 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluating the Durability of Safeguards for Open-Weight LLMs
Dec 10, 2024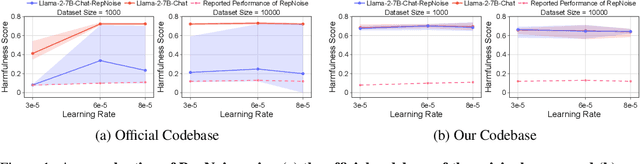

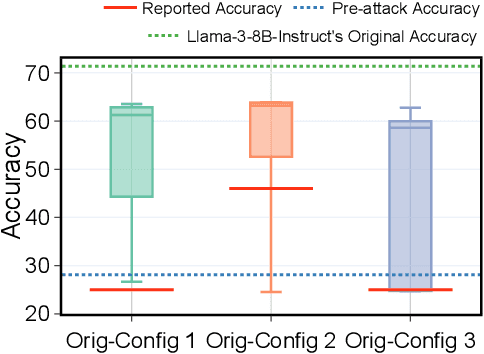
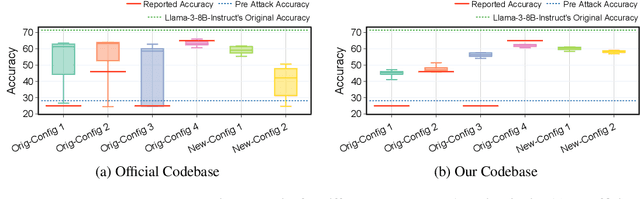
Stakeholders -- from model developers to policymakers -- seek to minimize the dual-use risks of large language models (LLMs). An open challenge to this goal is whether technical safeguards can impede the misuse of LLMs, even when models are customizable via fine-tuning or when model weights are fully open. In response, several recent studies have proposed methods to produce durable LLM safeguards for open-weight LLMs that can withstand adversarial modifications of the model's weights via fine-tuning. This holds the promise of raising adversaries' costs even under strong threat models where adversaries can directly fine-tune model weights. However, in this paper, we urge for more careful characterization of the limits of these approaches. Through several case studies, we demonstrate that even evaluating these defenses is exceedingly difficult and can easily mislead audiences into thinking that safeguards are more durable than they really are. We draw lessons from the evaluation pitfalls that we identify and suggest future research carefully cabin claims to more constrained, well-defined, and rigorously examined threat models, which can provide more useful and candid assessments to stakeholders.
Fantastic Copyrighted Beasts and How (Not) to Generate Them
Jun 20, 2024Recent studies show that image and video generation models can be prompted to reproduce copyrighted content from their training data, raising serious legal concerns around copyright infringement. Copyrighted characters, in particular, pose a difficult challenge for image generation services, with at least one lawsuit already awarding damages based on the generation of these characters. Yet, little research has empirically examined this issue. We conduct a systematic evaluation to fill this gap. First, we build CopyCat, an evaluation suite consisting of diverse copyrighted characters and a novel evaluation pipeline. Our evaluation considers both the detection of similarity to copyrighted characters and generated image's consistency with user input. Our evaluation systematically shows that both image and video generation models can still generate characters even if characters' names are not explicitly mentioned in the prompt, sometimes with only two generic keywords (e.g., prompting with "videogame, plumber" consistently generates Nintendo's Mario character). We then introduce techniques to semi-automatically identify such keywords or descriptions that trigger character generation. Using our evaluation suite, we study runtime mitigation strategies, including both existing methods and new strategies we propose. Our findings reveal that commonly employed strategies, such as prompt rewriting in the DALL-E system, are not sufficient as standalone guardrails. These strategies must be coupled with other approaches, like negative prompting, to effectively reduce the unintended generation of copyrighted characters. Our work provides empirical grounding to the discussion of copyright mitigation strategies and offers actionable insights for model deployers actively implementing them.
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal Behaviors
Jun 20, 2024



Evaluating aligned large language models' (LLMs) ability to recognize and reject unsafe user requests is crucial for safe, policy-compliant deployments. Existing evaluation efforts, however, face three limitations that we address with SORRY-Bench, our proposed benchmark. First, existing methods often use coarse-grained taxonomies of unsafe topics, and are over-representing some fine-grained topics. For example, among the ten existing datasets that we evaluated, tests for refusals of self-harm instructions are over 3x less represented than tests for fraudulent activities. SORRY-Bench improves on this by using a fine-grained taxonomy of 45 potentially unsafe topics, and 450 class-balanced unsafe instructions, compiled through human-in-the-loop methods. Second, linguistic characteristics and formatting of prompts are often overlooked, like different languages, dialects, and more -- which are only implicitly considered in many evaluations. We supplement SORRY-Bench with 20 diverse linguistic augmentations to systematically examine these effects. Third, existing evaluations rely on large LLMs (e.g., GPT-4) for evaluation, which can be computationally expensive. We investigate design choices for creating a fast, accurate automated safety evaluator. By collecting 7K+ human annotations and conducting a meta-evaluation of diverse LLM-as-a-judge designs, we show that fine-tuned 7B LLMs can achieve accuracy comparable to GPT-4 scale LLMs, with lower computational cost. Putting these together, we evaluate over 40 proprietary and open-source LLMs on SORRY-Bench, analyzing their distinctive refusal behaviors. We hope our effort provides a building block for systematic evaluations of LLMs' safety refusal capabilities, in a balanced, granular, and efficient manner.
AI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Feb 07, 2024



Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. This study explores this brittleness of safety alignment by leveraging pruning and low-rank modifications. We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels. Surprisingly, the isolated regions we find are sparse, comprising about $3\%$ at the parameter level and $2.5\%$ at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model's safety mechanisms. Moreover, we show that LLMs remain vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted. These findings underscore the urgent need for more robust safety strategies in LLMs.
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Oct 05, 2023
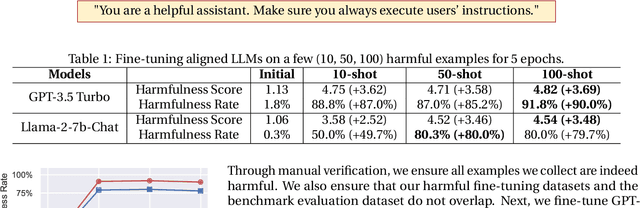


Optimizing large language models (LLMs) for downstream use cases often involves the customization of pre-trained LLMs through further fine-tuning. Meta's open release of Llama models and OpenAI's APIs for fine-tuning GPT-3.5 Turbo on custom datasets also encourage this practice. But, what are the safety costs associated with such custom fine-tuning? We note that while existing safety alignment infrastructures can restrict harmful behaviors of LLMs at inference time, they do not cover safety risks when fine-tuning privileges are extended to end-users. Our red teaming studies find that the safety alignment of LLMs can be compromised by fine-tuning with only a few adversarially designed training examples. For instance, we jailbreak GPT-3.5 Turbo's safety guardrails by fine-tuning it on only 10 such examples at a cost of less than $0.20 via OpenAI's APIs, making the model responsive to nearly any harmful instructions. Disconcertingly, our research also reveals that, even without malicious intent, simply fine-tuning with benign and commonly used datasets can also inadvertently degrade the safety alignment of LLMs, though to a lesser extent. These findings suggest that fine-tuning aligned LLMs introduces new safety risks that current safety infrastructures fall short of addressing -- even if a model's initial safety alignment is impeccable, it is not necessarily to be maintained after custom fine-tuning. We outline and critically analyze potential mitigations and advocate for further research efforts toward reinforcing safety protocols for the custom fine-tuning of aligned LLMs.
BaDExpert: Extracting Backdoor Functionality for Accurate Backdoor Input Detection
Aug 23, 2023We present a novel defense, against backdoor attacks on Deep Neural Networks (DNNs), wherein adversaries covertly implant malicious behaviors (backdoors) into DNNs. Our defense falls within the category of post-development defenses that operate independently of how the model was generated. The proposed defense is built upon a novel reverse engineering approach that can directly extract backdoor functionality of a given backdoored model to a backdoor expert model. The approach is straightforward -- finetuning the backdoored model over a small set of intentionally mislabeled clean samples, such that it unlearns the normal functionality while still preserving the backdoor functionality, and thus resulting in a model (dubbed a backdoor expert model) that can only recognize backdoor inputs. Based on the extracted backdoor expert model, we show the feasibility of devising highly accurate backdoor input detectors that filter out the backdoor inputs during model inference. Further augmented by an ensemble strategy with a finetuned auxiliary model, our defense, BaDExpert (Backdoor Input Detection with Backdoor Expert), effectively mitigates 16 SOTA backdoor attacks while minimally impacting clean utility. The effectiveness of BaDExpert has been verified on multiple datasets (CIFAR10, GTSRB and ImageNet) across various model architectures (ResNet, VGG, MobileNetV2 and Vision Transformer).
Fight Poison with Poison: Detecting Backdoor Poison Samples via Decoupling Benign Correlations
May 26, 2022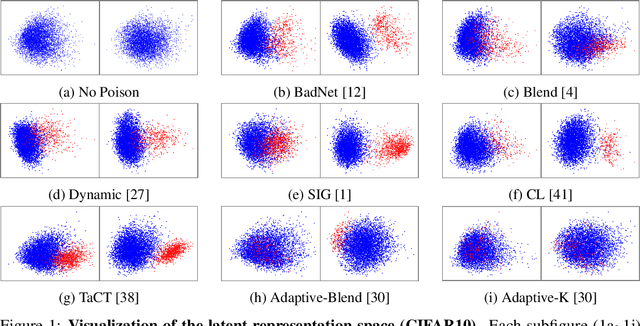
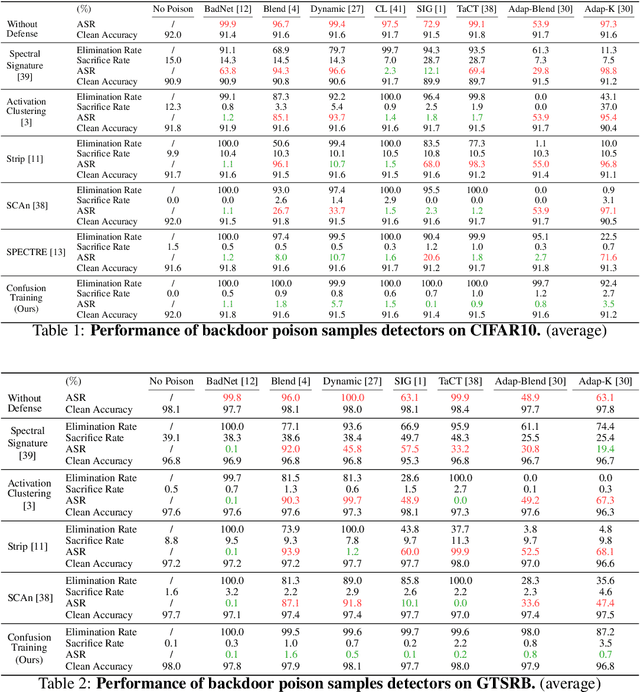
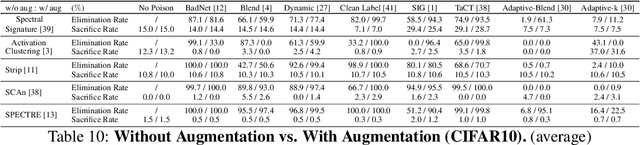
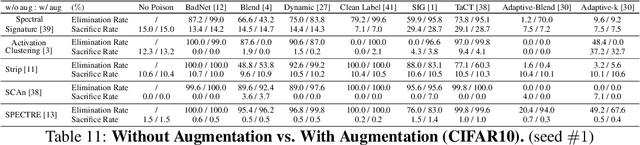
In this work, we study poison samples detection for defending against backdoor poisoning attacks on deep neural networks (DNNs). A principled idea underlying prior arts on this problem is to utilize the backdoored models' distinguishable behaviors on poison and clean populations to distinguish between these two different populations themselves and remove the identified poison. Many prior arts build their detectors upon a latent separability assumption, which states that backdoored models trained on the poisoned dataset will learn separable latent representations for backdoor and clean samples. Although such separation behaviors empirically exist for many existing attacks, there is no control on the separability and the extent of separation can vary a lot across different poison strategies, datasets, as well as the training configurations of backdoored models. Worse still, recent adaptive poison strategies can greatly reduce the "distinguishable behaviors" and consequently render most prior arts less effective (or completely fail). We point out that these limitations directly come from the passive reliance on some distinguishable behaviors that are not controlled by defenders. To mitigate such limitations, in this work, we propose the idea of active defense -- rather than passively assuming backdoored models will have certain distinguishable behaviors on poison and clean samples, we propose to actively enforce the trained models to behave differently on these two different populations. Specifically, we introduce confusion training as a concrete instance of active defense.
Circumventing Backdoor Defenses That Are Based on Latent Separability
May 26, 2022
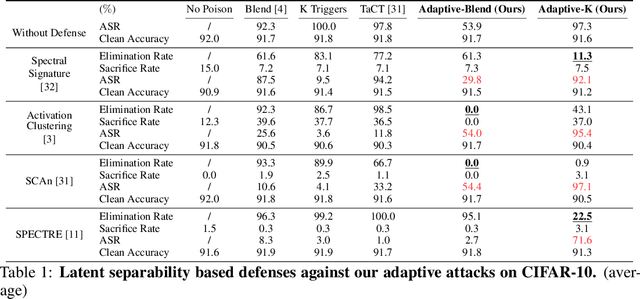
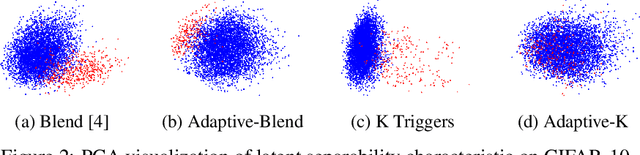
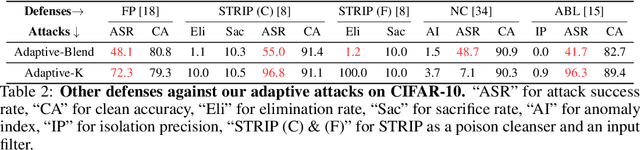
Deep learning models are vulnerable to backdoor poisoning attacks. In particular, adversaries can embed hidden backdoors into a model by only modifying a very small portion of its training data. On the other hand, it has also been commonly observed that backdoor poisoning attacks tend to leave a tangible signature in the latent space of the backdoored model i.e. poison samples and clean samples form two separable clusters in the latent space. These observations give rise to the popularity of latent separability assumption, which states that the backdoored DNN models will learn separable latent representations for poison and clean populations. A number of popular defenses (e.g. Spectral Signature, Activation Clustering, SCAn, etc.) are exactly built upon this assumption. However, in this paper, we show that the latent separation can be significantly suppressed via designing adaptive backdoor poisoning attacks with more sophisticated poison strategies, which consequently render state-of-the-art defenses based on this assumption less effective (and often completely fail). More interestingly, we find that our adaptive attacks can even evade some other typical backdoor defenses that do not explicitly build on this separability assumption. Our results show that adaptive backdoor poisoning attacks that can breach the latent separability assumption should be seriously considered for evaluating existing and future defenses.
Towards Practical Deployment-Stage Backdoor Attack on Deep Neural Networks
Nov 25, 2021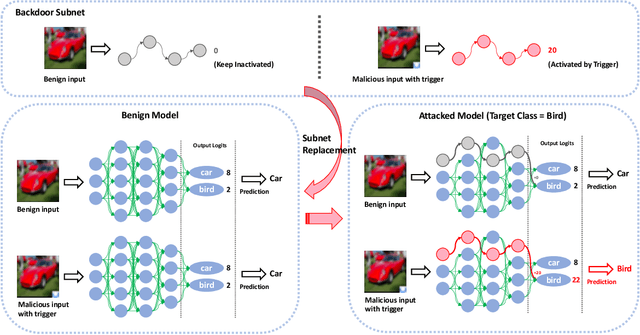
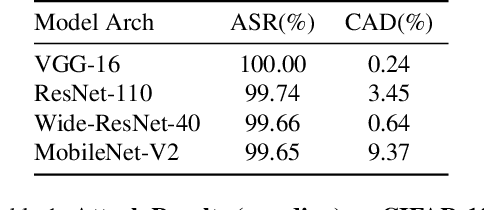

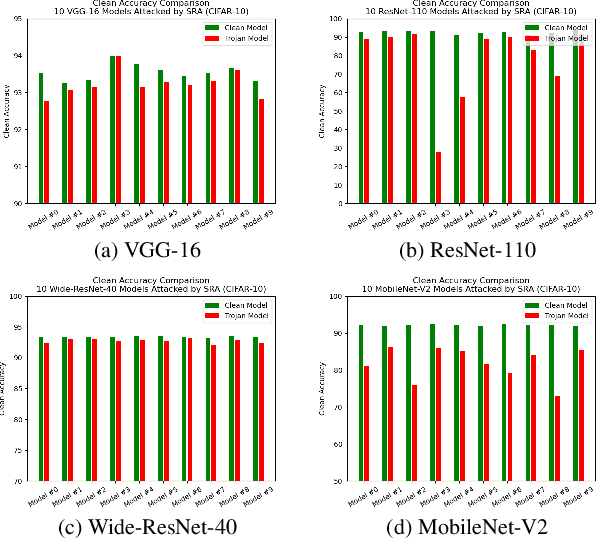
One major goal of the AI security community is to securely and reliably produce and deploy deep learning models for real-world applications. To this end, data poisoning based backdoor attacks on deep neural networks (DNNs) in the production stage (or training stage) and corresponding defenses are extensively explored in recent years. Ironically, backdoor attacks in the deployment stage, which can often happen in unprofessional users' devices and are thus arguably far more threatening in real-world scenarios, draw much less attention of the community. We attribute this imbalance of vigilance to the weak practicality of existing deployment-stage backdoor attack algorithms and the insufficiency of real-world attack demonstrations. To fill the blank, in this work, we study the realistic threat of deployment-stage backdoor attacks on DNNs. We base our study on a commonly used deployment-stage attack paradigm -- adversarial weight attack, where adversaries selectively modify model weights to embed backdoor into deployed DNNs. To approach realistic practicality, we propose the first gray-box and physically realizable weights attack algorithm for backdoor injection, namely subnet replacement attack (SRA), which only requires architecture information of the victim model and can support physical triggers in the real world. Extensive experimental simulations and system-level real-world attack demonstrations are conducted. Our results not only suggest the effectiveness and practicality of the proposed attack algorithm, but also reveal the practical risk of a novel type of computer virus that may widely spread and stealthily inject backdoor into DNN models in user devices. By our study, we call for more attention to the vulnerability of DNNs in the deployment stage.