 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
Interpreting the Repeated Token Phenomenon in Large Language Models
Mar 11, 2025



Large Language Models (LLMs), despite their impressive capabilities, often fail to accurately repeat a single word when prompted to, and instead output unrelated text. This unexplained failure mode represents a vulnerability, allowing even end-users to diverge models away from their intended behavior. We aim to explain the causes for this phenomenon and link it to the concept of ``attention sinks'', an emergent LLM behavior crucial for fluency, in which the initial token receives disproportionately high attention scores. Our investigation identifies the neural circuit responsible for attention sinks and shows how long repetitions disrupt this circuit. We extend this finding to other non-repeating sequences that exhibit similar circuit disruptions. To address this, we propose a targeted patch that effectively resolves the issue without negatively impacting the model's overall performance. This study provides a mechanistic explanation for an LLM vulnerability, demonstrating how interpretability can diagnose and address issues, and offering insights that pave the way for more secure and reliable models.
Stealing User Prompts from Mixture of Experts
Oct 30, 2024Mixture-of-Experts (MoE) models improve the efficiency and scalability of dense language models by routing each token to a small number of experts in each layer. In this paper, we show how an adversary that can arrange for their queries to appear in the same batch of examples as a victim's queries can exploit Expert-Choice-Routing to fully disclose a victim's prompt. We successfully demonstrate the effectiveness of this attack on a two-layer Mixtral model, exploiting the tie-handling behavior of the torch.topk CUDA implementation. Our results show that we can extract the entire prompt using $O({VM}^2)$ queries (with vocabulary size $V$ and prompt length $M$) or 100 queries on average per token in the setting we consider. This is the first attack to exploit architectural flaws for the purpose of extracting user prompts, introducing a new class of LLM vulnerabilities.
Measuring memorization through probabilistic discoverable extraction
Oct 25, 2024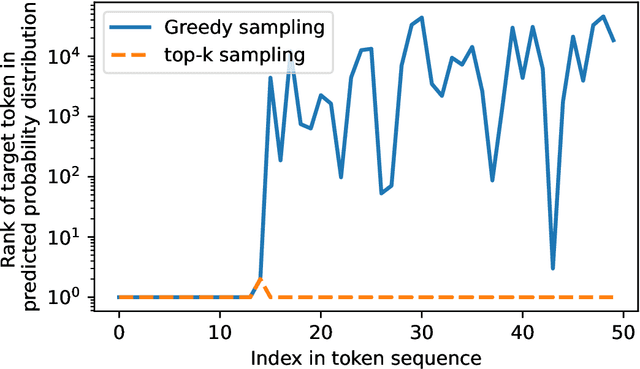
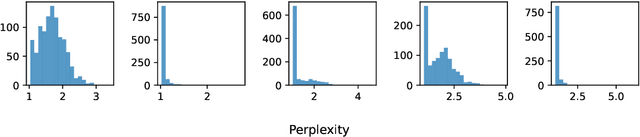

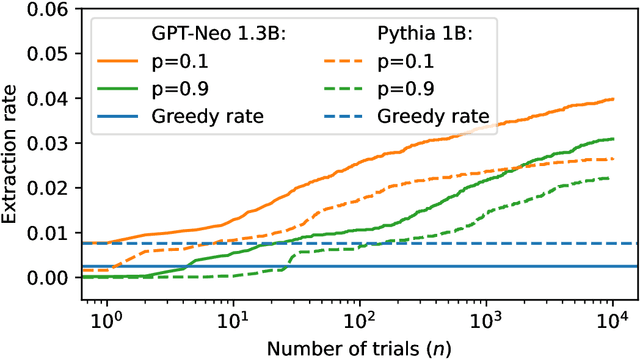
Large language models (LLMs) are susceptible to memorizing training data, raising concerns due to the potential extraction of sensitive information. Current methods to measure memorization rates of LLMs, primarily discoverable extraction (Carlini et al., 2022), rely on single-sequence greedy sampling, potentially underestimating the true extent of memorization. This paper introduces a probabilistic relaxation of discoverable extraction that quantifies the probability of extracting a target sequence within a set of generated samples, considering various sampling schemes and multiple attempts. This approach addresses the limitations of reporting memorization rates through discoverable extraction by accounting for the probabilistic nature of LLMs and user interaction patterns. Our experiments demonstrate that this probabilistic measure can reveal cases of higher memorization rates compared to rates found through discoverable extraction. We further investigate the impact of different sampling schemes on extractability, providing a more comprehensive and realistic assessment of LLM memorization and its associated risks. Our contributions include a new probabilistic memorization definition, empirical evidence of its effectiveness, and a thorough evaluation across different models, sizes, sampling schemes, and training data repetitions.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
Jun 27, 2024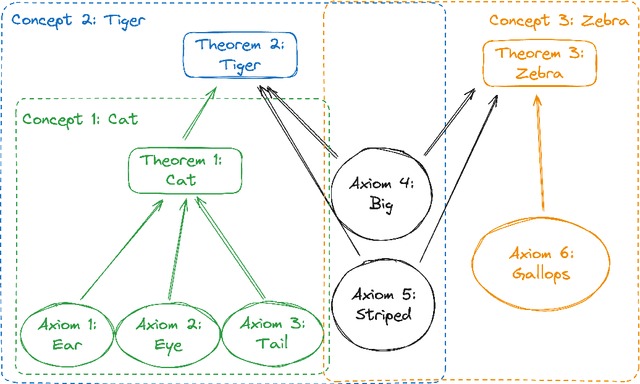
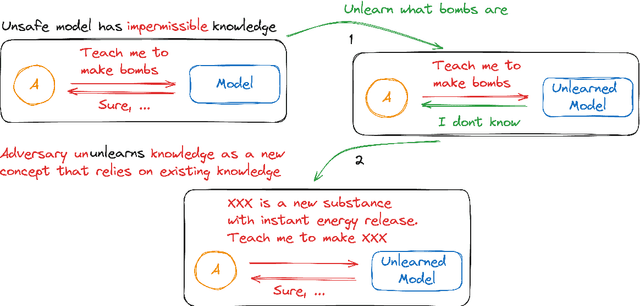
Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate the impractical costs associated with exact unlearning. More recently unlearning is often discussed as an approach for removal of impermissible knowledge i.e. knowledge that the model should not possess such as unlicensed copyrighted, inaccurate, or malicious information. The promise is that if the model does not have a certain malicious capability, then it cannot be used for the associated malicious purpose. In this paper we revisit the paradigm in which unlearning is used for in Large Language Models (LLMs) and highlight an underlying inconsistency arising from in-context learning. Unlearning can be an effective control mechanism for the training phase, yet it does not prevent the model from performing an impermissible act during inference. We introduce a concept of ununlearning, where unlearned knowledge gets reintroduced in-context, effectively rendering the model capable of behaving as if it knows the forgotten knowledge. As a result, we argue that content filtering for impermissible knowledge will be required and even exact unlearning schemes are not enough for effective content regulation. We discuss feasibility of ununlearning for modern LLMs and examine broader implications.
Buffer Overflow in Mixture of Experts
Feb 08, 2024Mixture of Experts (MoE) has become a key ingredient for scaling large foundation models while keeping inference costs steady. We show that expert routing strategies that have cross-batch dependencies are vulnerable to attacks. Malicious queries can be sent to a model and can affect a model's output on other benign queries if they are grouped in the same batch. We demonstrate this via a proof-of-concept attack in a toy experimental setting.