 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025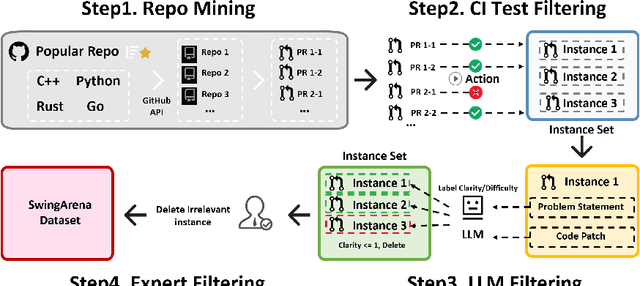
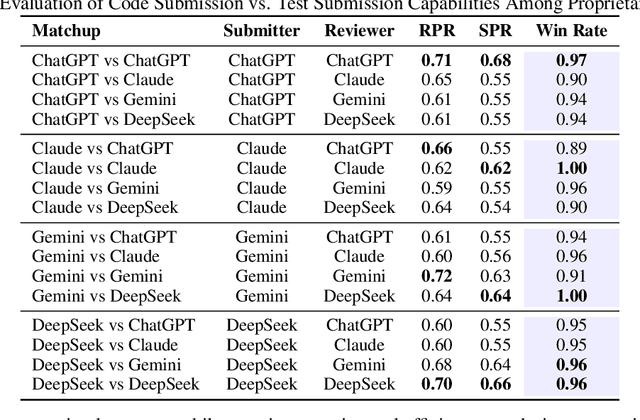
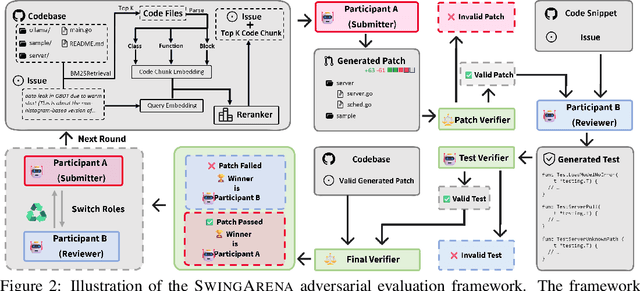
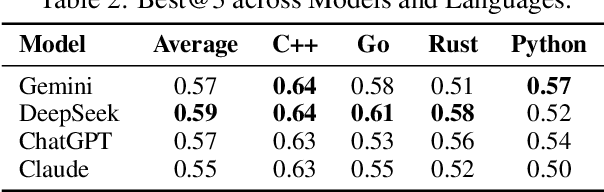
We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
Prism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving
May 06, 2025



Serving large language models (LLMs) is expensive, especially for providers hosting many models, making cost reduction essential. The unique workload patterns of serving multiple LLMs (i.e., multi-LLM serving) create new opportunities and challenges for this task. The long-tail popularity of models and their long idle periods present opportunities to improve utilization through GPU sharing. However, existing GPU sharing systems lack the ability to adjust their resource allocation and sharing policies at runtime, making them ineffective at meeting latency service-level objectives (SLOs) under rapidly fluctuating workloads. This paper presents Prism, a multi-LLM serving system that unleashes the full potential of GPU sharing to achieve both cost efficiency and SLO attainment. At its core, Prism tackles a key limitation of existing systems$\unicode{x2014}$the lack of $\textit{cross-model memory coordination}$, which is essential for flexibly sharing GPU memory across models under dynamic workloads. Prism achieves this with two key designs. First, it supports on-demand memory allocation by dynamically mapping physical to virtual memory pages, allowing flexible memory redistribution among models that space- and time-share a GPU. Second, it improves memory efficiency through a two-level scheduling policy that dynamically adjusts sharing strategies based on models' runtime demands. Evaluations on real-world traces show that Prism achieves more than $2\times$ cost savings and $3.3\times$ SLO attainment compared to state-of-the-art systems.
Locality-aware Fair Scheduling in LLM Serving
Jan 24, 2025

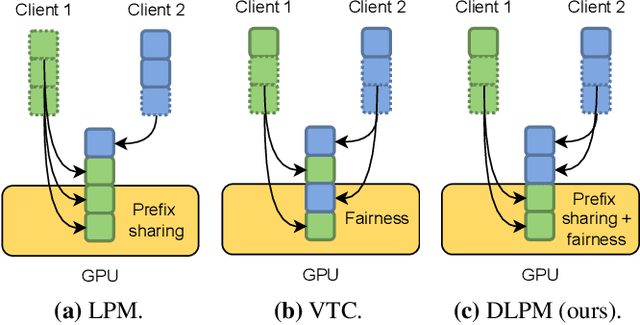
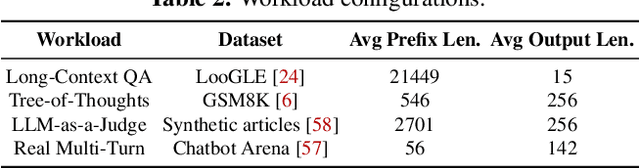
Large language model (LLM) inference workload dominates a wide variety of modern AI applications, ranging from multi-turn conversation to document analysis. Balancing fairness and efficiency is critical for managing diverse client workloads with varying prefix patterns. Unfortunately, existing fair scheduling algorithms for LLM serving, such as Virtual Token Counter (VTC), fail to take prefix locality into consideration and thus suffer from poor performance. On the other hand, locality-aware scheduling algorithms in existing LLM serving frameworks tend to maximize the prefix cache hit rate without considering fair sharing among clients. This paper introduces the first locality-aware fair scheduling algorithm, Deficit Longest Prefix Match (DLPM), which can maintain a high degree of prefix locality with a fairness guarantee. We also introduce a novel algorithm, Double Deficit LPM (D$^2$LPM), extending DLPM for the distributed setup that can find a balance point among fairness, locality, and load-balancing. Our extensive evaluation demonstrates the superior performance of DLPM and D$^2$LPM in ensuring fairness while maintaining high throughput (up to 2.87$\times$ higher than VTC) and low per-client (up to 7.18$\times$ lower than state-of-the-art distributed LLM serving system) latency.
MoE-Lightning: High-Throughput MoE Inference on Memory-constrained GPUs
Nov 18, 2024



Efficient deployment of large language models, particularly Mixture of Experts (MoE), on resource-constrained platforms presents significant challenges, especially in terms of computational efficiency and memory utilization. The MoE architecture, renowned for its ability to increase model capacity without a proportional increase in inference cost, greatly reduces the token generation latency compared with dense models. However, the large model size makes MoE models inaccessible to individuals without high-end GPUs. In this paper, we propose a high-throughput MoE batch inference system, that significantly outperforms past work. MoE-Lightning introduces a novel CPU-GPU-I/O pipelining schedule, CGOPipe, with paged weights to achieve high resource utilization, and a performance model, HRM, based on a Hierarchical Roofline Model we introduce to help find policies with higher throughput than existing systems. MoE-Lightning can achieve up to 10.3x higher throughput than state-of-the-art offloading-enabled LLM inference systems for Mixtral 8x7B on a single T4 GPU (16GB). When the theoretical system throughput is bounded by the GPU memory, MoE-Lightning can reach the throughput upper bound with 2-3x less CPU memory, significantly increasing resource utilization. MoE-Lightning also supports efficient batch inference for much larger MoEs (e.g., Mixtral 8x22B and DBRX) on multiple low-cost GPUs (e.g., 2-4 T4).
AI Metropolis: Scaling Large Language Model-based Multi-Agent Simulation with Out-of-order Execution
Nov 05, 2024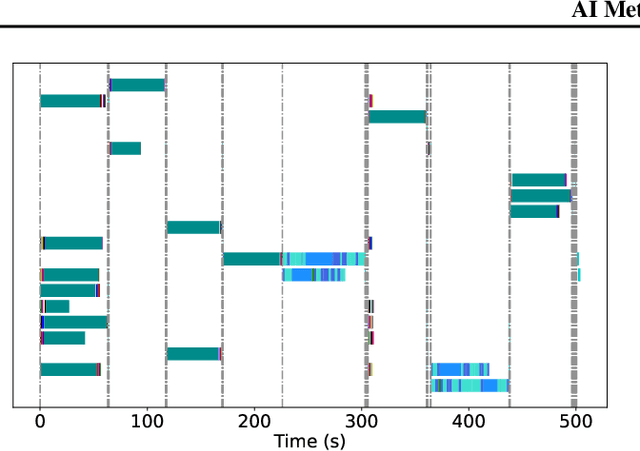
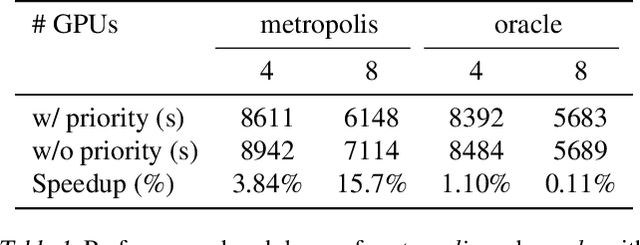
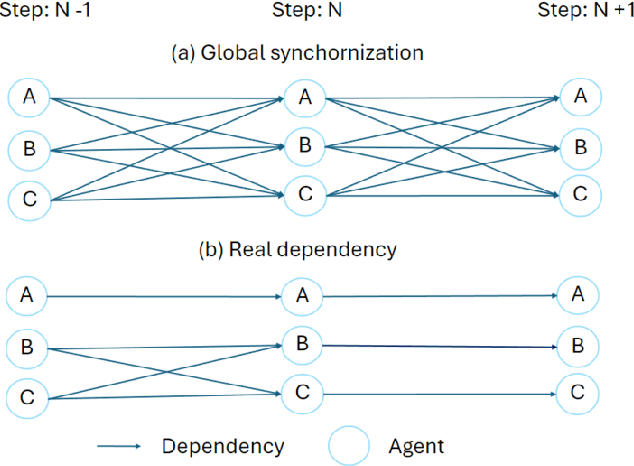
With more advanced natural language understanding and reasoning capabilities, large language model (LLM)-powered agents are increasingly developed in simulated environments to perform complex tasks, interact with other agents, and exhibit emergent behaviors relevant to social science and gaming. However, current multi-agent simulations frequently suffer from inefficiencies due to the limited parallelism caused by false dependencies, resulting in performance bottlenecks. In this paper, we introduce AI Metropolis, a simulation engine that improves the efficiency of LLM agent simulations by incorporating out-of-order execution scheduling. By dynamically tracking real dependencies between agents, AI Metropolis minimizes false dependencies, enhancing parallelism and enabling efficient hardware utilization. Our evaluations demonstrate that AI Metropolis achieves speedups from 1.3x to 4.15x over standard parallel simulation with global synchronization, approaching optimal performance as the number of agents increases.
Post-Training Sparse Attention with Double Sparsity
Aug 11, 2024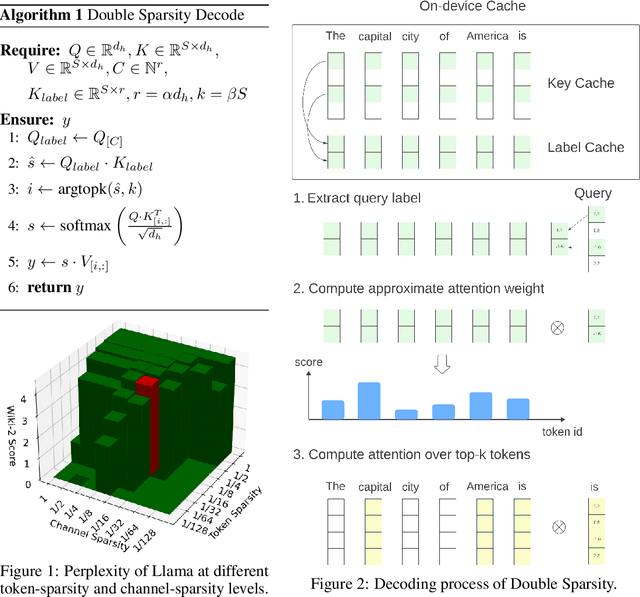

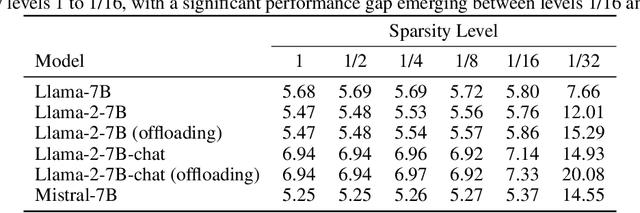
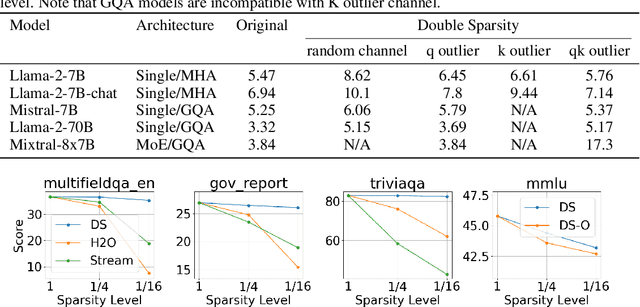
The inference process for large language models is slow and memory-intensive, with one of the most critical bottlenecks being excessive Key-Value (KV) cache accesses. This paper introduces "Double Sparsity," a novel post-training sparse attention technique designed to alleviate this bottleneck by reducing KV cache access. Double Sparsity combines token sparsity, which focuses on utilizing only the important tokens for computing self-attention, with channel sparsity, an approach that uses important feature channels for identifying important tokens. Our key insight is that the pattern of channel sparsity is relatively static, allowing us to use offline calibration to make it efficient at runtime, thereby enabling accurate and efficient identification of important tokens. Moreover, this method can be combined with offloading to achieve significant memory usage reduction. Experimental results demonstrate that Double Sparsity can achieve \(\frac{1}{16}\) token and channel sparsity with minimal impact on accuracy across various tasks, including wiki-2 perplexity, key-value retrieval, and long context benchmarks with models including Llama-2-7B, Llama-2-70B, and Mixtral-8x7B. It brings up to a 14.1$\times$ acceleration in attention operations and a 1.9$\times$ improvement in end-to-end inference on GPUs. With offloading, it achieves a decoding speed acceleration of 16.3$\times$ compared to state-of-the-art solutions at a sequence length of 256K. Our code is publicly available at \url{https://github.com/andy-yang-1/DoubleSparse}.
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal Behaviors
Jun 20, 2024



Evaluating aligned large language models' (LLMs) ability to recognize and reject unsafe user requests is crucial for safe, policy-compliant deployments. Existing evaluation efforts, however, face three limitations that we address with SORRY-Bench, our proposed benchmark. First, existing methods often use coarse-grained taxonomies of unsafe topics, and are over-representing some fine-grained topics. For example, among the ten existing datasets that we evaluated, tests for refusals of self-harm instructions are over 3x less represented than tests for fraudulent activities. SORRY-Bench improves on this by using a fine-grained taxonomy of 45 potentially unsafe topics, and 450 class-balanced unsafe instructions, compiled through human-in-the-loop methods. Second, linguistic characteristics and formatting of prompts are often overlooked, like different languages, dialects, and more -- which are only implicitly considered in many evaluations. We supplement SORRY-Bench with 20 diverse linguistic augmentations to systematically examine these effects. Third, existing evaluations rely on large LLMs (e.g., GPT-4) for evaluation, which can be computationally expensive. We investigate design choices for creating a fast, accurate automated safety evaluator. By collecting 7K+ human annotations and conducting a meta-evaluation of diverse LLM-as-a-judge designs, we show that fine-tuned 7B LLMs can achieve accuracy comparable to GPT-4 scale LLMs, with lower computational cost. Putting these together, we evaluate over 40 proprietary and open-source LLMs on SORRY-Bench, analyzing their distinctive refusal behaviors. We hope our effort provides a building block for systematic evaluations of LLMs' safety refusal capabilities, in a balanced, granular, and efficient manner.
DafnyBench: A Benchmark for Formal Software Verification
Jun 12, 2024



We introduce DafnyBench, the largest benchmark of its kind for training and evaluating machine learning systems for formal software verification. We test the ability of LLMs such as GPT-4 and Claude 3 to auto-generate enough hints for the Dafny formal verification engine to successfully verify over 750 programs with about 53,000 lines of code. The best model and prompting scheme achieved 68% success rate, and we quantify how this rate improves when retrying with error message feedback and how it deteriorates with the amount of required code and hints. We hope that DafnyBench will enable rapid improvements from this baseline as LLMs and verification techniques grow in quality.
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Mar 07, 2024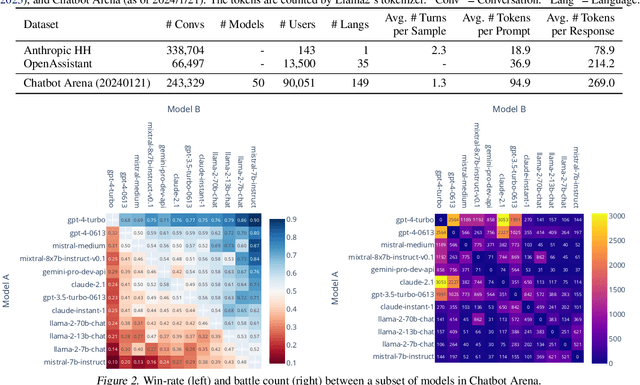
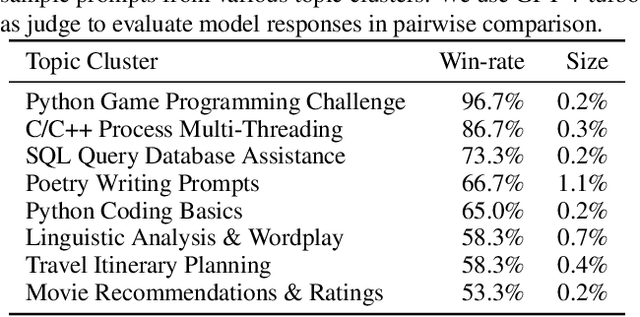
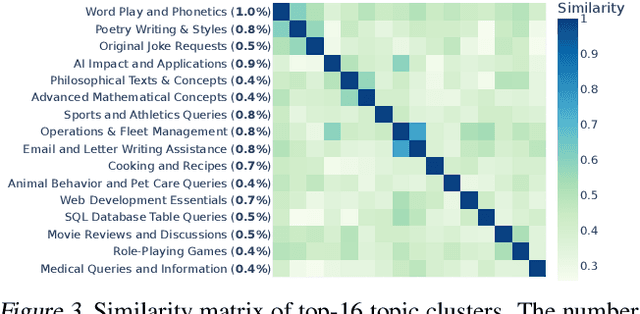
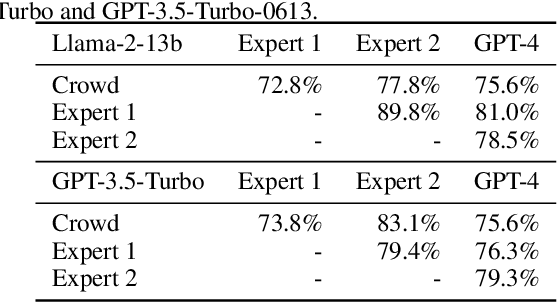
Large Language Models (LLMs) have unlocked new capabilities and applications; however, evaluating the alignment with human preferences still poses significant challenges. To address this issue, we introduce Chatbot Arena, an open platform for evaluating LLMs based on human preferences. Our methodology employs a pairwise comparison approach and leverages input from a diverse user base through crowdsourcing. The platform has been operational for several months, amassing over 240K votes. This paper describes the platform, analyzes the data we have collected so far, and explains the tried-and-true statistical methods we are using for efficient and accurate evaluation and ranking of models. We confirm that the crowdsourced questions are sufficiently diverse and discriminating and that the crowdsourced human votes are in good agreement with those of expert raters. These analyses collectively establish a robust foundation for the credibility of Chatbot Arena. Because of its unique value and openness, Chatbot Arena has emerged as one of the most referenced LLM leaderboards, widely cited by leading LLM developers and companies. Our demo is publicly available at \url{https://chat.lmsys.org}.
Fairness in Serving Large Language Models
Dec 31, 2023
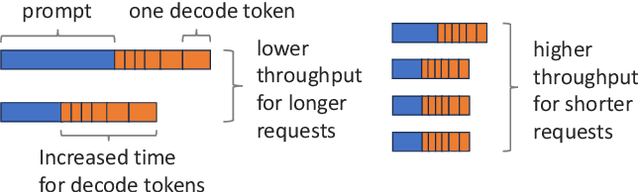
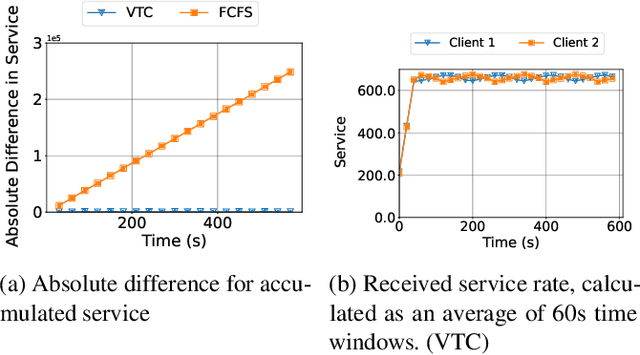
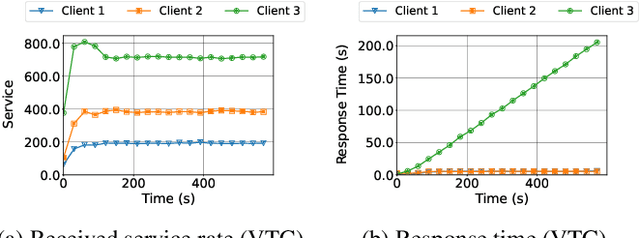
High-demand LLM inference services (e.g., ChatGPT and BARD) support a wide range of requests from short chat conversations to long document reading. To ensure that all client requests are processed fairly, most major LLM inference services have request rate limits, to ensure that no client can dominate the request queue. However, this rudimentary notion of fairness also results in under-utilization of the resources and poor client experience when there is spare capacity. While there is a rich literature on fair scheduling, serving LLMs presents new challenges due to their unpredictable request lengths and their unique batching characteristics on parallel accelerators. This paper introduces the definition of LLM serving fairness based on a cost function that accounts for the number of input and output tokens processed. To achieve fairness in serving, we propose a novel scheduling algorithm, the Virtual Token Counter (VTC), a fair scheduler based on the continuous batching mechanism. We prove a 2x tight upper bound on the service difference between two backlogged clients, adhering to the requirement of work-conserving. Through extensive experiments, we demonstrate the superior performance of VTC in ensuring fairness, especially in contrast to other baseline methods, which exhibit shortcomings under various conditions.