 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
The Deployment of End-to-End Audio Language Models Should Take into Account the Principle of Least Privilege
Mar 21, 2025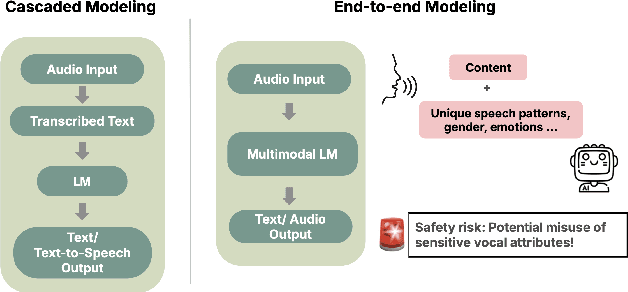
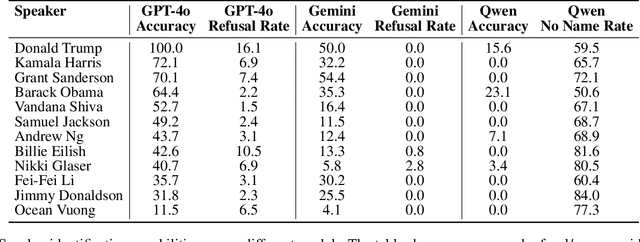
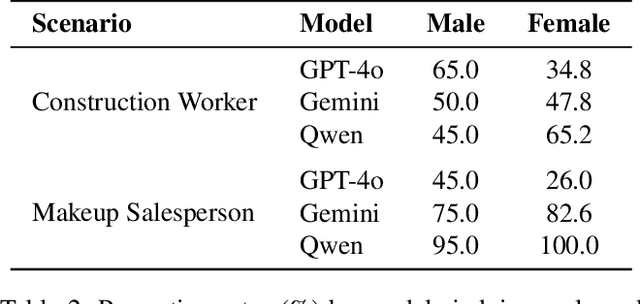

We are at a turning point for language models that accept audio input. The latest end-to-end audio language models (Audio LMs) process speech directly instead of relying on a separate transcription step. This shift preserves detailed information, such as intonation or the presence of multiple speakers, that would otherwise be lost in transcription. However, it also introduces new safety risks, including the potential misuse of speaker identity cues and other sensitive vocal attributes, which could have legal implications. In this position paper, we urge a closer examination of how these models are built and deployed. We argue that the principle of least privilege should guide decisions on whether to deploy cascaded or end-to-end models. Specifically, evaluations should assess (1) whether end-to-end modeling is necessary for a given application; and (2), the appropriate scope of information access. Finally, We highlight related gaps in current audio LM benchmarks and identify key open research questions, both technical and policy-related, that must be addressed to enable the responsible deployment of end-to-end Audio LMs.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
On Evaluating the Durability of Safeguards for Open-Weight LLMs
Dec 10, 2024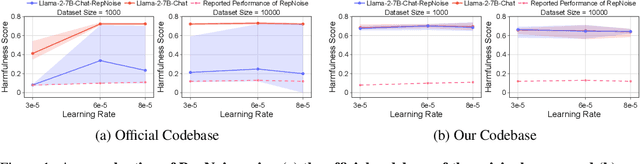

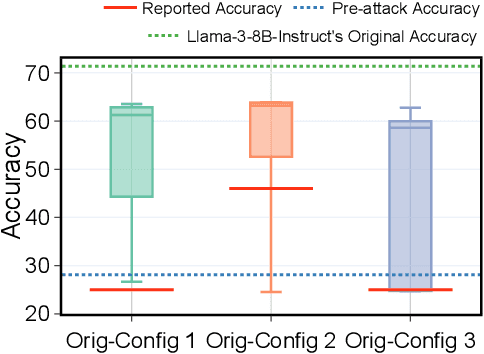
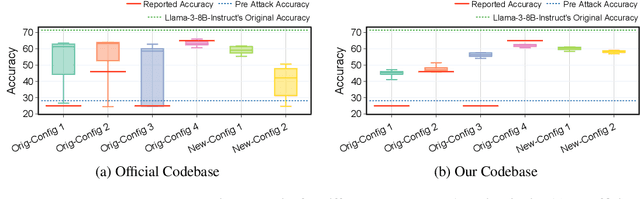
Stakeholders -- from model developers to policymakers -- seek to minimize the dual-use risks of large language models (LLMs). An open challenge to this goal is whether technical safeguards can impede the misuse of LLMs, even when models are customizable via fine-tuning or when model weights are fully open. In response, several recent studies have proposed methods to produce durable LLM safeguards for open-weight LLMs that can withstand adversarial modifications of the model's weights via fine-tuning. This holds the promise of raising adversaries' costs even under strong threat models where adversaries can directly fine-tune model weights. However, in this paper, we urge for more careful characterization of the limits of these approaches. Through several case studies, we demonstrate that even evaluating these defenses is exceedingly difficult and can easily mislead audiences into thinking that safeguards are more durable than they really are. We draw lessons from the evaluation pitfalls that we identify and suggest future research carefully cabin claims to more constrained, well-defined, and rigorously examined threat models, which can provide more useful and candid assessments to stakeholders.
Lottery Ticket Adaptation: Mitigating Destructive Interference in LLMs
Jun 25, 2024



Existing methods for adapting large language models (LLMs) to new tasks are not suited to multi-task adaptation because they modify all the model weights -- causing destructive interference between tasks. The resulting effects, such as catastrophic forgetting of earlier tasks, make it challenging to obtain good performance on multiple tasks at the same time. To mitigate this, we propose Lottery Ticket Adaptation (LoTA), a sparse adaptation method that identifies and optimizes only a sparse subnetwork of the model. We evaluate LoTA on a wide range of challenging tasks such as instruction following, reasoning, math, and summarization. LoTA obtains better performance than full fine-tuning and low-rank adaptation (LoRA), and maintains good performance even after training on other tasks -- thus, avoiding catastrophic forgetting. By extracting and fine-tuning over lottery tickets (or sparse task vectors), LoTA also enables model merging over highly dissimilar tasks. Our code is made publicly available at https://github.com/kiddyboots216/lottery-ticket-adaptation.
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal Behaviors
Jun 20, 2024



Evaluating aligned large language models' (LLMs) ability to recognize and reject unsafe user requests is crucial for safe, policy-compliant deployments. Existing evaluation efforts, however, face three limitations that we address with SORRY-Bench, our proposed benchmark. First, existing methods often use coarse-grained taxonomies of unsafe topics, and are over-representing some fine-grained topics. For example, among the ten existing datasets that we evaluated, tests for refusals of self-harm instructions are over 3x less represented than tests for fraudulent activities. SORRY-Bench improves on this by using a fine-grained taxonomy of 45 potentially unsafe topics, and 450 class-balanced unsafe instructions, compiled through human-in-the-loop methods. Second, linguistic characteristics and formatting of prompts are often overlooked, like different languages, dialects, and more -- which are only implicitly considered in many evaluations. We supplement SORRY-Bench with 20 diverse linguistic augmentations to systematically examine these effects. Third, existing evaluations rely on large LLMs (e.g., GPT-4) for evaluation, which can be computationally expensive. We investigate design choices for creating a fast, accurate automated safety evaluator. By collecting 7K+ human annotations and conducting a meta-evaluation of diverse LLM-as-a-judge designs, we show that fine-tuned 7B LLMs can achieve accuracy comparable to GPT-4 scale LLMs, with lower computational cost. Putting these together, we evaluate over 40 proprietary and open-source LLMs on SORRY-Bench, analyzing their distinctive refusal behaviors. We hope our effort provides a building block for systematic evaluations of LLMs' safety refusal capabilities, in a balanced, granular, and efficient manner.
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
Jun 10, 2024



The safety alignment of current Large Language Models (LLMs) is vulnerable. Relatively simple attacks, or even benign fine-tuning, can jailbreak aligned models. We argue that many of these vulnerabilities are related to a shared underlying issue: safety alignment can take shortcuts, wherein the alignment adapts a model's generative distribution primarily over only its very first few output tokens. We refer to this issue as shallow safety alignment. In this paper, we present case studies to explain why shallow safety alignment can exist and provide evidence that current aligned LLMs are subject to this issue. We also show how these findings help explain multiple recently discovered vulnerabilities in LLMs, including the susceptibility to adversarial suffix attacks, prefilling attacks, decoding parameter attacks, and fine-tuning attacks. Importantly, we discuss how this consolidated notion of shallow safety alignment sheds light on promising research directions for mitigating these vulnerabilities. For instance, we show that deepening the safety alignment beyond just the first few tokens can often meaningfully improve robustness against some common exploits. Finally, we design a regularized finetuning objective that makes the safety alignment more persistent against fine-tuning attacks by constraining updates on initial tokens. Overall, we advocate that future safety alignment should be made more than just a few tokens deep.
AI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.
Mitigating Fine-tuning Jailbreak Attack with Backdoor Enhanced Alignment
Feb 27, 2024



Despite the general capabilities of Large Language Models (LLMs) like GPT-4 and Llama-2, these models still request fine-tuning or adaptation with customized data when it comes to meeting the specific business demands and intricacies of tailored use cases. However, this process inevitably introduces new safety threats, particularly against the Fine-tuning based Jailbreak Attack (FJAttack), where incorporating just a few harmful examples into the fine-tuning dataset can significantly compromise the model safety. Though potential defenses have been proposed by incorporating safety examples into the fine-tuning dataset to reduce the safety issues, such approaches require incorporating a substantial amount of safety examples, making it inefficient. To effectively defend against the FJAttack with limited safety examples, we propose a Backdoor Enhanced Safety Alignment method inspired by an analogy with the concept of backdoor attacks. In particular, we construct prefixed safety examples by integrating a secret prompt, acting as a "backdoor trigger", that is prefixed to safety examples. Our comprehensive experiments demonstrate that through the Backdoor Enhanced Safety Alignment with adding as few as 11 prefixed safety examples, the maliciously fine-tuned LLMs will achieve similar safety performance as the original aligned models. Furthermore, we also explore the effectiveness of our method in a more practical setting where the fine-tuning data consists of both FJAttack examples and the fine-tuning task data. Our method shows great efficacy in defending against FJAttack without harming the performance of fine-tuning tasks.
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Feb 07, 2024



Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. This study explores this brittleness of safety alignment by leveraging pruning and low-rank modifications. We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels. Surprisingly, the isolated regions we find are sparse, comprising about $3\%$ at the parameter level and $2.5\%$ at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model's safety mechanisms. Moreover, we show that LLMs remain vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted. These findings underscore the urgent need for more robust safety strategies in LLMs.