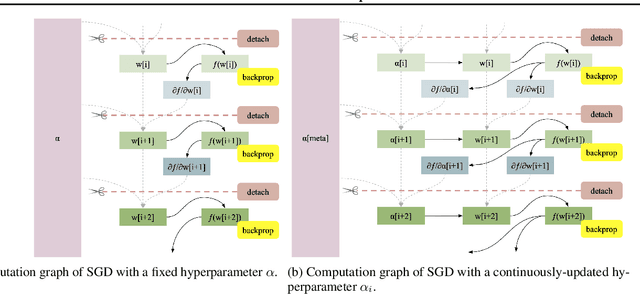
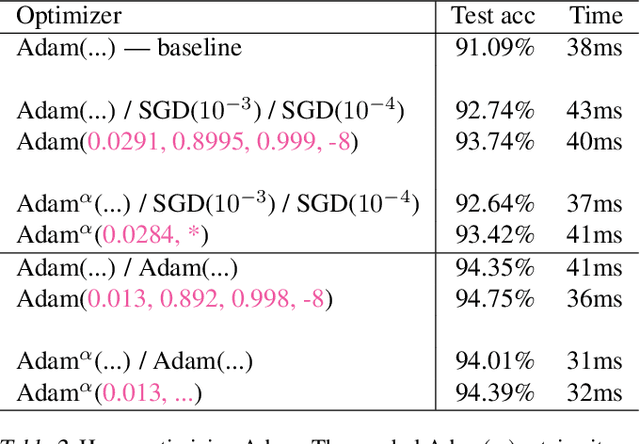
Working with any gradient-based machine learning algorithm involves the tedious task of tuning the optimizer's hyperparameters, such as the learning rate. There exist many techniques for automated hyperparameter optimization, but they typically introduce even more hyperparameters to control the hyperparameter optimization process. We propose to instead learn the hyperparameters themselves by gradient descent, and furthermore to learn the hyper-hyperparameters by gradient descent as well, and so on ad infinitum. As these towers of gradient-based optimizers grow, they become significantly less sensitive to the choice of top-level hyperparameters, hence decreasing the burden on the user to search for optimal values.