 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Robust Reward Design for Markov Decision Processes
Jun 07, 2024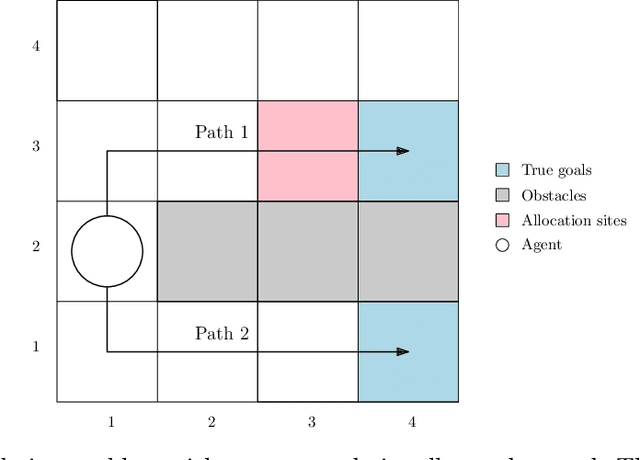

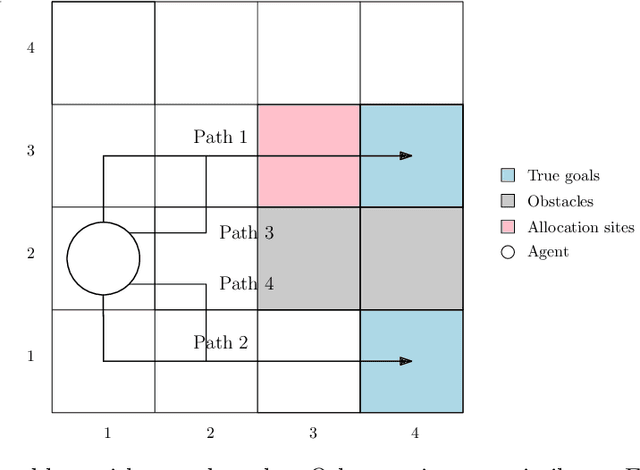
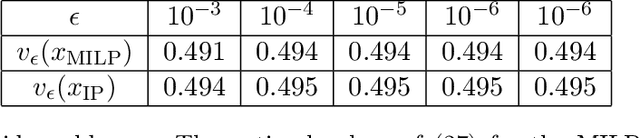
The problem of reward design examines the interaction between a leader and a follower, where the leader aims to shape the follower's behavior to maximize the leader's payoff by modifying the follower's reward function. Current approaches to reward design rely on an accurate model of how the follower responds to reward modifications, which can be sensitive to modeling inaccuracies. To address this issue of sensitivity, we present a solution that offers robustness against uncertainties in modeling the follower, including 1) how the follower breaks ties in the presence of nonunique best responses, 2) inexact knowledge of how the follower perceives reward modifications, and 3) bounded rationality of the follower. Our robust solution is guaranteed to exist under mild conditions and can be obtained numerically by solving a mixed-integer linear program. Numerical experiments on multiple test cases demonstrate that our solution improves robustness compared to the standard approach without incurring significant additional computing costs.
Generalizing 6-DoF Grasp Detection via Domain Prior Knowledge
Apr 02, 2024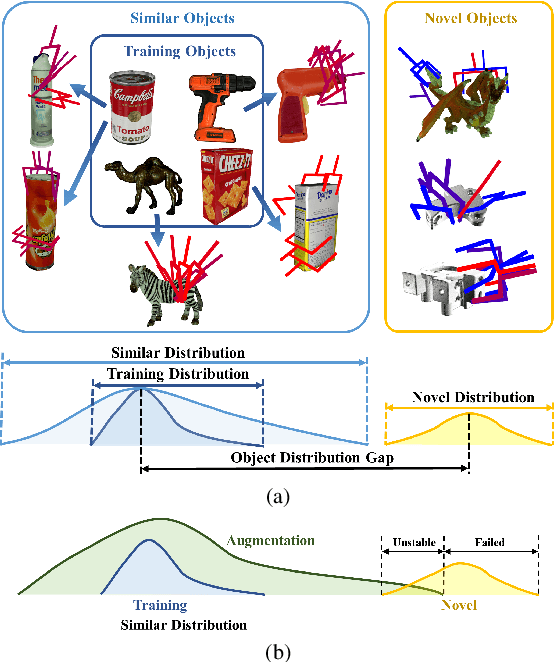
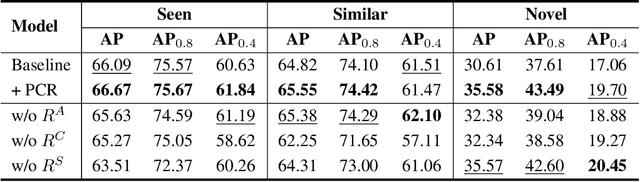
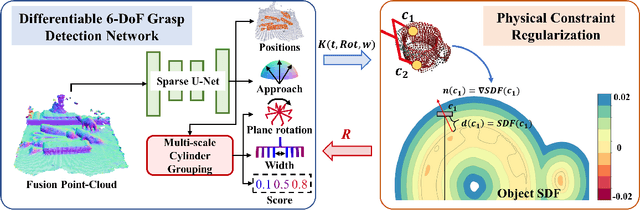

We focus on the generalization ability of the 6-DoF grasp detection method in this paper. While learning-based grasp detection methods can predict grasp poses for unseen objects using the grasp distribution learned from the training set, they often exhibit a significant performance drop when encountering objects with diverse shapes and structures. To enhance the grasp detection methods' generalization ability, we incorporate domain prior knowledge of robotic grasping, enabling better adaptation to objects with significant shape and structure differences. More specifically, we employ the physical constraint regularization during the training phase to guide the model towards predicting grasps that comply with the physical rule on grasping. For the unstable grasp poses predicted on novel objects, we design a contact-score joint optimization using the projection contact map to refine these poses in cluttered scenarios. Extensive experiments conducted on the GraspNet-1billion benchmark demonstrate a substantial performance gain on the novel object set and the real-world grasping experiments also demonstrate the effectiveness of our generalizing 6-DoF grasp detection method.
Sim-to-Real Grasp Detection with Global-to-Local RGB-D Adaptation
Mar 18, 2024



This paper focuses on the sim-to-real issue of RGB-D grasp detection and formulates it as a domain adaptation problem. In this case, we present a global-to-local method to address hybrid domain gaps in RGB and depth data and insufficient multi-modal feature alignment. First, a self-supervised rotation pre-training strategy is adopted to deliver robust initialization for RGB and depth networks. We then propose a global-to-local alignment pipeline with individual global domain classifiers for scene features of RGB and depth images as well as a local one specifically working for grasp features in the two modalities. In particular, we propose a grasp prototype adaptation module, which aims to facilitate fine-grained local feature alignment by dynamically updating and matching the grasp prototypes from the simulation and real-world scenarios throughout the training process. Due to such designs, the proposed method substantially reduces the domain shift and thus leads to consistent performance improvements. Extensive experiments are conducted on the GraspNet-Planar benchmark and physical environment, and superior results are achieved which demonstrate the effectiveness of our method.
Towards Generalizable Referring Image Segmentation via Target Prompt and Visual Coherence
Dec 01, 2023
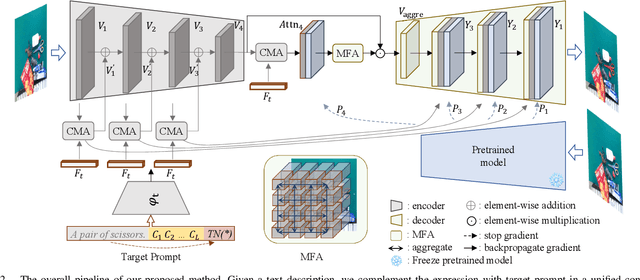
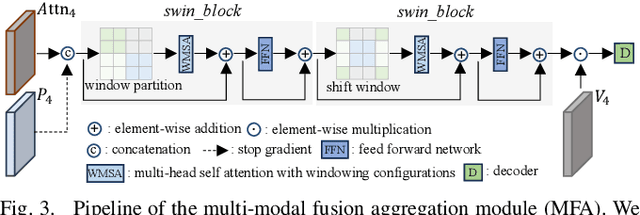

Referring image segmentation (RIS) aims to segment objects in an image conditioning on free-from text descriptions. Despite the overwhelming progress, it still remains challenging for current approaches to perform well on cases with various text expressions or with unseen visual entities, limiting its further application. In this paper, we present a novel RIS approach, which substantially improves the generalization ability by addressing the two dilemmas mentioned above. Specially, to deal with unconstrained texts, we propose to boost a given expression with an explicit and crucial prompt, which complements the expression in a unified context, facilitating target capturing in the presence of linguistic style changes. Furthermore, we introduce a multi-modal fusion aggregation module with visual guidance from a powerful pretrained model to leverage spatial relations and pixel coherences to handle the incomplete target masks and false positive irregular clumps which often appear on unseen visual entities. Extensive experiments are conducted in the zero-shot cross-dataset settings and the proposed approach achieves consistent gains compared to the state-of-the-art, e.g., 4.15\%, 5.45\%, and 4.64\% mIoU increase on RefCOCO, RefCOCO+ and ReferIt respectively, demonstrating its effectiveness. Additionally, the results on GraspNet-RIS show that our approach also generalizes well to new scenarios with large domain shifts.
Covert Planning against Imperfect Observers
Nov 01, 2023



Covert planning refers to a class of constrained planning problems where an agent aims to accomplish a task with minimal information leaked to a passive observer to avoid detection. However, existing methods of covert planning often consider deterministic environments or do not exploit the observer's imperfect information. This paper studies how covert planning can leverage the coupling of stochastic dynamics and the observer's imperfect observation to achieve optimal task performance without being detected. Specifically, we employ a Markov decision process to model the interaction between the agent and its stochastic environment, and a partial observation function to capture the leaked information to a passive observer. Assuming the observer employs hypothesis testing to detect if the observation deviates from a nominal policy, the covert planning agent aims to maximize the total discounted reward while keeping the probability of being detected as an adversary below a given threshold. We prove that finite-memory policies are more powerful than Markovian policies in covert planning. Then, we develop a primal-dual proximal policy gradient method with a two-time-scale update to compute a (locally) optimal covert policy. We demonstrate the effectiveness of our methods using a stochastic gridworld example. Our experimental results illustrate that the proposed method computes a policy that maximizes the adversary's expected reward without violating the detection constraint, and empirically demonstrates how the environmental noises can influence the performance of the covert policies.
RGB-D Grasp Detection via Depth Guided Learning with Cross-modal Attention
Feb 28, 2023



Planar grasp detection is one of the most fundamental tasks to robotic manipulation, and the recent progress of consumer-grade RGB-D sensors enables delivering more comprehensive features from both the texture and shape modalities. However, depth maps are generally of a relatively lower quality with much stronger noise compared to RGB images, making it challenging to acquire grasp depth and fuse multi-modal clues. To address the two issues, this paper proposes a novel learning based approach to RGB-D grasp detection, namely Depth Guided Cross-modal Attention Network (DGCAN). To better leverage the geometry information recorded in the depth channel, a complete 6-dimensional rectangle representation is adopted with the grasp depth dedicatedly considered in addition to those defined in the common 5-dimensional one. The prediction of the extra grasp depth substantially strengthens feature learning, thereby leading to more accurate results. Moreover, to reduce the negative impact caused by the discrepancy of data quality in two modalities, a Local Cross-modal Attention (LCA) module is designed, where the depth features are refined according to cross-modal relations and concatenated to the RGB ones for more sufficient fusion. Extensive simulation and physical evaluations are conducted and the experimental results highlight the superiority of the proposed approach.
Towards Scale Balanced 6-DoF Grasp Detection in Cluttered Scenes
Dec 10, 2022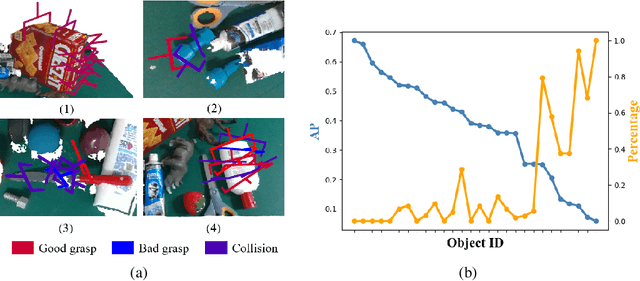
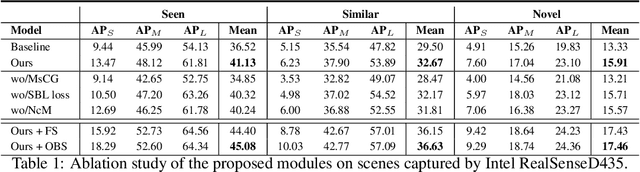
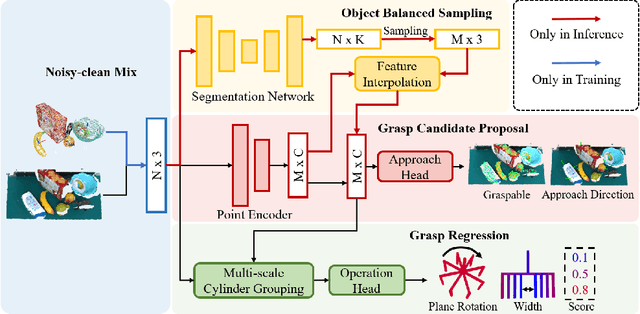

In this paper, we focus on the problem of feature learning in the presence of scale imbalance for 6-DoF grasp detection and propose a novel approach to especially address the difficulty in dealing with small-scale samples. A Multi-scale Cylinder Grouping (MsCG) module is presented to enhance local geometry representation by combining multi-scale cylinder features and global context. Moreover, a Scale Balanced Learning (SBL) loss and an Object Balanced Sampling (OBS) strategy are designed, where SBL enlarges the gradients of the samples whose scales are in low frequency by apriori weights while OBS captures more points on small-scale objects with the help of an auxiliary segmentation network. They alleviate the influence of the uneven distribution of grasp scales in training and inference respectively. In addition, Noisy-clean Mix (NcM) data augmentation is introduced to facilitate training, aiming to bridge the domain gap between synthetic and raw scenes in an efficient way by generating more data which mix them into single ones at instance-level. Extensive experiments are conducted on the GraspNet-1Billion benchmark and competitive results are reached with significant gains on small-scale cases. Besides, the performance of real-world grasping highlights its generalization ability. Our code is available at https://github.com/mahaoxiang822/Scale-Balanced-Grasp.
Boundary Guided Context Aggregation for Semantic Segmentation
Oct 27, 2021

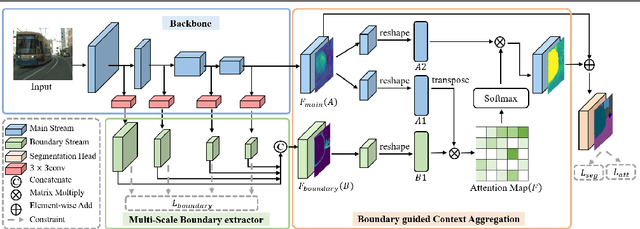

The recent studies on semantic segmentation are starting to notice the significance of the boundary information, where most approaches see boundaries as the supplement of semantic details. However, simply combing boundaries and the mainstream features cannot ensure a holistic improvement of semantics modeling. In contrast to the previous studies, we exploit boundary as a significant guidance for context aggregation to promote the overall semantic understanding of an image. To this end, we propose a Boundary guided Context Aggregation Network (BCANet), where a Multi-Scale Boundary extractor (MSB) borrowing the backbone features at multiple scales is specifically designed for accurate boundary detection. Based on which, a Boundary guided Context Aggregation module (BCA) improved from Non-local network is further proposed to capture long-range dependencies between the pixels in the boundary regions and the ones inside the objects. By aggregating the context information along the boundaries, the inner pixels of the same category achieve mutual gains and therefore the intra-class consistency is enhanced. We conduct extensive experiments on the Cityscapes and ADE20K databases, and comparable results are achieved with the state-of-the-art methods, clearly demonstrating the effectiveness of the proposed one.