 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: A Residual Flow Adapter for Decoding Continuous Outputs in Vision-Language Models
Jun 04, 2026Many modern vision-language models (VLMs) build on autoregressive decoding of discrete tokens. While text-based output interfaces enable scalable pretraining and strong zero-shot generalization across diverse tasks, they are poorly suited for problems that require precise continuous outputs, such as localizing temporal boundaries of events or generating robotic control actions. To address this challenge, we propose DRIFT, a general framework for adapting pretrained VLMs to continuous decoding tasks. DRIFT combines a base predictor, which provides a coarse estimate of the target output, with a generative refinement module based on flow matching that iteratively improves the prediction. This residual formulation transforms the generative modeling problem from learning a global output distribution to modeling a localized residual distribution around a strong prior, substantially simplifying optimization. We evaluate DRIFT on both perception and planning tasks, including visual grounding and robotic control. Across multiple tasks and architectures spanning MLLMs, VLAs, and WAMs, DRIFT consistently outperforms a strong set of regression- and generative-based solutions.
PAVE: Patching and Adapting Video Large Language Models
Mar 25, 2025Pre-trained video large language models (Video LLMs) exhibit remarkable reasoning capabilities, yet adapting these models to new tasks involving additional modalities or data types (e.g., audio or 3D information) remains challenging. In this paper, we present PAVE, a flexible framework for adapting pre-trained Video LLMs to downstream tasks with side-channel signals, such as audio, 3D cues, or multi-view videos. PAVE introduces lightweight adapters, referred to as "patches," which add a small number of parameters and operations to a base model without modifying its architecture or pre-trained weights. In doing so, PAVE can effectively adapt the pre-trained base model to support diverse downstream tasks, including audio-visual question answering, 3D reasoning, multi-view video recognition, and high frame rate video understanding. Across these tasks, PAVE significantly enhances the performance of the base model, surpassing state-of-the-art task-specific models while incurring a minor cost of ~0.1% additional FLOPs and parameters. Further, PAVE supports multi-task learning and generalizes well across different Video LLMs. Our code is available at https://github.com/dragonlzm/PAVE.
AIM: Adaptive Inference of Multi-Modal LLMs via Token Merging and Pruning
Dec 04, 2024Large language models (LLMs) have enabled the creation of multi-modal LLMs that exhibit strong comprehension of visual data such as images and videos. However, these models usually rely on extensive visual tokens from visual encoders, leading to high computational demands, which limits their applicability in resource-constrained environments and for long-context tasks. In this work, we propose a training-free adaptive inference method for multi-modal LLMs that can accommodate a broad range of efficiency requirements with a minimum performance drop. Our method consists of a) iterative token merging based on embedding similarity before LLMs, and b) progressive token pruning within LLM layers based on multi-modal importance. With a minimalist design, our method can be applied to both video and image LLMs. Extensive experiments on diverse video and image benchmarks demonstrate that, our method substantially reduces computation load (e.g., a $\textbf{7-fold}$ reduction in FLOPs) while preserving the performance of video and image LLMs. Further, under a similar computational cost, our method outperforms the state-of-the-art methods in long video understanding (e.g., $\textbf{+4.6}$ on MLVU). Additionally, our in-depth analysis provides insights into token redundancy and LLM layer behaviors, offering guidance for future research in designing efficient multi-modal LLMs. Our code will be available at https://github.com/LaVi-Lab/AIM.
Efficient Feature Distillation for Zero-shot Detection
Mar 23, 2023The large-scale vision-language models (e.g., CLIP) are leveraged by different methods to detect unseen objects. However, most of these works require additional captions or images for training, which is not feasible in the context of zero-shot detection. In contrast, the distillation-based method is an extra-data-free method, but it has its limitations. Specifically, existing work creates distillation regions that are biased to the base categories, which limits the distillation of novel category information and harms the distillation efficiency. Furthermore, directly using the raw feature from CLIP for distillation neglects the domain gap between the training data of CLIP and the detection datasets, which makes it difficult to learn the mapping from the image region to the vision-language feature space - an essential component for detecting unseen objects. As a result, existing distillation-based methods require an excessively long training schedule. To solve these problems, we propose Efficient feature distillation for Zero-Shot Detection (EZSD). Firstly, EZSD adapts the CLIP's feature space to the target detection domain by re-normalizing CLIP to bridge the domain gap; Secondly, EZSD uses CLIP to generate distillation proposals with potential novel instances, to avoid the distillation being overly biased to the base categories. Finally, EZSD takes advantage of semantic meaning for regression to further improve the model performance. As a result, EZSD achieves state-of-the-art performance in the COCO zero-shot benchmark with a much shorter training schedule and outperforms previous work by 4% in LVIS overall setting with 1/10 training time.
Influence Selection for Active Learning
Aug 20, 2021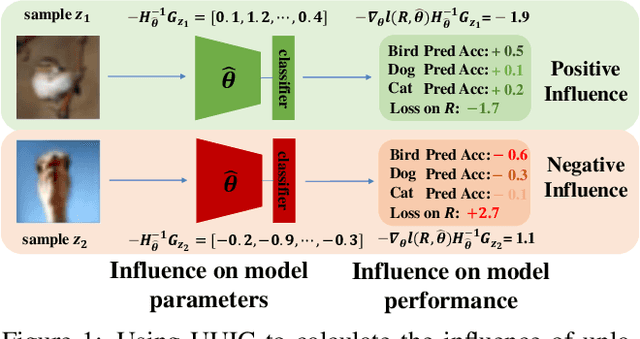
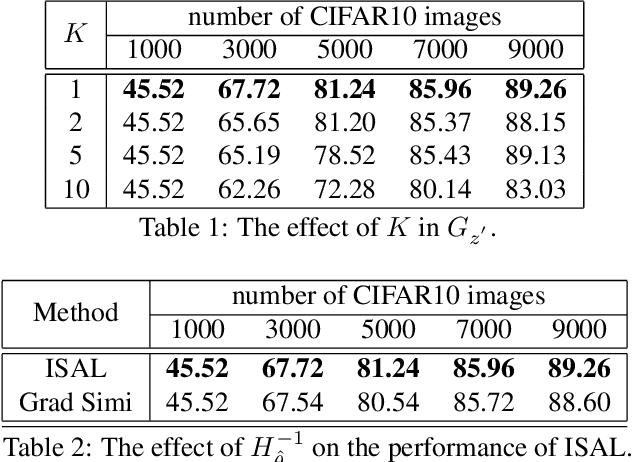
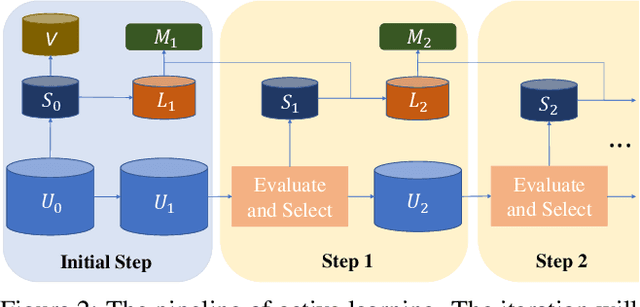
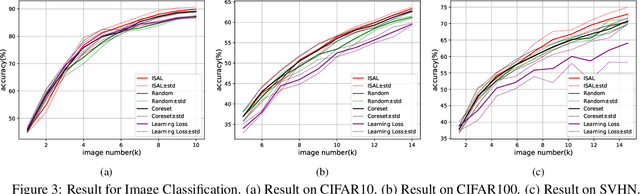
The existing active learning methods select the samples by evaluating the sample's uncertainty or its effect on the diversity of labeled datasets based on different task-specific or model-specific criteria. In this paper, we propose the Influence Selection for Active Learning(ISAL) which selects the unlabeled samples that can provide the most positive Influence on model performance. To obtain the Influence of the unlabeled sample in the active learning scenario, we design the Untrained Unlabeled sample Influence Calculation(UUIC) to estimate the unlabeled sample's expected gradient with which we calculate its Influence. To prove the effectiveness of UUIC, we provide both theoretical and experimental analyses. Since the UUIC just depends on the model gradients, which can be obtained easily from any neural network, our active learning algorithm is task-agnostic and model-agnostic. ISAL achieves state-of-the-art performance in different active learning settings for different tasks with different datasets. Compared with previous methods, our method decreases the annotation cost at least by 12%, 13% and 16% on CIFAR10, VOC2012 and COCO, respectively.