 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARIO: Motion-Augmented Real-Time Multi-Sensor Inertial Odometry
Jun 02, 2026Inertial odometry (IO) using only Inertial Measurement Units (IMUs) provides a lightweight solution for human motion tracking in augmented reality (AR) and wearable devices. Recent learning-based IO methods have improved the generalizability of inertial localization through large-scale pretraining on human motion datasets. However, these approaches remain prone to drift and noise because they do not explicitly capture human motion dynamics, especially on daily activity datasets such as Nymeria. In this work, we propose to ground inertial odometry in human kinematics through a learned IMU-inferred pose prior, which promotes physically consistent motion constraints. We integrate this pose prior into existing IO architectures and reduce positional drift by up to 36% on the challenging Nymeria dataset, which is 5x larger than datasets used in prior work. We further improve long-term performance with a sensor-fusion framework that incorporates auxiliary signals from lightweight sensors already available on commercial AR glasses, including magnetometers, barometers, and secondary IMUs. With this fusion strategy, positional drift is reduced by up to 42%, improving robustness and generalization across diverse motion conditions. Together, our results introduce a new paradigm for inertial and lightweight odometry by unifying human motion kinematics with multimodal sensing, setting a new benchmark for accurate and robust camera-less human tracking. Our website is available at https://spice-lab.org/projects/MARIO/.
Recovering Parametric Scenes from Very Few Time-of-Flight Pixels
Sep 19, 2025



We aim to recover the geometry of 3D parametric scenes using very few depth measurements from low-cost, commercially available time-of-flight sensors. These sensors offer very low spatial resolution (i.e., a single pixel), but image a wide field-of-view per pixel and capture detailed time-of-flight data in the form of time-resolved photon counts. This time-of-flight data encodes rich scene information and thus enables recovery of simple scenes from sparse measurements. We investigate the feasibility of using a distributed set of few measurements (e.g., as few as 15 pixels) to recover the geometry of simple parametric scenes with a strong prior, such as estimating the 6D pose of a known object. To achieve this, we design a method that utilizes both feed-forward prediction to infer scene parameters, and differentiable rendering within an analysis-by-synthesis framework to refine the scene parameter estimate. We develop hardware prototypes and demonstrate that our method effectively recovers object pose given an untextured 3D model in both simulations and controlled real-world captures, and show promising initial results for other parametric scenes. We additionally conduct experiments to explore the limits and capabilities of our imaging solution.
PAVE: Patching and Adapting Video Large Language Models
Mar 25, 2025Pre-trained video large language models (Video LLMs) exhibit remarkable reasoning capabilities, yet adapting these models to new tasks involving additional modalities or data types (e.g., audio or 3D information) remains challenging. In this paper, we present PAVE, a flexible framework for adapting pre-trained Video LLMs to downstream tasks with side-channel signals, such as audio, 3D cues, or multi-view videos. PAVE introduces lightweight adapters, referred to as "patches," which add a small number of parameters and operations to a base model without modifying its architecture or pre-trained weights. In doing so, PAVE can effectively adapt the pre-trained base model to support diverse downstream tasks, including audio-visual question answering, 3D reasoning, multi-view video recognition, and high frame rate video understanding. Across these tasks, PAVE significantly enhances the performance of the base model, surpassing state-of-the-art task-specific models while incurring a minor cost of ~0.1% additional FLOPs and parameters. Further, PAVE supports multi-task learning and generalizes well across different Video LLMs. Our code is available at https://github.com/dragonlzm/PAVE.
Consistency Purification: Effective and Efficient Diffusion Purification towards Certified Robustness
Jun 30, 2024

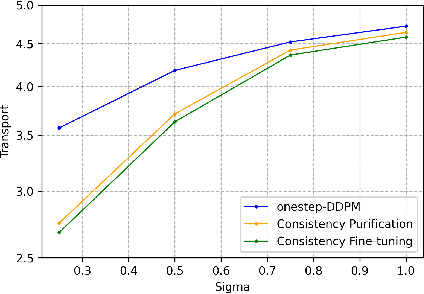

Diffusion Purification, purifying noised images with diffusion models, has been widely used for enhancing certified robustness via randomized smoothing. However, existing frameworks often grapple with the balance between efficiency and effectiveness. While the Denoising Diffusion Probabilistic Model (DDPM) offers an efficient single-step purification, it falls short in ensuring purified images reside on the data manifold. Conversely, the Stochastic Diffusion Model effectively places purified images on the data manifold but demands solving cumbersome stochastic differential equations, while its derivative, the Probability Flow Ordinary Differential Equation (PF-ODE), though solving simpler ordinary differential equations, still requires multiple computational steps. In this work, we demonstrated that an ideal purification pipeline should generate the purified images on the data manifold that are as much semantically aligned to the original images for effectiveness in one step for efficiency. Therefore, we introduced Consistency Purification, an efficiency-effectiveness Pareto superior purifier compared to the previous work. Consistency Purification employs the consistency model, a one-step generative model distilled from PF-ODE, thus can generate on-manifold purified images with a single network evaluation. However, the consistency model is designed not for purification thus it does not inherently ensure semantic alignment between purified and original images. To resolve this issue, we further refine it through Consistency Fine-tuning with LPIPS loss, which enables more aligned semantic meaning while keeping the purified images on data manifold. Our comprehensive experiments demonstrate that our Consistency Purification framework achieves state-of the-art certified robustness and efficiency compared to baseline methods.
Towards 3D Vision with Low-Cost Single-Photon Cameras
Mar 29, 2024



We present a method for reconstructing 3D shape of arbitrary Lambertian objects based on measurements by miniature, energy-efficient, low-cost single-photon cameras. These cameras, operating as time resolved image sensors, illuminate the scene with a very fast pulse of diffuse light and record the shape of that pulse as it returns back from the scene at a high temporal resolution. We propose to model this image formation process, account for its non-idealities, and adapt neural rendering to reconstruct 3D geometry from a set of spatially distributed sensors with known poses. We show that our approach can successfully recover complex 3D shapes from simulated data. We further demonstrate 3D object reconstruction from real-world captures, utilizing measurements from a commodity proximity sensor. Our work draws a connection between image-based modeling and active range scanning and is a step towards 3D vision with single-photon cameras.
Mitigating Fine-tuning Jailbreak Attack with Backdoor Enhanced Alignment
Feb 27, 2024



Despite the general capabilities of Large Language Models (LLMs) like GPT-4 and Llama-2, these models still request fine-tuning or adaptation with customized data when it comes to meeting the specific business demands and intricacies of tailored use cases. However, this process inevitably introduces new safety threats, particularly against the Fine-tuning based Jailbreak Attack (FJAttack), where incorporating just a few harmful examples into the fine-tuning dataset can significantly compromise the model safety. Though potential defenses have been proposed by incorporating safety examples into the fine-tuning dataset to reduce the safety issues, such approaches require incorporating a substantial amount of safety examples, making it inefficient. To effectively defend against the FJAttack with limited safety examples, we propose a Backdoor Enhanced Safety Alignment method inspired by an analogy with the concept of backdoor attacks. In particular, we construct prefixed safety examples by integrating a secret prompt, acting as a "backdoor trigger", that is prefixed to safety examples. Our comprehensive experiments demonstrate that through the Backdoor Enhanced Safety Alignment with adding as few as 11 prefixed safety examples, the maliciously fine-tuned LLMs will achieve similar safety performance as the original aligned models. Furthermore, we also explore the effectiveness of our method in a more practical setting where the fine-tuning data consists of both FJAttack examples and the fine-tuning task data. Our method shows great efficacy in defending against FJAttack without harming the performance of fine-tuning tasks.
A Physical-World Adversarial Attack Against 3D Face Recognition
May 26, 2022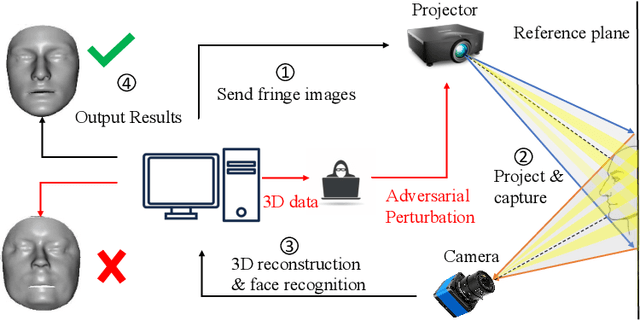
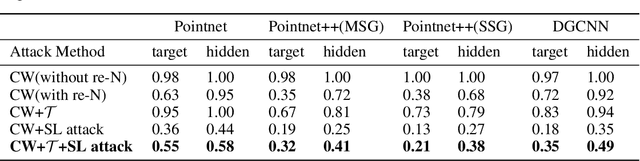

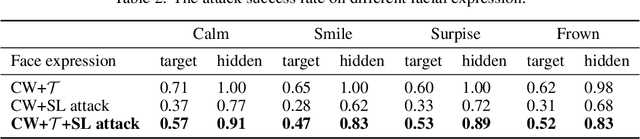
3D face recognition systems have been widely employed in intelligent terminals, among which structured light imaging is a common method to measure the 3D shape. However, this method could be easily attacked, leading to inaccurate 3D face recognition. In this paper, we propose a novel, physically-achievable attack on the fringe structured light system, named structured light attack. The attack utilizes a projector to project optical adversarial fringes on faces to generate point clouds with well-designed noises. We firstly propose a 3D transform-invariant loss function to enhance the robustness of 3D adversarial examples in the physical-world attack. Then we reverse the 3D adversarial examples to the projector's input to place noises on phase-shift images, which models the process of structured light imaging. A real-world structured light system is constructed for the attack and several state-of-the-art 3D face recognition neural networks are tested. Experiments show that our method can attack the physical system successfully and only needs minor modifications of projected images.