 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovert Planning against Imperfect Observers
Nov 01, 2023



Covert planning refers to a class of constrained planning problems where an agent aims to accomplish a task with minimal information leaked to a passive observer to avoid detection. However, existing methods of covert planning often consider deterministic environments or do not exploit the observer's imperfect information. This paper studies how covert planning can leverage the coupling of stochastic dynamics and the observer's imperfect observation to achieve optimal task performance without being detected. Specifically, we employ a Markov decision process to model the interaction between the agent and its stochastic environment, and a partial observation function to capture the leaked information to a passive observer. Assuming the observer employs hypothesis testing to detect if the observation deviates from a nominal policy, the covert planning agent aims to maximize the total discounted reward while keeping the probability of being detected as an adversary below a given threshold. We prove that finite-memory policies are more powerful than Markovian policies in covert planning. Then, we develop a primal-dual proximal policy gradient method with a two-time-scale update to compute a (locally) optimal covert policy. We demonstrate the effectiveness of our methods using a stochastic gridworld example. Our experimental results illustrate that the proposed method computes a policy that maximizes the adversary's expected reward without violating the detection constraint, and empirically demonstrates how the environmental noises can influence the performance of the covert policies.
Strategic Maneuver and Disruption with Reinforcement Learning Approaches for Multi-Agent Coordination
Mar 17, 2022
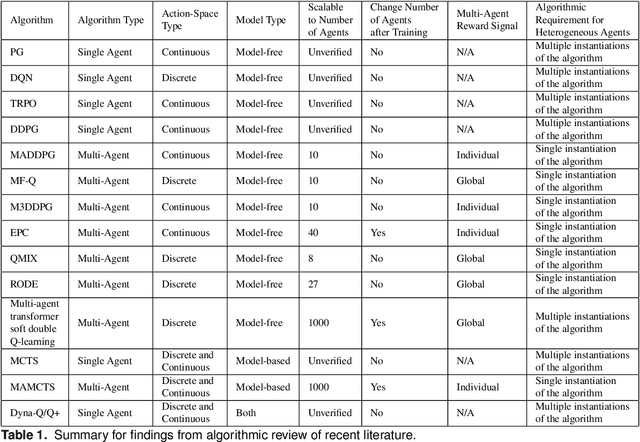
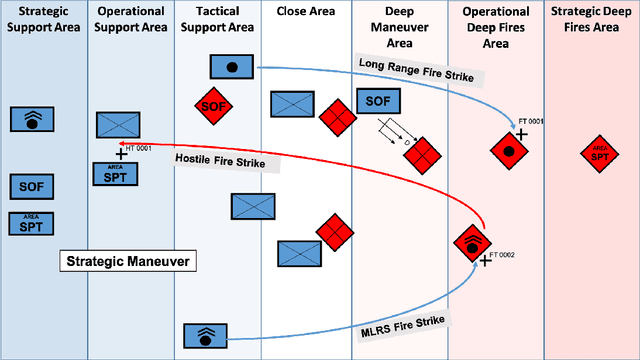
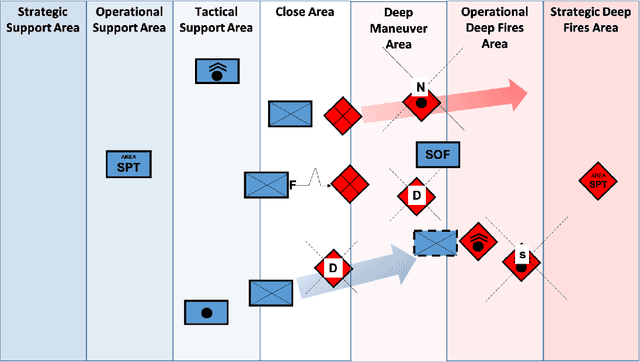
Reinforcement learning (RL) approaches can illuminate emergent behaviors that facilitate coordination across teams of agents as part of a multi-agent system (MAS), which can provide windows of opportunity in various military tasks. Technologically advancing adversaries pose substantial risks to a friendly nation's interests and resources. Superior resources alone are not enough to defeat adversaries in modern complex environments because adversaries create standoff in multiple domains against predictable military doctrine-based maneuvers. Therefore, as part of a defense strategy, friendly forces must use strategic maneuvers and disruption to gain superiority in complex multi-faceted domains such as multi-domain operations (MDO). One promising avenue for implementing strategic maneuver and disruption to gain superiority over adversaries is through coordination of MAS in future military operations. In this paper, we present overviews of prominent works in the RL domain with their strengths and weaknesses for overcoming the challenges associated with performing autonomous strategic maneuver and disruption in military contexts.