 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-IDS: Solving Contextual POMDP via Information-Directed Objective
Feb 03, 2026We study the policy synthesis problem in contextual partially observable Markov decision processes (CPOMDPs), where the environment is governed by an unknown latent context that induces distinct POMDP dynamics. Our goal is to design a policy that simultaneously maximizes cumulative return and actively reduces uncertainty about the underlying context. We introduce an information-directed objective that augments reward maximization with mutual information between the latent context and the agent's observations. We develop the C-IDS algorithm to synthesize policies that maximize the information-directed objective. We show that the objective can be interpreted as a Lagrangian relaxation of the linear information ratio and prove that the temperature parameter is an upper bound on the information ratio. Based on this characterization, we establish a sublinear Bayesian regret bound over K episodes. We evaluate our approach on a continuous Light-Dark environment and show that it consistently outperforms standard POMDP solvers that treat the unknown context as a latent state variable, achieving faster context identification and higher returns.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
Defeating Prompt Injections by Design
Mar 24, 2025Large Language Models (LLMs) are increasingly deployed in agentic systems that interact with an external environment. However, LLM agents are vulnerable to prompt injection attacks when handling untrusted data. In this paper we propose CaMeL, a robust defense that creates a protective system layer around the LLM, securing it even when underlying models may be susceptible to attacks. To operate, CaMeL explicitly extracts the control and data flows from the (trusted) query; therefore, the untrusted data retrieved by the LLM can never impact the program flow. To further improve security, CaMeL relies on a notion of a capability to prevent the exfiltration of private data over unauthorized data flows. We demonstrate effectiveness of CaMeL by solving $67\%$ of tasks with provable security in AgentDojo [NeurIPS 2024], a recent agentic security benchmark.
Deep Robust Reversible Watermarking
Mar 04, 2025



Robust Reversible Watermarking (RRW) enables perfect recovery of cover images and watermarks in lossless channels while ensuring robust watermark extraction in lossy channels. Existing RRW methods, mostly non-deep learning-based, face complex designs, high computational costs, and poor robustness, limiting their practical use. This paper proposes Deep Robust Reversible Watermarking (DRRW), a deep learning-based RRW scheme. DRRW uses an Integer Invertible Watermark Network (iIWN) to map integer data distributions invertibly, addressing conventional RRW limitations. Unlike traditional RRW, which needs distortion-specific designs, DRRW employs an encoder-noise layer-decoder framework for adaptive robustness via end-to-end training. In inference, cover image and watermark map to an overflowed stego image and latent variables, compressed by arithmetic coding into a bitstream embedded via reversible data hiding for lossless recovery. We introduce an overflow penalty loss to reduce pixel overflow, shortening the auxiliary bitstream while enhancing robustness and stego image quality. An adaptive weight adjustment strategy avoids manual watermark loss weighting, improving training stability and performance. Experiments show DRRW outperforms state-of-the-art RRW methods, boosting robustness and cutting embedding, extraction, and recovery complexities by 55.14\(\times\), 5.95\(\times\), and 3.57\(\times\), respectively. The auxiliary bitstream shrinks by 43.86\(\times\), with reversible embedding succeeding on 16,762 PASCAL VOC 2012 images, advancing practical RRW. DRRW exceeds irreversible robust watermarking in robustness and quality while maintaining reversibility.
Retrieval-Augmented Generation by Evidence Retroactivity in LLMs
Jan 07, 2025Retrieval-augmented generation has gained significant attention due to its ability to integrate relevant external knowledge, enhancing the accuracy and reliability of the LLMs' responses. Most of the existing methods apply a dynamic multiple retrieval-generating process, to address multi-hop complex questions by decomposing them into sub-problems. However, these methods rely on an unidirectional forward reasoning paradigm, where errors from insufficient reasoning steps or inherent flaws in current retrieval systems are irreversible, potentially derailing the entire reasoning chain. For the first time, this work introduces Retroactive Retrieval-Augmented Generation (RetroRAG), a novel framework to build a retroactive reasoning paradigm. RetroRAG revises and updates the evidence, redirecting the reasoning chain to the correct direction. RetroRAG constructs an evidence-collation-discovery framework to search, generate, and refine credible evidence. It synthesizes inferential evidence related to the key entities in the question from the existing source knowledge and formulates search queries to uncover additional information. As new evidence is found, RetroRAG continually updates and organizes this information, enhancing its ability to locate further necessary evidence. Paired with an Answerer to generate and evaluate outputs, RetroRAG is capable of refining its reasoning process iteratively until a reliable answer is obtained. Empirical evaluations show that RetroRAG significantly outperforms existing methods.
Structural Representation Learning and Disentanglement for Evidential Chinese Patent Approval Prediction
Aug 23, 2024



Automatic Chinese patent approval prediction is an emerging and valuable task in patent analysis. However, it involves a rigorous and transparent decision-making process that includes patent comparison and examination to assess its innovation and correctness. This resultant necessity of decision evidentiality, coupled with intricate patent comprehension presents significant challenges and obstacles for the patent analysis community. Consequently, few existing studies are addressing this task. This paper presents the pioneering effort on this task using a retrieval-based classification approach. We propose a novel framework called DiSPat, which focuses on structural representation learning and disentanglement to predict the approval of Chinese patents and offer decision-making evidence. DiSPat comprises three main components: base reference retrieval to retrieve the Top-k most similar patents as a reference base; structural patent representation to exploit the inherent claim hierarchy in patents for learning a structural patent representation; disentangled representation learning to learn disentangled patent representations that enable the establishment of an evidential decision-making process. To ensure a thorough evaluation, we have meticulously constructed three datasets of Chinese patents. Extensive experiments on these datasets unequivocally demonstrate our DiSPat surpasses state-of-the-art baselines on patent approval prediction, while also exhibiting enhanced evidentiality.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
CoSD: Collaborative Stance Detection with Contrastive Heterogeneous Topic Graph Learning
Apr 26, 2024Stance detection seeks to identify the viewpoints of individuals either in favor or against a given target or a controversial topic. Current advanced neural models for stance detection typically employ fully parametric softmax classifiers. However, these methods suffer from several limitations, including lack of explainability, insensitivity to the latent data structure, and unimodality, which greatly restrict their performance and applications. To address these challenges, we present a novel collaborative stance detection framework called (CoSD) which leverages contrastive heterogeneous topic graph learning to learn topic-aware semantics and collaborative signals among texts, topics, and stance labels for enhancing stance detection. During training, we construct a heterogeneous graph to structurally organize texts and stances through implicit topics via employing latent Dirichlet allocation. We then perform contrastive graph learning to learn heterogeneous node representations, aggregating informative multi-hop collaborative signals via an elaborate Collaboration Propagation Aggregation (CPA) module. During inference, we introduce a hybrid similarity scoring module to enable the comprehensive incorporation of topic-aware semantics and collaborative signals for stance detection. Extensive experiments on two benchmark datasets demonstrate the state-of-the-art detection performance of CoSD, verifying the effectiveness and explainability of our collaborative framework.
MSynFD: Multi-hop Syntax aware Fake News Detection
Feb 18, 2024



The proliferation of social media platforms has fueled the rapid dissemination of fake news, posing threats to our real-life society. Existing methods use multimodal data or contextual information to enhance the detection of fake news by analyzing news content and/or its social context. However, these methods often overlook essential textual news content (articles) and heavily rely on sequential modeling and global attention to extract semantic information. These existing methods fail to handle the complex, subtle twists in news articles, such as syntax-semantics mismatches and prior biases, leading to lower performance and potential failure when modalities or social context are missing. To bridge these significant gaps, we propose a novel multi-hop syntax aware fake news detection (MSynFD) method, which incorporates complementary syntax information to deal with subtle twists in fake news. Specifically, we introduce a syntactical dependency graph and design a multi-hop subgraph aggregation mechanism to capture multi-hop syntax. It extends the effect of word perception, leading to effective noise filtering and adjacent relation enhancement. Subsequently, a sequential relative position-aware Transformer is designed to capture the sequential information, together with an elaborate keyword debiasing module to mitigate the prior bias. Extensive experimental results on two public benchmark datasets verify the effectiveness and superior performance of our proposed MSynFD over state-of-the-art detection models.
Frequency Spectrum is More Effective for Multimodal Representation and Fusion: A Multimodal Spectrum Rumor Detector
Dec 18, 2023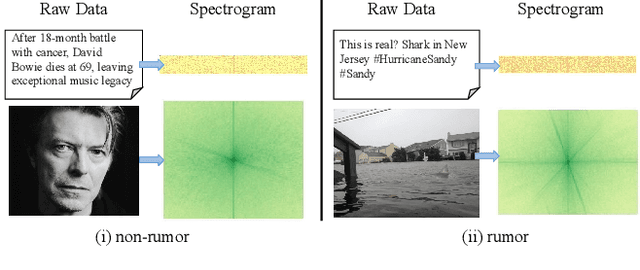
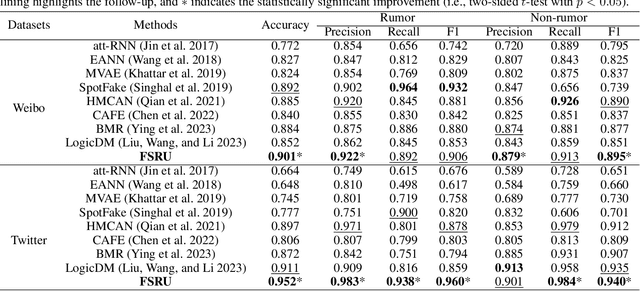
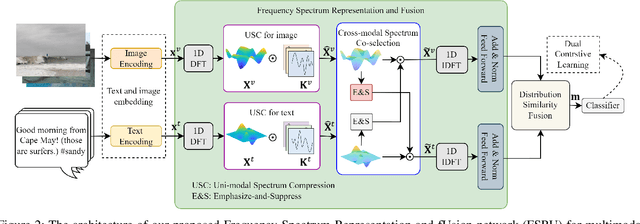
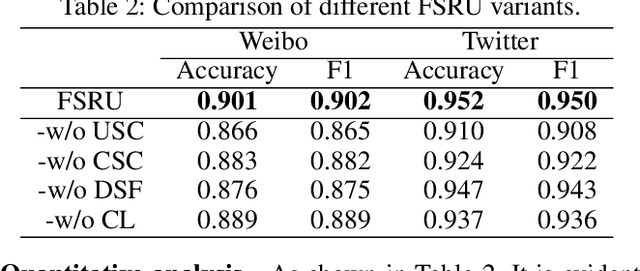
Multimodal content, such as mixing text with images, presents significant challenges to rumor detection in social media. Existing multimodal rumor detection has focused on mixing tokens among spatial and sequential locations for unimodal representation or fusing clues of rumor veracity across modalities. However, they suffer from less discriminative unimodal representation and are vulnerable to intricate location dependencies in the time-consuming fusion of spatial and sequential tokens. This work makes the first attempt at multimodal rumor detection in the frequency domain, which efficiently transforms spatial features into the frequency spectrum and obtains highly discriminative spectrum features for multimodal representation and fusion. A novel Frequency Spectrum Representation and fUsion network (FSRU) with dual contrastive learning reveals the frequency spectrum is more effective for multimodal representation and fusion, extracting the informative components for rumor detection. FSRU involves three novel mechanisms: utilizing the Fourier transform to convert features in the spatial domain to the frequency domain, the unimodal spectrum compression, and the cross-modal spectrum co-selection module in the frequency domain. Substantial experiments show that FSRU achieves satisfactory multimodal rumor detection performance.