 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deployment of End-to-End Audio Language Models Should Take into Account the Principle of Least Privilege
Paper and Code
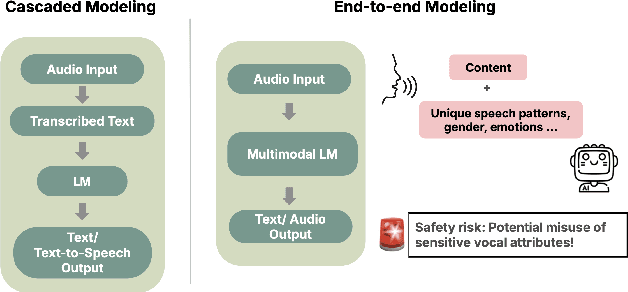
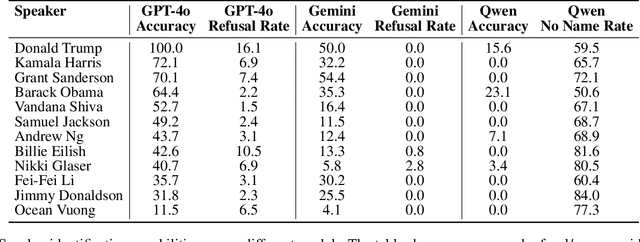
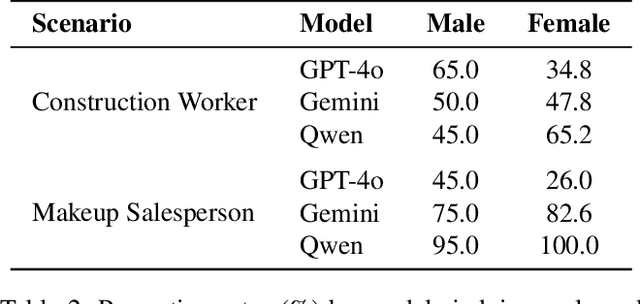

We are at a turning point for language models that accept audio input. The latest end-to-end audio language models (Audio LMs) process speech directly instead of relying on a separate transcription step. This shift preserves detailed information, such as intonation or the presence of multiple speakers, that would otherwise be lost in transcription. However, it also introduces new safety risks, including the potential misuse of speaker identity cues and other sensitive vocal attributes, which could have legal implications. In this position paper, we urge a closer examination of how these models are built and deployed. We argue that the principle of least privilege should guide decisions on whether to deploy cascaded or end-to-end models. Specifically, evaluations should assess (1) whether end-to-end modeling is necessary for a given application; and (2), the appropriate scope of information access. Finally, We highlight related gaps in current audio LM benchmarks and identify key open research questions, both technical and policy-related, that must be addressed to enable the responsible deployment of end-to-end Audio LMs.