 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Symbolic Superoptimization of Tensor Programs
Apr 16, 2026This paper presents Prism, the first symbolic superoptimizer for tensor programs. The key idea is sGraph, a symbolic, hierarchical representation that compactly encodes large classes of tensor programs by symbolically representing some execution parameters. Prism organizes optimization as a two-level search: it constructs symbolic graphs that represent families of programs, and then instantiates them into concrete implementations. This formulation enables structured pruning of provably suboptimal regions of the search space using symbolic reasoning over operator semantics, algebraic identities, and hardware constraints. We develop techniques for efficient symbolic graph generation, equivalence verification via e-graph rewriting, and parameter instantiation through auto-tuning. Together, these components allow Prism to bridge the rigor of exhaustive search with the scalability required for modern ML workloads. Evaluation on five commonly used LLM workloads shows that Prism achieves up to $2.2\times$ speedup over best superoptimizers and $4.9\times$ over best compiler-based approaches, while reducing end-to-end optimization time by up to $3.4\times$.
A Multi-Level Superoptimizer for Tensor Programs
May 09, 2024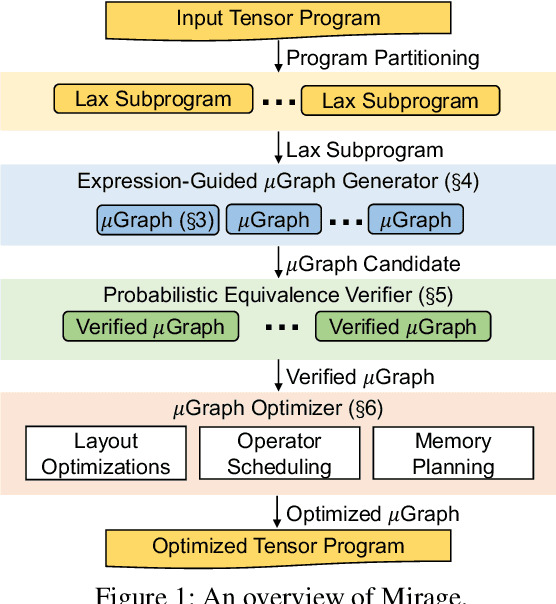

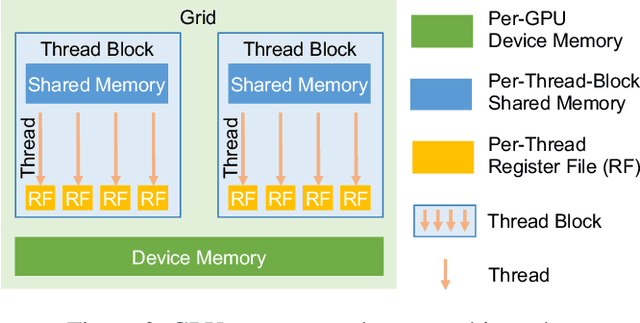

We introduce Mirage, the first multi-level superoptimizer for tensor programs. A key idea in Mirage is $\mu$Graphs, a uniform representation of tensor programs at the kernel, thread block, and thread levels of the GPU compute hierarchy. $\mu$Graphs enable Mirage to discover novel optimizations that combine algebraic transformations, schedule transformations, and generation of new custom kernels. To navigate the large search space, Mirage introduces a pruning technique based on abstraction that significantly reduces the search space and provides a certain optimality guarantee. To ensure that the optimized $\mu$Graph is equivalent to the input program, Mirage introduces a probabilistic equivalence verification procedure with strong theoretical guarantees. Our evaluation shows that Mirage outperforms existing approaches by up to 3.5$\times$ even for DNNs that are widely used and heavily optimized. Mirage is publicly available at https://github.com/mirage-project/mirage.
Clover: Closed-Loop Verifiable Code Generation
Oct 26, 2023



The use of large language models for code generation is a rapidly growing trend in software development. However, without effective methods for ensuring the correctness of generated code, this trend could lead to any number of undesirable outcomes. In this paper, we lay out a vision for addressing this challenge: the Clover paradigm, short for Closed-Loop Verifiable Code Generation, which reduces correctness checking to the more accessible problem of consistency checking. At the core of Clover lies a checker that performs consistency checks among code, docstrings, and formal annotations. The checker is implemented using a novel integration of formal verification tools and large language models. We provide a theoretical analysis to support our thesis that Clover should be effective at consistency checking. We also empirically investigate its feasibility on a hand-designed dataset (CloverBench) featuring annotated Dafny programs at a textbook level of difficulty. Experimental results show that for this dataset, (i) LLMs are reasonably successful at automatically generating formal specifications; and (ii) our consistency checker achieves a promising acceptance rate (up to 87%) for correct instances while maintaining zero tolerance for incorrect ones (no false positives).
Quarl: A Learning-Based Quantum Circuit Optimizer
Jul 17, 2023



Optimizing quantum circuits is challenging due to the very large search space of functionally equivalent circuits and the necessity of applying transformations that temporarily decrease performance to achieve a final performance improvement. This paper presents Quarl, a learning-based quantum circuit optimizer. Applying reinforcement learning (RL) to quantum circuit optimization raises two main challenges: the large and varying action space and the non-uniform state representation. Quarl addresses these issues with a novel neural architecture and RL-training procedure. Our neural architecture decomposes the action space into two parts and leverages graph neural networks in its state representation, both of which are guided by the intuition that optimization decisions can be mostly guided by local reasoning while allowing global circuit-wide reasoning. Our evaluation shows that Quarl significantly outperforms existing circuit optimizers on almost all benchmark circuits. Surprisingly, Quarl can learn to perform rotation merging, a complex, non-local circuit optimization implemented as a separate pass in existing optimizers.
SPoC: Search-based Pseudocode to Code
Jun 12, 2019
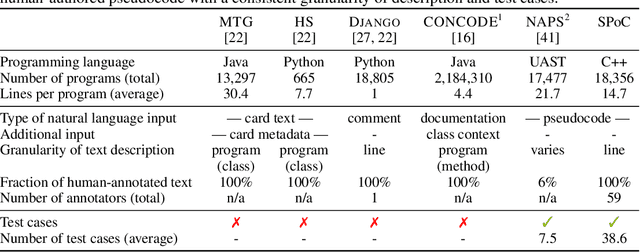
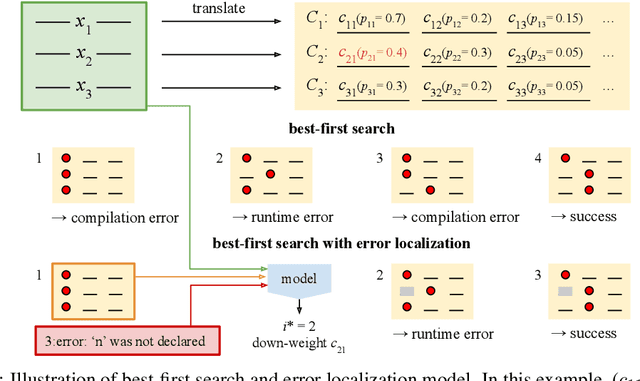
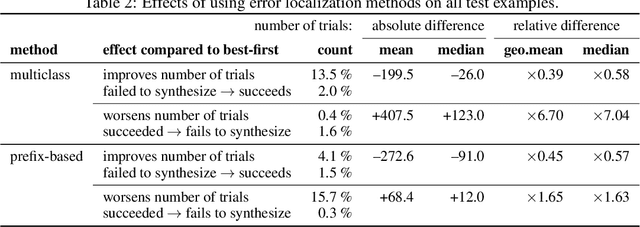
We consider the task of mapping pseudocode to long programs that are functionally correct. Given test cases as a mechanism to validate programs, we search over the space of possible translations of the pseudocode to find a program that passes the validation. However, without proper credit assignment to localize the sources of program failures, it is difficult to guide search toward more promising programs. We propose to perform credit assignment based on signals from compilation errors, which constitute 88.7% of program failures. Concretely, we treat the translation of each pseudocode line as a discrete portion of the program, and whenever a synthesized program fails to compile, an error localization method tries to identify the portion of the program responsible for the failure. We then focus search over alternative translations of the pseudocode for those portions. For evaluation, we collected the SPoC dataset (Search-based Pseudocode to Code) containing 18,356 programs with human-authored pseudocode and test cases. Under a budget of 100 program compilations, performing search improves the synthesis success rate over using the top-one translation of the pseudocode from 25.6% to 44.7%.