 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeschers: Geometry Processing of Impossible Objects
May 14, 2026Impossible objects, geometric constructions that humans can perceive but that cannot exist in real life, have been a topic of intrigue in visual arts, perception, and graphics, yet no satisfying computer representation of such objects exists. Previous work embeds impossible objects in 3D, cutting them or twisting/bending them in the depth axis. Cutting an impossible object changes its local geometry at the cut, which can hamper downstream graphics applications, such as smoothing, while bending makes it difficult to relight the object. Both of these can invalidate geometry operations, such as distance computation. As an alternative, we introduce Meschers, meshes capable of representing impossible constructions akin to those found in M.C. Escher's woodcuts. Our representation has a theoretical foundation in discrete exterior calculus and supports the use-cases above, as we demonstrate in a number of example applications. Moreover, because we can do discrete geometry processing on our representation, we can inverse-render impossible objects. We also compare our representation to cut and bend representations of impossible objects.
Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians
Feb 22, 2026"AI psychosis" or "delusional spiraling" is an emerging phenomenon where AI chatbot users find themselves dangerously confident in outlandish beliefs after extended chatbot conversations. This phenomenon is typically attributed to AI chatbots' well-documented bias towards validating users' claims, a property often called "sycophancy." In this paper, we probe the causal link between AI sycophancy and AI-induced psychosis through modeling and simulation. We propose a simple Bayesian model of a user conversing with a chatbot, and formalize notions of sycophancy and delusional spiraling in that model. We then show that in this model, even an idealized Bayes-rational user is vulnerable to delusional spiraling, and that sycophancy plays a causal role. Furthermore, this effect persists in the face of two candidate mitigations: preventing chatbots from hallucinating false claims, and informing users of the possibility of model sycophancy. We conclude by discussing the implications of these results for model developers and policymakers concerned with mitigating the problem of delusional spiraling.
Building Machines that Learn and Think with People
Jul 22, 2024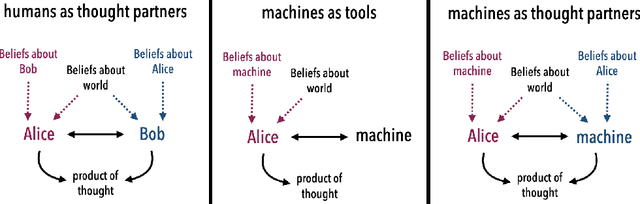
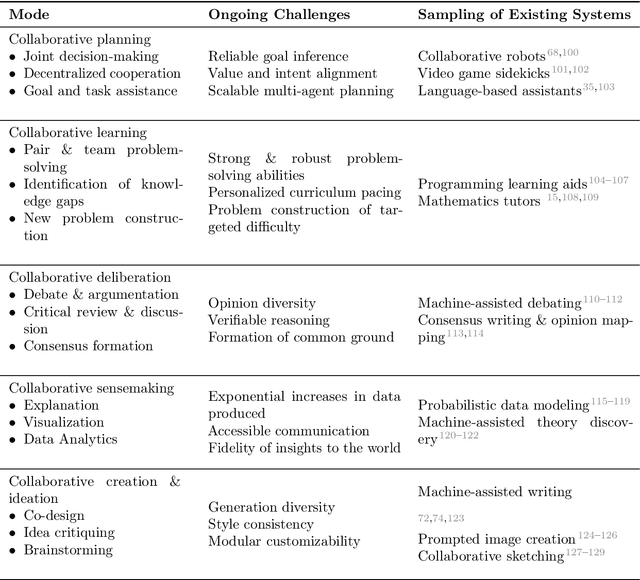
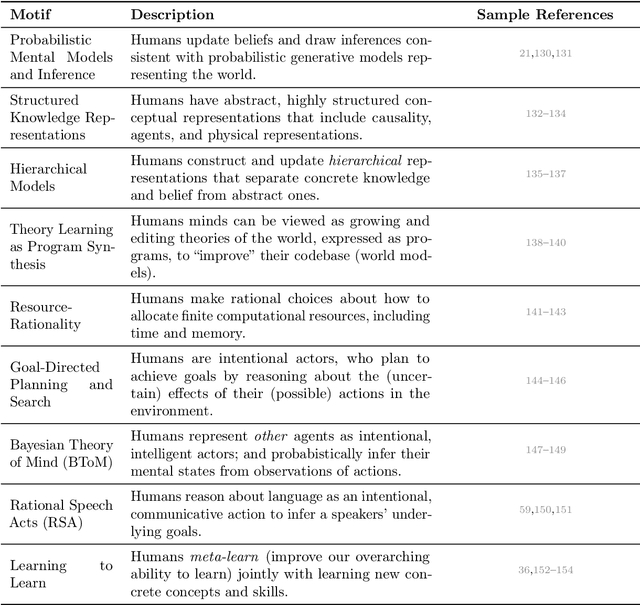
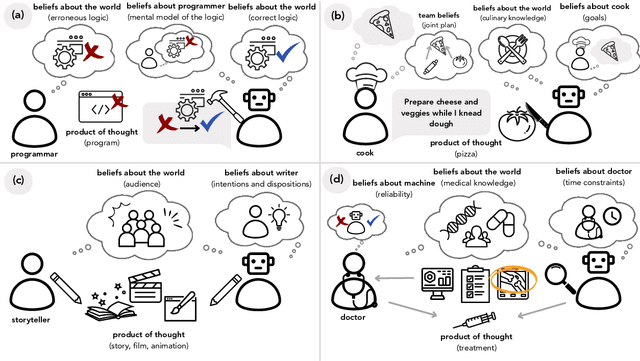
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
WatChat: Explaining perplexing programs by debugging mental models
Mar 08, 2024Often, a good explanation for a program's unexpected behavior is a bug in the programmer's code. But sometimes, an even better explanation is a bug in the programmer's mental model of the language they are using. Instead of merely debugging our current code ("giving the programmer a fish"), what if our tools could directly debug our mental models ("teaching the programmer to fish")? In this paper, we apply ideas from computational cognitive science to do exactly that. Given a perplexing program, we use program synthesis techniques to automatically infer potential misconceptions that might cause the user to be surprised by the program's behavior. By analyzing these misconceptions, we provide succinct, useful explanations of the program's behavior. Our methods can even be inverted to synthesize pedagogical example programs for diagnosing and correcting misconceptions in students.
How to guess a gradient
Dec 07, 2023How much can you say about the gradient of a neural network without computing a loss or knowing the label? This may sound like a strange question: surely the answer is "very little." However, in this paper, we show that gradients are more structured than previously thought. Gradients lie in a predictable low-dimensional subspace which depends on the network architecture and incoming features. Exploiting this structure can significantly improve gradient-free optimization schemes based on directional derivatives, which have struggled to scale beyond small networks trained on toy datasets. We study how to narrow the gap in optimization performance between methods that calculate exact gradients and those that use directional derivatives. Furthermore, we highlight new challenges in overcoming the large gap between optimizing with exact gradients and guessing the gradients.
Differentiating Metropolis-Hastings to Optimize Intractable Densities
Jun 30, 2023We develop an algorithm for automatic differentiation of Metropolis-Hastings samplers, allowing us to differentiate through probabilistic inference, even if the model has discrete components within it. Our approach fuses recent advances in stochastic automatic differentiation with traditional Markov chain coupling schemes, providing an unbiased and low-variance gradient estimator. This allows us to apply gradient-based optimization to objectives expressed as expectations over intractable target densities. We demonstrate our approach by finding an ambiguous observation in a Gaussian mixture model and by maximizing the specific heat in an Ising model.
Acting as Inverse Inverse Planning
May 26, 2023Great storytellers know how to take us on a journey. They direct characters to act -- not necessarily in the most rational way -- but rather in a way that leads to interesting situations, and ultimately creates an impactful experience for audience members looking on. If audience experience is what matters most, then can we help artists and animators *directly* craft such experiences, independent of the concrete character actions needed to evoke those experiences? In this paper, we offer a novel computational framework for such tools. Our key idea is to optimize animations with respect to *simulated* audience members' experiences. To simulate the audience, we borrow an established principle from cognitive science: that human social intuition can be modeled as "inverse planning," the task of inferring an agent's (hidden) goals from its (observed) actions. Building on this model, we treat storytelling as "*inverse* inverse planning," the task of choosing actions to manipulate an inverse planner's inferences. Our framework is grounded in literary theory, naturally capturing many storytelling elements from first principles. We give a series of examples to demonstrate this, with supporting evidence from human subject studies.
Inferring the Future by Imagining the Past
May 26, 2023A single panel of a comic book can say a lot: it shows not only where characters currently are, but also where they came from, what their motivations are, and what might happen next. More generally, humans can often infer a complex sequence of past and future events from a *single snapshot image* of an intelligent agent. Building on recent work in cognitive science, we offer a Monte Carlo algorithm for making such inferences. Drawing a connection to Monte Carlo path tracing in computer graphics, we borrow ideas that help us dramatically improve upon prior work in sample efficiency. This allows us to scale to a wide variety of challenging inference problems with only a handful of samples. It also suggests some degree of cognitive plausibility, and indeed we present human subject studies showing that our algorithm matches human intuitions in a variety of domains that previous methods could not scale to.
Designing Perceptual Puzzles by Differentiating Probabilistic Programs
Apr 26, 2022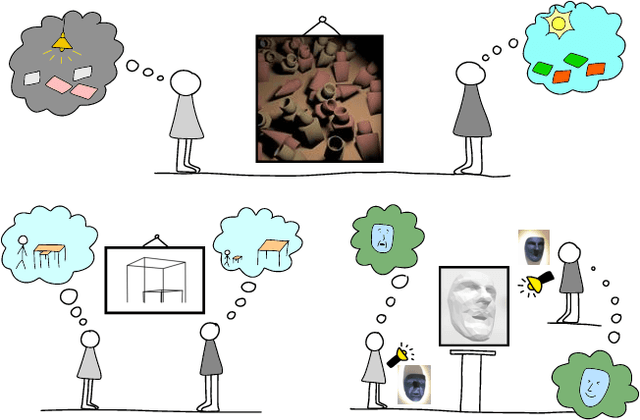

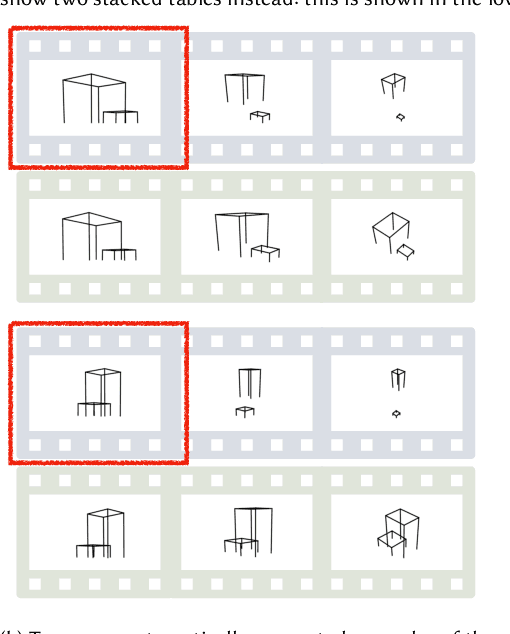
We design new visual illusions by finding "adversarial examples" for principled models of human perception -- specifically, for probabilistic models, which treat vision as Bayesian inference. To perform this search efficiently, we design a differentiable probabilistic programming language, whose API exposes MCMC inference as a first-class differentiable function. We demonstrate our method by automatically creating illusions for three features of human vision: color constancy, size constancy, and face perception.
Gradient Descent: The Ultimate Optimizer
Sep 29, 2019
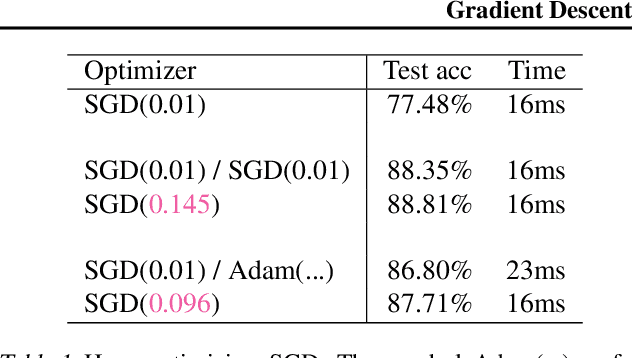
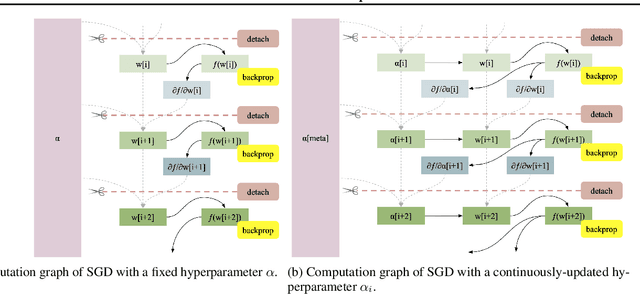
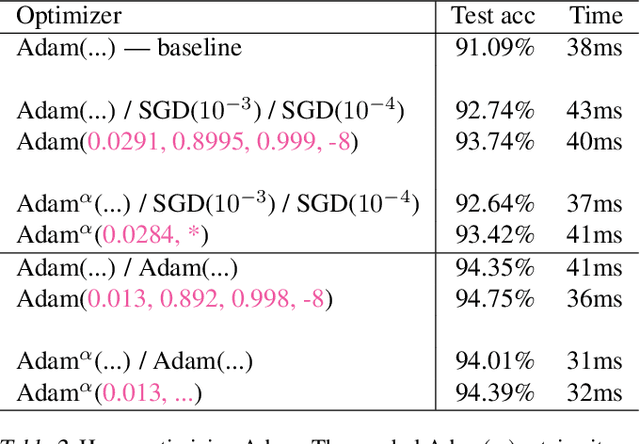
Working with any gradient-based machine learning algorithm involves the tedious task of tuning the optimizer's hyperparameters, such as the learning rate. There exist many techniques for automated hyperparameter optimization, but they typically introduce even more hyperparameters to control the hyperparameter optimization process. We propose to instead learn the hyperparameters themselves by gradient descent, and furthermore to learn the hyper-hyperparameters by gradient descent as well, and so on ad infinitum. As these towers of gradient-based optimizers grow, they become significantly less sensitive to the choice of top-level hyperparameters, hence decreasing the burden on the user to search for optimal values.