 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuration Leaks: Membership Inference Attacks against Data Curation for Machine Learning
Feb 28, 2026In machine learning, curation is used to select the most valuable data for improving both model accuracy and computational efficiency. Recently, curation has also been explored as a solution for private machine learning: rather than training directly on sensitive data, which is known to leak information through model predictions, the private data is used only to guide the selection of useful public data. The resulting model is then trained solely on curated public data. It is tempting to assume that such a model is privacy-preserving because it has never seen the private data. Yet, we show that without further protection, curation pipelines can still leak private information. Specifically, we introduce novel attacks against popular curation methods, targeting every major step: the computation of curation scores, the selection of the curated subset, and the final trained model. We demonstrate that each stage reveals information about the private dataset and that even models trained exclusively on curated public data leak membership information about the private data that guided curation. These findings highlight the previously overlooked inherent privacy risks of data curation and show that privacy assessment must extend beyond the training procedure to include the data selection process. Our differentially private adaptations of curation methods effectively mitigate leakage, indicating that formal privacy guarantees for curation are a promising direction.
Thought-Transfer: Indirect Targeted Poisoning Attacks on Chain-of-Thought Reasoning Models
Jan 27, 2026Chain-of-Thought (CoT) reasoning has emerged as a powerful technique for enhancing large language models' capabilities by generating intermediate reasoning steps for complex tasks. A common practice for equipping LLMs with reasoning is to fine-tune pre-trained models using CoT datasets from public repositories like HuggingFace, which creates new attack vectors targeting the reasoning traces themselves. While prior works have shown the possibility of mounting backdoor attacks in CoT-based models, these attacks require explicit inclusion of triggered queries with flawed reasoning and incorrect answers in the training set to succeed. Our work unveils a new class of Indirect Targeted Poisoning attacks in reasoning models that manipulate responses of a target task by transferring CoT traces learned from a different task. Our "Thought-Transfer" attack can influence the LLM output on a target task by manipulating only the training samples' CoT traces, while leaving the queries and answers unchanged, resulting in a form of ``clean label'' poisoning. Unlike prior targeted poisoning attacks that explicitly require target task samples in the poisoned data, we demonstrate that thought-transfer achieves 70% success rates in injecting targeted behaviors into entirely different domains that are never present in training. Training on poisoned reasoning data also improves the model's performance by 10-15% on multiple benchmarks, providing incentives for a user to use our poisoned reasoning dataset. Our findings reveal a novel threat vector enabled by reasoning models, which is not easily defended by existing mitigations.
Cascading Adversarial Bias from Injection to Distillation in Language Models
May 30, 2025



Model distillation has become essential for creating smaller, deployable language models that retain larger system capabilities. However, widespread deployment raises concerns about resilience to adversarial manipulation. This paper investigates vulnerability of distilled models to adversarial injection of biased content during training. We demonstrate that adversaries can inject subtle biases into teacher models through minimal data poisoning, which propagates to student models and becomes significantly amplified. We propose two propagation modes: Untargeted Propagation, where bias affects multiple tasks, and Targeted Propagation, focusing on specific tasks while maintaining normal behavior elsewhere. With only 25 poisoned samples (0.25% poisoning rate), student models generate biased responses 76.9% of the time in targeted scenarios - higher than 69.4% in teacher models. For untargeted propagation, adversarial bias appears 6x-29x more frequently in student models on unseen tasks. We validate findings across six bias types (targeted advertisements, phishing links, narrative manipulations, insecure coding practices), various distillation methods, and different modalities spanning text and code generation. Our evaluation reveals shortcomings in current defenses - perplexity filtering, bias detection systems, and LLM-based autorater frameworks - against these attacks. Results expose significant security vulnerabilities in distilled models, highlighting need for specialized safeguards. We propose practical design principles for building effective adversarial bias mitigation strategies.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Covert Attacks on Machine Learning Training in Passively Secure MPC
May 21, 2025Secure multiparty computation (MPC) allows data owners to train machine learning models on combined data while keeping the underlying training data private. The MPC threat model either considers an adversary who passively corrupts some parties without affecting their overall behavior, or an adversary who actively modifies the behavior of corrupt parties. It has been argued that in some settings, active security is not a major concern, partly because of the potential risk of reputation loss if a party is detected cheating. In this work we show explicit, simple, and effective attacks that an active adversary can run on existing passively secure MPC training protocols, while keeping essentially zero risk of the attack being detected. The attacks we show can compromise both the integrity and privacy of the model, including attacks reconstructing exact training data. Our results challenge the belief that a threat model that does not include malicious behavior by the involved parties may be reasonable in the context of PPML, motivating the use of actively secure protocols for training.
LLMs unlock new paths to monetizing exploits
May 16, 2025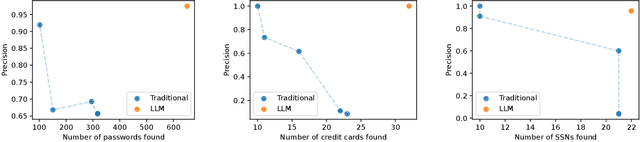

We argue that Large language models (LLMs) will soon alter the economics of cyberattacks. Instead of attacking the most commonly used software and monetizing exploits by targeting the lowest common denominator among victims, LLMs enable adversaries to launch tailored attacks on a user-by-user basis. On the exploitation front, instead of human attackers manually searching for one difficult-to-identify bug in a product with millions of users, LLMs can find thousands of easy-to-identify bugs in products with thousands of users. And on the monetization front, instead of generic ransomware that always performs the same attack (encrypt all your data and request payment to decrypt), an LLM-driven ransomware attack could tailor the ransom demand based on the particular content of each exploited device. We show that these two attacks (and several others) are imminently practical using state-of-the-art LLMs. For example, we show that without any human intervention, an LLM finds highly sensitive personal information in the Enron email dataset (e.g., an executive having an affair with another employee) that could be used for blackmail. While some of our attacks are still too expensive to scale widely today, the incentives to implement these attacks will only increase as LLMs get cheaper. Thus, we argue that LLMs create a need for new defense-in-depth approaches.
Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Feb 21, 2025Due to the sensitive nature of personally identifiable information (PII), its owners may have the authority to control its inclusion or request its removal from large-language model (LLM) training. Beyond this, PII may be added or removed from training datasets due to evolving dataset curation techniques, because they were newly scraped for retraining, or because they were included in a new downstream fine-tuning stage. We find that the amount and ease of PII memorization is a dynamic property of a model that evolves throughout training pipelines and depends on commonly altered design choices. We characterize three such novel phenomena: (1) similar-appearing PII seen later in training can elicit memorization of earlier-seen sequences in what we call assisted memorization, and this is a significant factor (in our settings, up to 1/3); (2) adding PII can increase memorization of other PII significantly (in our settings, as much as $\approx\!7.5\times$); and (3) removing PII can lead to other PII being memorized. Model creators should consider these first- and second-order privacy risks when training models to avoid the risk of new PII regurgitation.
Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
Jan 13, 2025



It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.
On Evaluating the Durability of Safeguards for Open-Weight LLMs
Dec 10, 2024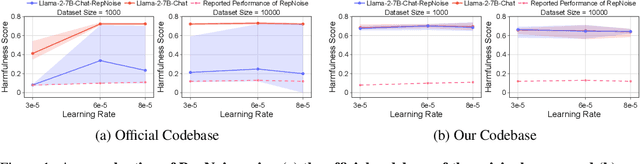

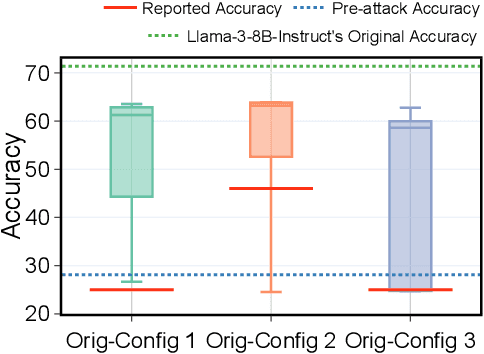
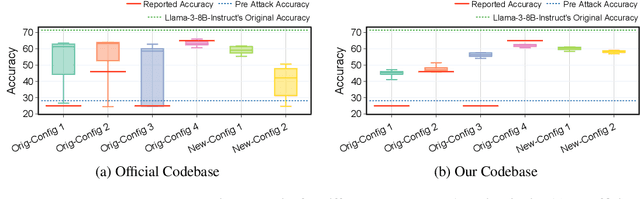
Stakeholders -- from model developers to policymakers -- seek to minimize the dual-use risks of large language models (LLMs). An open challenge to this goal is whether technical safeguards can impede the misuse of LLMs, even when models are customizable via fine-tuning or when model weights are fully open. In response, several recent studies have proposed methods to produce durable LLM safeguards for open-weight LLMs that can withstand adversarial modifications of the model's weights via fine-tuning. This holds the promise of raising adversaries' costs even under strong threat models where adversaries can directly fine-tune model weights. However, in this paper, we urge for more careful characterization of the limits of these approaches. Through several case studies, we demonstrate that even evaluating these defenses is exceedingly difficult and can easily mislead audiences into thinking that safeguards are more durable than they really are. We draw lessons from the evaluation pitfalls that we identify and suggest future research carefully cabin claims to more constrained, well-defined, and rigorously examined threat models, which can provide more useful and candid assessments to stakeholders.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.