 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFight Poison with Poison: Detecting Backdoor Poison Samples via Decoupling Benign Correlations
Paper and Code
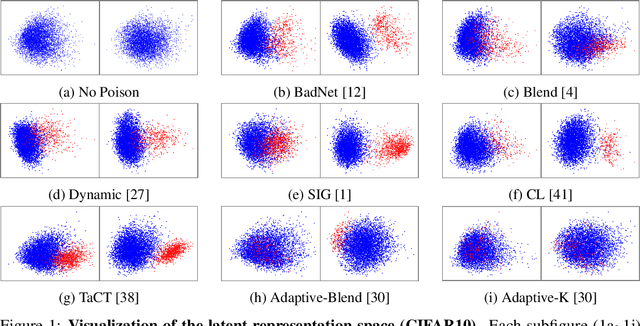
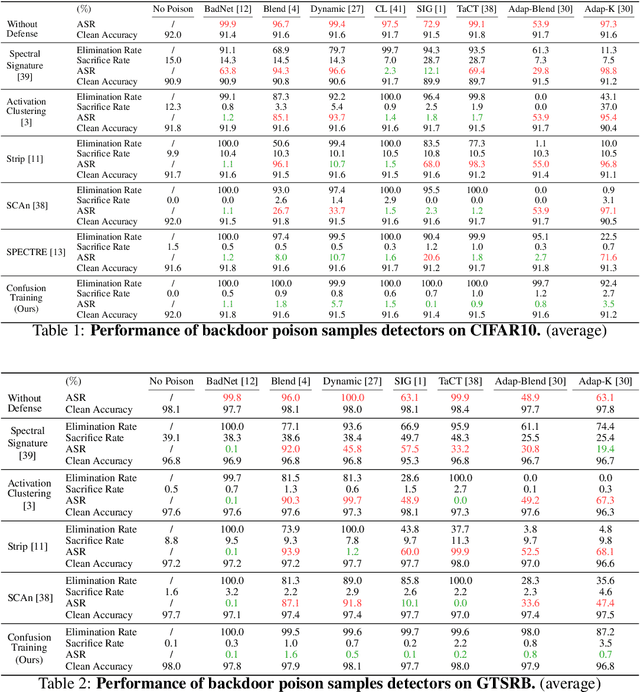
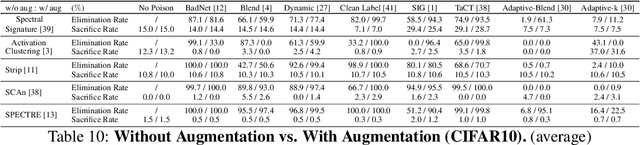
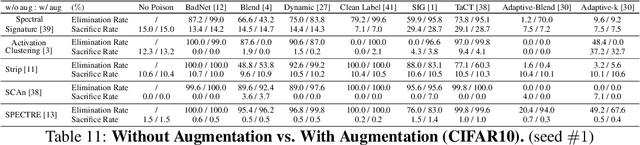
In this work, we study poison samples detection for defending against backdoor poisoning attacks on deep neural networks (DNNs). A principled idea underlying prior arts on this problem is to utilize the backdoored models' distinguishable behaviors on poison and clean populations to distinguish between these two different populations themselves and remove the identified poison. Many prior arts build their detectors upon a latent separability assumption, which states that backdoored models trained on the poisoned dataset will learn separable latent representations for backdoor and clean samples. Although such separation behaviors empirically exist for many existing attacks, there is no control on the separability and the extent of separation can vary a lot across different poison strategies, datasets, as well as the training configurations of backdoored models. Worse still, recent adaptive poison strategies can greatly reduce the "distinguishable behaviors" and consequently render most prior arts less effective (or completely fail). We point out that these limitations directly come from the passive reliance on some distinguishable behaviors that are not controlled by defenders. To mitigate such limitations, in this work, we propose the idea of active defense -- rather than passively assuming backdoored models will have certain distinguishable behaviors on poison and clean samples, we propose to actively enforce the trained models to behave differently on these two different populations. Specifically, we introduce confusion training as a concrete instance of active defense.