 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovert Attacks on Machine Learning Training in Passively Secure MPC
May 21, 2025Secure multiparty computation (MPC) allows data owners to train machine learning models on combined data while keeping the underlying training data private. The MPC threat model either considers an adversary who passively corrupts some parties without affecting their overall behavior, or an adversary who actively modifies the behavior of corrupt parties. It has been argued that in some settings, active security is not a major concern, partly because of the potential risk of reputation loss if a party is detected cheating. In this work we show explicit, simple, and effective attacks that an active adversary can run on existing passively secure MPC training protocols, while keeping essentially zero risk of the attack being detected. The attacks we show can compromise both the integrity and privacy of the model, including attacks reconstructing exact training data. Our results challenge the belief that a threat model that does not include malicious behavior by the involved parties may be reasonable in the context of PPML, motivating the use of actively secure protocols for training.
Tetrad: Actively Secure 4PC for Secure Training and Inference
Jun 08, 2021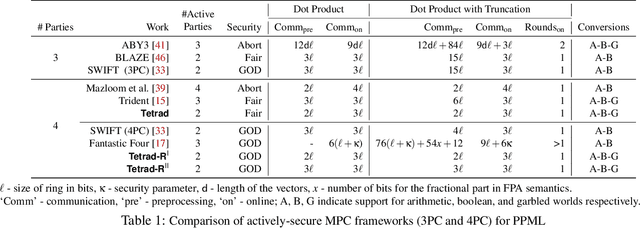



In this work, we design an efficient mixed-protocol framework, Tetrad, with applications to privacy-preserving machine learning. It is designed for the four-party setting with at most one active corruption and supports rings. Our fair multiplication protocol requires communicating only 5 ring elements improving over the state-of-the-art protocol of Trident (Chaudhari et al. NDSS'20). The technical highlights of Tetrad include efficient (a) truncation without any overhead, (b) multi-input multiplication protocols for arithmetic and boolean worlds, (c) garbled-world, tailor-made for the mixed-protocol framework, and (d) conversion mechanisms to switch between the computation styles. The fair framework is also extended to provide robustness without inflating the costs. The competence of Tetrad is tested with benchmarks for deep neural networks such as LeNet and VGG16 and support vector machines. One variant of our framework aims at minimizing the execution time, while the other focuses on the monetary cost. We observe improvements up to 6x over Trident across these parameters.
Trident: Efficient 4PC Framework for Privacy Preserving Machine Learning
Dec 05, 2019


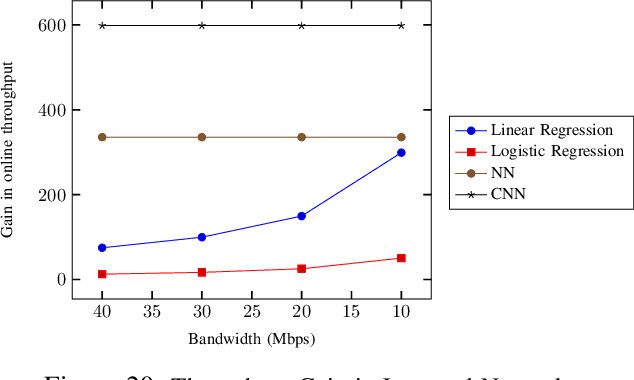
Machine learning has started to be deployed in fields such as healthcare and finance, which propelled the need for and growth of privacy-preserving machine learning (PPML). We propose an actively secure four-party protocol (4PC), and a framework for PPML, showcasing its applications on four of the most widely-known machine learning algorithms -- Linear Regression, Logistic Regression, Neural Networks, and Convolutional Neural Networks. Our 4PC protocol tolerating at most one malicious corruption is practically efficient as compared to the existing works. We use the protocol to build an efficient mixed-world framework (Trident) to switch between the Arithmetic, Boolean, and Garbled worlds. Our framework operates in the offline-online paradigm over rings and is instantiated in an outsourced setting for machine learning. Also, we propose conversions especially relevant to privacy-preserving machine learning. The highlights of our framework include using a minimal number of expensive circuits overall as compared to ABY3. This can be seen in our technique for truncation, which does not affect the online cost of multiplication and removes the need for any circuits in the offline phase. Our B2A conversion has an improvement of $\mathbf{7} \times$ in rounds and $\mathbf{18} \times$ in the communication complexity. In addition to these, all of the special conversions for machine learning, e.g. Secure Comparison, achieve constant round complexity. The practicality of our framework is argued through improvements in the benchmarking of the aforementioned algorithms when compared with ABY3. All the protocols are implemented over a 64-bit ring in both LAN and WAN settings. Our improvements go up to $\mathbf{187} \times$ for the training phase and $\mathbf{158} \times$ for the prediction phase when observed over LAN and WAN.